Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
“La quiebra no siempre ocurre, pero cuando llega, afectará a un país ya sea económicamente o socialmente” (Kristanti y Herwany, 2017, p.26). La economía se basa en el buen funcionamiento de las empresas (Gregova y otros, 2020), es por esto que analizar y proponer indicadores de cierre se convierte en una importante herramienta para la toma de decisiones de los propietarios y otros grupos de interés; el objetivo principal sería crear sistemas de alerta temprana. Cabe mencionar que en la literatura se encuentran otros términos relacionados al fracaso, como son: cierre, bancarrota o insolvencia empresarial.
El estudio de fracaso empresarial ha evolucionado debido principalmente a la introducción de nuevas herramientas estadísticas que permiten estudiar y predecir más eficazmente acontecimientos futuros, en donde se busca mejorar la eficacia en el análisis de este riesgo, no solamente para predecir el cierre de una empresa, sino también para identificar posibles causas de esta problemática.
Para predecir dificultades financieras se han utilizado diferentes modelos de quiebra, esta predicción se ha vuelto un aspecto relevante para el gobierno corporativo (Siekelova y otros, 2018). Las metodologías utilizadas con más frecuencia para evaluar el fracaso empresarial han sido el análisis discriminante y modelos binomiales como logit y probit (Tascón y otros, 2018). La literatura internacional abarca principalmente el desarrollo de modelos que se adaptan a la realidad de países desarrollados. Es así que, Altman y otros (1995) elaboraron el Emerging Market Scoring Model (EMS Model), el cual es una versión del modelo Z-score de Altman (1968) diseñado para empresas estadounidenses; este modelo ajustado incorporó las características crediticias particulares de las empresas de los mercados emergentes. También en el ámbito regional se destacan los trabajos de análisis de fracaso empresarial de Altman y otros (1979) en Brasil, Swanson y Tybout (1988) en Argentina, Pascale (1988) en las industrias manufactureras uruguayas. En Ecuador, Bermeo y Armijos (2021) aplicaron el modelo Z2 de Altman en la predicción de quiebra en las empresas de construcción de edificios en la provincia de Azuay.
En base a lo mencionado, el objetivo de la presente investigación es predecir la probabilidad de quiebra en las empresas pertenecientes al sector de fabricación de otros productos minerales no metálicos del Ecuador, por medio de los modelos propuestos logit y probit. Según el Banco Central del Ecuador (2020), a pesar que el aporte de este sector en la economía nacional es marginal, está relacionado con la construcción ya que genera bienes que son insumos para su actividad.
Revisión de literatura
De acuerdo a Castro y otros (2019), la bancarrota es el resultado de un estado crítico, en donde los pasivos de una empresa exceden al valor de sus activos; esto es consecuencia de factores como la mala gestión administrativa, circunstancias macroeconómicas, iliquidez, entre otros. Para Sansores y otros (2020) la mortandad de empresas ha sido concebida como el fracaso en la gestión de los recursos por parte de los gerentes y/o propietarios. Los estudios del fracaso empresarial han evolucionado, principalmente por la aparición de nuevas herramientas estadísticas, en donde se destacan las siguientes etapas:
Análisis descriptivo del fracaso empresarial
En esta etapa las investigaciones se limitaban a describir las características de las empresas clasificadas como sanas y en bancarrota en función del uso de ratios financieros; sin embargo, esta tendencia carece de valor predictivo (Mares, 2001; Orellana y otros, 2020). Si la tendencia de los ratios (liquidez, endeudamiento, actividad y rentabilidad) eran desfavorables, la probabilidad de quiebra era más alta. Se destacan los trabajos de FitzPatrick (1932), quien inicialmente analizó el fracaso empresarial a través de estados financieros, además de otros investigadores como Smith y Winakor (1935), Merwin (1942), Jackendoff (1962) y Horrigan (1965).
Análisis predictivo del fracaso empresarial
Beaver (1966) propuso un análisis univariado para predecir la bancarrota. Posteriormente Altman (1968) introdujo el análisis discriminante múltiple (ADM) en esta área, encontrando diferencias significativas entre las empresas quebradas y las no quebradas. Martin (1977) aplicó por primera vez la regresión logística a la construcción de alertas tempranas de quiebra bancaria. El autor extrajo como variables independientes un conjunto de 25 razones financieras de la base de datos nacional mantenida por el Banco de la Reserva Federal de Nueva York; estas variables pueden clasificarse en cuatro grandes grupos: riesgo de activos, liquidez, adecuación de capital y utilidades. En la etapa predictiva, Ohlson (1980) es considerado como pionero en el área económica en la aplicación del método de estimación de máxima verosimilitud, denominado logit condicional, basado en dos artículos inéditos no publicados: White y Turnbull, (1975a, 1975b) y un artículo de Santomero y Vinso (1977) que, según el autor, son los primeros estudios que desarrollaron lógica y sistemáticamente estimaciones probabilísticas de fracaso. El autor utilizó un conjunto de datos del periodo 1970-1976, que fueron obtenidos de los “estados financieros 10-K”, base de datos que permite verificar si la empresa entró en quiebra antes o después de la fecha de publicación.
Los principales hallazgos de Ohlson (1980) se resumen de la siguiente manera: los factores estadísticos que afectaron las probabilidades de bancarrota fueron el tamaño de la compañía, estructura financiera, medidas de desempeño y medidas de liquidez; y, los estudios previos parecen haber exagerado el poder predictivo de los modelos desarrollados y probados. El autor eligió la metodología econométrica del análisis logit condicional para evitar problemas asociados con el análisis discriminante multivariante (MDA), como son:
Requisitos estadísticos impuestos a las propiedades de distribución de los predictores. Por ejemplo, las matrices de varianza-covarianza de los predictores deben ser las mismas para ambos grupos (empresas fallidas y no fallidas). Además, un requisito de predictores distribuidos normalmente mitiga ciertamente el uso de variables independientes ficticias.
El resultado de la aplicación de un modelo MDA es una puntuación que tiene poca interpretación intuitiva, ya que es básicamente un dispositivo de clasificación ordinal (discriminatorio).
También existen ciertos problemas relacionados con los procedimientos de "emparejamiento" que se han utilizado típicamente en MDA. Las empresas que fracasan y las que no fracasan se combinan de acuerdo con criterios como el tamaño y la industria, y estos tienden a ser algo arbitrarios.
También se destaca en esta etapa a Zmijweski (1984), quien desarrolló una nueva fórmula a través de un modelo probit, y la exactitud de este modelo con los datos de su muestra fue del 99%. Entre los estudios más recientes se destacan Karminsky y Burekhin (2019), quienes compararon las capacidades de los modelos logit y probit, árboles de clasificación, bosques aleatorios y redes neuronales artificiales para predecir la quiebra de empresas de la industria de la construcción de Rusia en un horizonte de un año. Pacheco y otros (2019) analizaron las variables financieras y no financieras estadísticamente relevantes para la predicción de la quiebra de las empresas del sector de la construcción civil en Portugal por medio de los modelos predictivos de quiebra logit y probit.
Kovacova y Kliestik (2017) realizaron un estudio empírico de la literatura relevante sobre la aplicación de métodos estadísticos matemáticos para la predicción de la quiebra de empresas eslovacas y proporcionar la comparación de la capacidad de predicción general de los modelos logit y probit durante al año 2015. Kitowski y otros (2022) analizaron la eficacia de predicción de fracaso de los modelos logit y discriminante que permitieron la evaluación del riesgo de quiebra en las empresas polacas susceptibles un año antes de su declaración de quiebra. En el ámbito regional, Gutiérrez (2019) realizó una investigación sobre la capacidad en el pronóstico del fracaso empresarial de los modelos de elección binaria para las Pymes en Colombia. Cruz y otros (2017) analizaron los modelos Poisson y Logístico en la asignación de probabilidades de incumplimiento a empresas mineras mexicanas. En el ámbito ecuatoriano, Cueva y otros (2017) analizaron la fragilidad financiera de las empresas a través de la estimación de los modelos probabilísticos logit y probit utilizando información de los balances financieros de 34.575 empresas tanto grandes, medianas, pequeñas y microempresas que han sido controladas por la Superintendencia de Compañías en el año 2013.
Metodologías basadas en inteligencia artificial
Existen también modelos no paramétricos para predecir el cierre empresarial, como son: redes neuronales artificiales, modelos hazard, modelos difusos, algoritmos genéticos y modelos híbridos, o combinaciones de los modelos anteriores. El uso de la Inteligencia Artificial busca mejorar la predicción de quiebra empresarial que se obtiene a partir de modelos clásicos utilizados anteriormente. Por ejemplo, Lane y otros (1986) introdujeron el uso del análisis de supervivencia para predecir problemas financieros en un sistema bancario; a diferencia del análisis discriminante múltiple, este modelo no contiene supuestos subyacentes, y es una herramienta útil por la capacidad para proporcionar una estimación del tiempo probable de falla; este artículo se centró en el modelo de riesgos proporcionales de Cox (1972). Por otra parte, Zadeh (1965, 1968) describió inicialmente los fundamentos matemáticos asociados a la teoría de conjuntos difusos y la lógica difusa. A pesar que las primeras aplicaciones de la lógica difusa se realizaron en el área de ingeniería de control, al igual que otras metodologías no paramétricas que inicialmente se utilizaron en otras áreas, se las empezaron a utilizar en el análisis de distintos tipos de riesgo financiero. Los resultados obtenidos a partir de estos modelos pretenden demostrar una mejor capacidad predictiva, sin embargo, no todos cumplen esta hipótesis. López y Sanz (2015) desarrollaron un modelo de redes neuronales para estudiar la bancarrota de los bancos estadounidenses, considerando la reciente crisis financiera. Barboza y otros (2017) propusieron elevar el porcentaje de predicción mediante técnicas de aprendizaje automático como vectores de soporte automático, ensacado, refuerzo y bosques aleatorios (support vector machines, bagging, boosting, and random forest). Xue y otros (2018) para evitar el problema de la predicción de series de tiempo financieras, utilizaron la máquina de aprendizaje extrema basada en el mapeo de Fourier aleatorio. Lucanera y otros (2020) por medio de un enfoque de redes neuronales identificaron qué variables relacionadas con la teoría de la estructura de capital predicen el fracaso empresarial en el sector de la construcción español durante la crisis subprime.
Metodología
Información y datos de análisis
Se realizó el análisis según la Clasificación Internacional Industrial Uniforme (CIIU), la cual codifica al sector de fabricación de otros productos minerales no metálicos como “C23” (ver Tabla 1).
Tabla 1 Clasificación del sector de fabricación de otros productos minerales no metálicos Fuente: Superintendencia de Compañías, Valores y Seguros (2020)
| CIIU | Descripción |
| C23 | Fabricación de otros productos minerales no metálicos |
| C231 | Fabricación de vidrio y productos de vidrio |
| C239 | Fabricación de otros productos minerales no metálicos n.c.p. |
La base de datos pasó por un proceso de depuración, en donde se eliminaron las empresas que no contaban con información financiera y aquellas que no presentaban actividad (información en “0 “en el estado de resultados). En total se analizaron 2015 observaciones en el periodo 2009-2019, esto debido a la disponibilidad de información en el momento del inicio de la investigación. En la Tabla 2 se clasificaron las empresas activas y no activas; se consideraron no activas las que tuvieron la siguiente situación legal: cancelación o proceso de cancelación, disolución o proceso de disolución, inactivas y en liquidación.
Tabla 2 Número de empresas del sector de fabricación de otros productos minerales no metálicos Fuente: Superintendencia de Compañías, Valores y Seguros (2020)
| Año | Activas | No activas | Total |
| 2009 | 117 | 62 | 179 |
| 2010 | 122 | 58 | 180 |
| 2011 | 143 | 53 | 196 |
| 2012 | 152 | 42 | 194 |
| 2013 | 159 | 37 | 196 |
| 2014 | 169 | 35 | 204 |
| 2015 | 176 | 37 | 213 |
| 2016 | 167 | 27 | 194 |
| 2017 | 149 | 12 | 161 |
| 2018 | 139 | 8 | 147 |
| 2019 | 145 | 6 | 151 |
| Total | 1638 | 377 | 2015 |
Metodología de cálculo
Los modelos de regresión logística son modelos estadísticos que se utilizan cuando se desea describir la relación existente entre una variable respuesta de tipo categórico y un conjunto de variables explicativas categóricas o continuas. Estos modelos permiten estimar la probabilidad de que un evento ocurra o no, prediciendo un resultado dependiente binario de un conjunto de variables independientes (Balaguer, 2009; Belyaeva, 2014). Ohlson (1980) estimó tres modelos, los cuales están compuestos por una intersección y nueve variables independientes. La descripción de las variables del modelo de Ohlson es la siguiente:
X1 (Tamaño) = Logaritmo (activos totales / índice del nivel de precios).
X2 = Pasivos Totales / Activos Totales.
X3 = Capital de Trabajo / Activos Totales.
X4 = Pasivo corriente / Activo corriente.
X5 = Dummy de solvencia: uno si los pasivos totales exceden los activos totales, cero en caso contrario.
X6 = Utilidad neta / Activos Totales.
X7 = Resultado operacional / Total de las obligaciones.
X8 = Dummy de rentabilidad: uno si el ingreso neto fue negativo durante los últimos dos años, cero en caso contrario.
X9 = Ingreso Neto t - Ingreso Neto t-1/| Ingreso Netot|+ | Ingreso Netot-1|.
El modelo 1 predice la bancarrota dentro de un año; el modelo 2 predice la bancarrota dentro de dos años, dado que la compañía no fracasó en el año siguiente; y, el modelo 3 predice la bancarrota en uno o dos años. Los modelos 2 y 3 tienen estadísticas de bondad de ajuste algo más débiles. El modelo 1 presenta mejores resultados, ya que clasifica correctamente 96,12% de las empresas.
Ohlson (1980) sugirió que el coeficiente de las variables X 1 , X 3 , X 6 , X 7 y X 9 es negativo. La variable X1 hace referencia al tamaño, es decir que a medida que se incrementa el tamaño de la empresa se reduce el riesgo de bancarrota. Además, un mayor capital de trabajo y utilidad neta (frente a los activos totales, X 3 y X 6 ) de igual forma reducen el riesgo. En este grupo de indicadores también está la variable X 7 , la cual indica que una mayor utilidad operativa o menor nivel de deuda total disminuye el riesgo. Finalmente se encuentra la variable X 9 , variable que mide el cambio en la utilidad neta.
Por otra parte, el signo de las variables X 2 , X 4 y X 8 es positivo. En el caso de la variable X 2 , un mayor nivel de deuda frente a activos totales aumenta el riesgo de bancarrota. La variable X 4 de igual manera compara la deuda y activos, pero a nivel operativo, y al ser mayor este ratio se incrementa el riesgo. La variable X 8 es categórica, y evidentemente si el valor es positivo (1), existirá mayor riesgo de bancarrota. La variable X 5 el autor la consideró indeterminada. Esta variable sirve como corrección de discontinuidad para la variable X 2 .
Si se tiene un conjunto de variables independientes (
(4)
Y será igual a:
(5)
Es decir:
(6)
El resultado final obtenido del modelo está representado en términos de probabilidad. De acuerdo a Belyaeva (2014), en el caso del modelo 1, los resultados superiores a 0,5 pueden definir si una empresa quebrará dentro de dos años. Si se utiliza O como resultado del modelo:
(7)
Teniendo como base el modelo de Ohlson (1980), se propusieron en este trabajo los modelos econométricos Logit y Probit. Gujarati y Porter (2010) aseveraron que el modelo logit utiliza la función logística acumulativa, y el modelo de estimación que surge de una función de distribución acumulativa (FDA) normal se conoce comúnmente como modelo probit.
La variable dependiente del modelo se clasificó de la siguiente manera:
1 = Empresas en riesgo de insolvencia.
0 = Empresas que no se encuentran en riesgo de insolvencia.
Al no disponer de información sobre las empresas quebradas, el criterio que más se ajustó a los requerimientos de las empresas con alto riesgo de insolvencia son las que presentaron un patrimonio negativo y pérdida (ver Figura 1). Este supuesto se basó en lo que menciona la Superintendencia de Compañías, Valores y Seguros (2016): entre las principales causas de disolución que estipula la Ley de Compañías se encuentra la pérdida de 50% o más del capital social (compañías de responsabilidad limitada, anónimas, en comandita por acciones y de economía mixta).

Figura 1 Fuente: Superintendencia de Compañías, Valores y Seguros (2016) Empresas clasificadas como cerradas y activas
Modelo Logit
Pece y otros (2012) indicó que el modelo de regresión logística binaria se expresa mediante el siguiente modelo lineal:
(8)
Donde:
Las variables
Los coeficientes del modelo
Modelo Probit
En el caso del modelo probit, el hecho de que una empresa esté en quiebra o no depende de un índice de conveniencia no observable o variable latente
(9)
Si
Entonces, si:
Si la función de distribución de la normal F(x) es:
(10)
En este caso:
(11)
(12)
A partir de los modelos se obtuvo la probabilidad de fracaso de las empresas del sector C 23. Se pretende estimar la probabilidad de que ocurra un suceso en función de la dependencia de otras variables.
Resultados
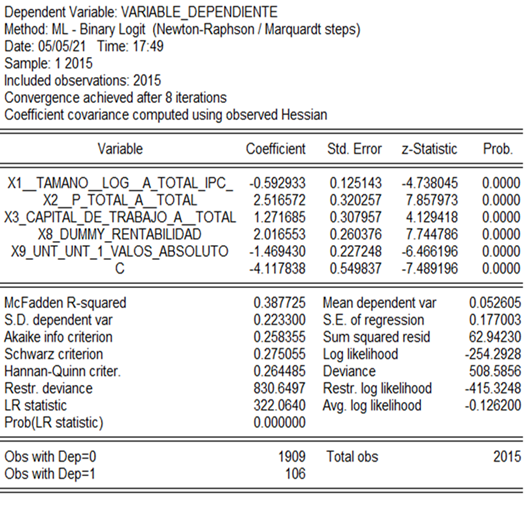
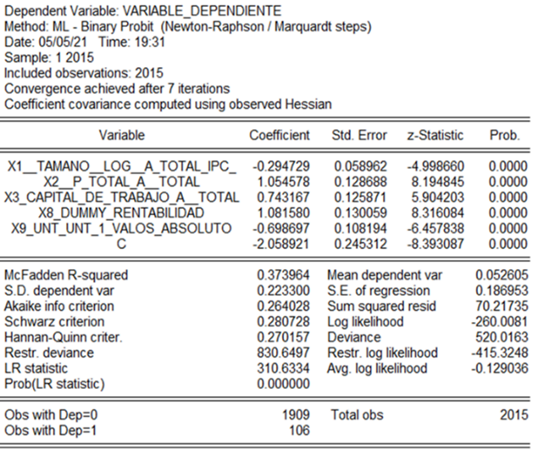
En las Figuras 2 y 3 se presentan los modelos logit y probit, una vez aplicados los criterios mencionados en la metodología. Resultaron estadísticamente significativas las siguientes variables: tamaño empresarial (X1), el ratio pasivo total/activo total (X2), capital de trabajo/activo total (X3), la dummy de rentabilidad (X8) y la variable X9.
La función de distribución logística sería:
(13)
La función de distribución normal sería:
En la Tabla 3 se analizaron los coeficientes de los modelos clásicos, logit y probit. Las variables X1, X2, X8 y X9 poseen los mismos signos (la interpretación ya se mencionó anteriormente). Sin embargo, la variable X3 discrepa con la metodología clásica, ya que tiene signo positivo, pues Altman utilizó para su cálculo los datos de empresas cerradas, a diferencia del presente estudio en el cual se utilizó el total de la data de las empresas del sector.
Tabla 3 Análisis de coeficientes de los modelos Fuente: Elaboración propia
| Variable | Descripción | Metodología | ||
| Clásica | Logit | Probit | ||
| X1 | Tamaño | -0,407 | -0,593 | -0,295 |
| X2 | Pasivo total / Activo total | 6,03 | 2,517 | 1,055 |
| X3 | Capital de trabajo / Activo total | -1,43 | 1,272 | 0,743 |
| X4 | Pasivo corriente / Activo corriente | No significativa | ||
| X5 | Dummy de solvencia | No significativa | ||
| X6 | Utilidad neta/ Activos Totales | No significativa | ||
| X7 | Resultado operacional / Total de las obligaciones | No significativa | ||
| X8 | Dummy de rentabilidad | 0,285 | 2,017 | 1,082 |
| X9 | Ingreso Neto t - Ingreso Neto t-1/| Ingreso Neto t|+ | Ingreso Netot-1| | -0,521 | -1,469 | -0,699 |
| Constante | -1,32 | -4,1178 | -2,059 | |
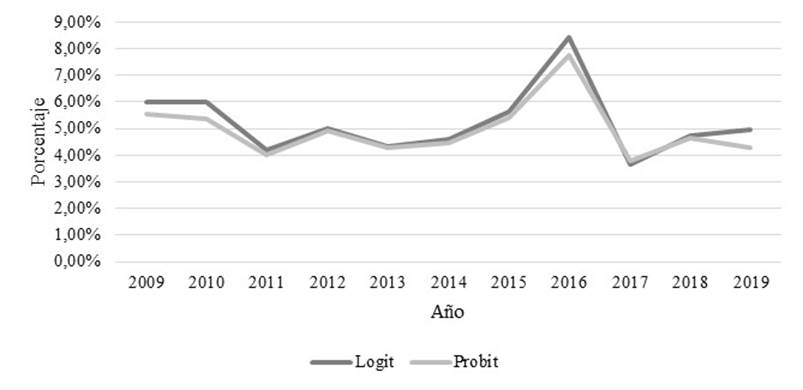
En la Figura 4 se presentan los niveles de riesgo en las metodologías logit y probit, en donde se observa que se mantienen los mismos niveles (ligeras diferencias) y tendencia; se destaca que el año 2016 fue el más riesgoso. Los niveles de riesgo se encontraron entre 3,67% y 8,42% en el modelo logit, y 3,79 y 7,75% en el probit; estos valores fueron inferiores a los que se presentaron al aplicar la metodología clásica de Ohlson. (Ver Anexos 1 y 2).
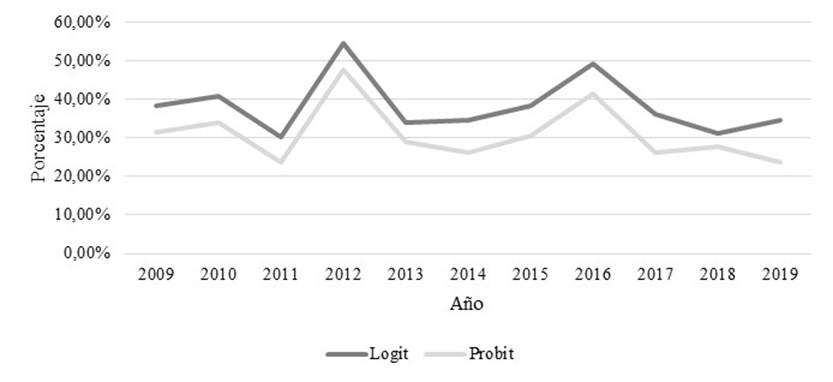
En la Figura 5 se presenta el riesgo de fracaso de las empresas clasificadas como cerradas, (criterios mencionados en la metodología). Se destacó que se mantuvo la misma tendencia en los modelos; además, las empresas cerradas tuvieron valores que oscilaron entre 30,13% y 54,13% en el modelo logit, y de 23,52% y 47,66% en el modelo probit (ver resultados en el Anexo 3).
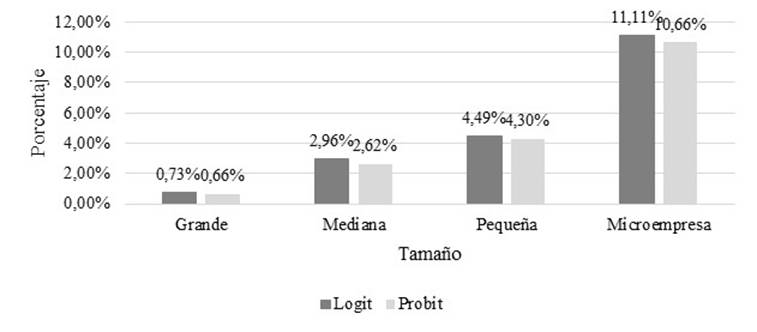
A medida que se incrementa el tamaño empresarial, se reduce el riesgo de fracaso. Esta relación se mantuvo en las dos metodologías (Ver Figura 6).
En la Tabla 4 se muestra la probabilidad de fracaso en los dos subsectores que son parte del sector analizado. En las metodologías alternativas el subsector C239 fue más riesgoso. Cabe destacar, que no existieron diferencias significativas.
Tabla 4 Probabilidad de fracaso en los subsectores C231 y C239 Fuente: Elaboración propi
| Año | C231 | C239 | ||
| Logit | Probit | Logit | Probit | |
| 2009 | 8,10% | 7,60% | 5,50% | 5,06% |
| 2010 | 5,81% | 5,15% | 6,02% | 5,40% |
| 2011 | 4,14% | 4,28% | 4,22% | 3,94% |
| 2012 | 5,17% | 5,29% | 4,98% | 4,85% |
| 2013 | 3,31% | 3,48% | 4,57% | 4,46% |
| 2014 | 8,06% | 7,53% | 3,89% | 3,87% |
| 2015 | 4,40% | 3,80% | 5,87% | 5,74% |
| 2016 | 4,19% | 4,28% | 9,26% | 8,44% |
| 2017 | 2,51% | 2,77% | 3,90% | 3,98% |
| 2018 | 4,64% | 4,49% | 4,75% | 4,67% |
| 2019 | 6,04% | 4,05% | 4,76% | 4,31% |
| Promedio | 5,17% | 4,88% | 5,28% | 5,01% |
Al analizar las provincias con mayor concentración de empresas del sector, se observó que Pichincha tuvo valores más altos en los modelos propuestos (Logit = 6,54% y Probit = 5,91%), seguido de Azuay (Logit = 5,85% y Probit = 5,75%); Guayas tuvo empresas con una menor probabilidad de fracaso (Logit = 3,59 % y Probit = 3,56%) (Ver Tabla 5).
Tabla 5 Riesgo de insolvencia provincial Fuente: Elaboración propia
| Año | Azuay | Guayas | Pichincha | |||
| Logit | Probit | Logit | Probit | Logit | Probit | |
| 2009 | 11,19% | 10,15% | 3,47% | 3,60% | 7,15% | 6,37% |
| 2010 | 2,67% | 2,57% | 2,59% | 2,69% | 9,91% | 9,04% |
| 2011 | 3,04% | 3,13% | 2,41% | 2,46% | 6,84% | 6,14% |
| 2012 | 4,34% | 4,41% | 2,96% | 3,30% | 7,37% | 6,61% |
| 2013 | 7,49% | 7,74% | 2,70% | 2,74% | 2,71% | 2,69% |
| 2014 | 4,31% | 4,59% | 3,90% | 3,72% | 4,56% | 4,49% |
| 2015 | 7,03% | 6,72% | 4,51% | 4,35% | 6,78% | 6,48% |
| 2016 | 12,64% | 11,84% | 8,14% | 7,26% | 6,61% | 6,06% |
| 2017 | 3,04% | 3,60% | 1,62% | 1,77% | 6,43% | 6,14% |
| 2018 | 3,92% | 3,75% | 3,73% | 3,74% | 5,64% | 5,29% |
| 2019 | 2,72% | 2,82% | 2,42% | 2,71% | 7,79% | 5,24% |
| Promedio | 5,85% | 5,75% | 3,59% | 3,56% | 6,54% | 5,91% |
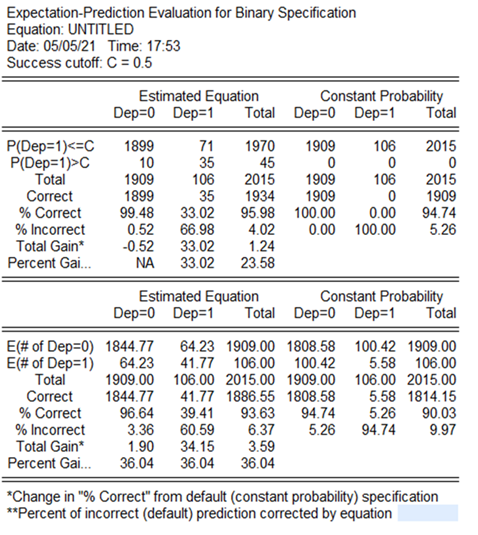
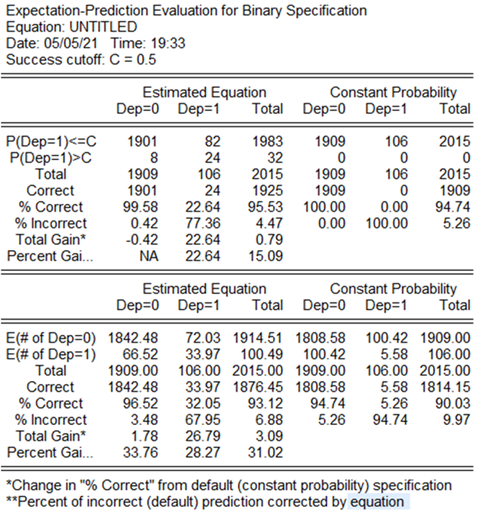
Es importante mencionar cómo está la capacidad predictiva de los modelos estimados (Anexo 4), pero antes es necesario conocer que el punto de corte planteado para categorizar a las empresas insolventes de las solventes es del 0,50, es decir, que a todas las predicciones por arriba de una probabilidad de 0,50 son insolventes mientras que todas las que estén por debajo de 0,50 serán empresas solventes. Aunque no hay un criterio claro para definir este punto de corte, autores como Camm y otros (2019) señalan que ante ausencia de esta información una forma adecuada es colocar el 0,50 como punto de corte para clasificar los resultados.
En general el modelo Logit estimado predijo un 95,98% de las observaciones (99,48% con las empresas que no quiebran y un 33,02% en las empresas que quebraron), mientras que el modelo Probit en 95,53% en su conjunto (predice correctamente en el 99,58% de las veces empresas que no quiebran y un 22,64% a las que quebraron.
La pregunta que surge es: ¿Qué pasaría si se mueve el punto de corte para separar a las empresas quebradas de las no quebradas? A continuación, se presentan los posibles resultados de la capacidad predictora del modelo tanto para Logit como para Probit:
Tabla 6 Capacidad predictora del modelo Logit. Fuente: Elaboración propia
| Punto de corte | % de Correctos (dep=1) | % de Correctos (dep=0) | % de predicción total |
| 0,50 | 33,02 | 99,48 | 95,98 |
| 0,40 | 37,74 | 99,42 | 96,18 |
| 0,30 | 46,23 | 98,8 | 96,03 |
| 0,20 | 58,49 | 97,49 | 95,43 |
| 0,10 | 75,47 | 92,61 | 91,71 |
| 0,05 | 90,57 | 83,71 | 84,07 |
Tabla 7 Capacidad predictora del modelo Probit Fuente: Elaboración propia
| Punto de corte | % de Correctos (dep=1) | % de Correctos (dep=0) | % de predicción total |
| 0,5 | 22,64 | 99,58 | 95,53 |
| 0,4 | 28,3 | 99,58 | 95,83 |
| 0,3 | 36,79 | 98,9 | 95,63 |
| 0,2 | 52,83 | 97,17 | 94,84 |
| 0,1 | 71,7 | 91,99 | 90,92 |
| 0,05 | 87,74 | 81,35 | 81,69 |
Una vez realizados los análisis pertinentes se pudo ver que, al utilizar un punto de corte del 0,40, en ambos modelos su capacidad predictora global aumentó, aunque a medida que baja el valor del punto de corte la posibilidad de obtener falsos positivos o negativos varía.
Conclusiones
La construcción de un modelo de quiebra implica muchos temas que se deben resolver, con el objetivo de predecir el fracaso empresarial las principales preguntas que se pueden hacer son: ¿Cuándo la empresa ha caído en la quiebra? ¿Cuáles son los factores y los signos de fracaso? ¿Cuándo se ve obligada la empresa a cerrar sus actividades? (Kubíčková y Nulíček, 2016). Para Ruiz y otros (2022), las empresas se encuentran en un escenario crítico en donde no solo luchan con la competencia, sino que también se ven afectadas por factores externos como la inflación, aspectos políticos, sociales y culturales, además de un fenómeno epidemiológico (Covid-19). En la investigación se describe la evolución que ha tenido el análisis de insolvencia, pasando desde una etapa descriptiva que se limitó al análisis de ratios financieros como predictores de la salud financiera, hasta pasar a una etapa descriptiva que pretende crear un sistema de alerta temprana para mitigar los efectos del fracaso empresarial. Así también se mencionan técnicas nuevas basadas en inteligencia artificial. Las metodologías nuevas, en teoría, clasifican más efectivamente empresas fracasadas y no fracasadas que los modelos estadísticos paramétricos clásicos, sin embargo, es un tema a debatir. Por ejemplo, en la investigación de Boritz y Kennedy (1995) se descubrió que el rendimiento de las redes neuronales no era superior a las técnicas convencionales como el análisis discriminante de Altman (1968) y logit de Ohlson (1980). Shumway (2001) comparó el desempeño de un modelo de riesgo (hazard model) contra el modelo Altman, y concluyó que el modelo de riesgo tiene mayor capacidad predictiva y precisión que el modelo Altman y que se puede obtener una precisión aún mayor con un conjunto alternativo de variables explicativas. Belyaeva (2014) indica que el modelo O-Score se obtuvo después de evaluar más de 2000 empresas, en comparación con Altman Z-Score, donde fueron 66 empresas, por lo que concluye que el O-Score es más preciso para predecir el fracaso en un plazo de 2 años.
Al tener en cuenta el análisis logit propuesto por Ohlson (1980), en los tres modelos desarrollados, el tamaño aparece como un predictor importante. Por otra parte, Castro y otros (2019) asevera que uno de los principales determinantes para el incumplimiento de obligaciones es la deuda. Otros factores a considerar son la información y localización de la investigación. De acuerdo a Gregova y otros (2020), los resultados de muchas investigaciones confirman que la fiabilidad y la precisión predictiva de los modelos disminuyen si se utilizan en diferentes entornos nacionales y horizontes de tiempo que aquellos en los que se formaron originalmente. Bajo este escenario, se puede concluir que no existe un modelo o metodología perfecta para analizar y predecir el fracaso empresarial, sino más bien se deben adaptar estos modelos a las circunstancias e información que se dispone.
En esta investigación se proponen dos metodologías: logit y probit. De acuerdo a Belyaeva (2014), en el modelo logit Z sigue una distribución logística, y en el modelo probit Z sigue una distribución normal estándar; se comportan de manera similar, excepto que la distribución logística tiende a tener cola ligeramente más plana. Para definir la variable dependiente de los modelos para el caso ecuatoriano, al no disponer de información de empresas quebradas se utilizaron los supuestos de pérdida y patrimonio negativo para la clasificación; cabe mencionar que Ohlson (1980) utilizó para sus cálculos una muestra final de 105 empresas en quiebra y 2058 empresas no quebradas. El resultado final del modelo indica la probabilidad que tienen las empresas del sector de fabricación de otros productos minerales no metálicos del Ecuador de fracasar o caer en bancarrota. Se debe indicar que los coeficientes estimados en los modelos logit y probit no son comparables.
En el análisis de los resultados de los dos modelos, se destaca que la mayor probabilidad de riesgo de quiebra se da en el año 2016: logit = 8,42%, y probit = 7,75%. Si se comparan estos valores con el modelo clásico de Ohlson (ver Anexo 1), los valores se incrementan considerablemente (valores superiores al 53,58% en todo el periodo); esta diferencia se debe a que en los modelos propuestos no intervienen las nueve variables del modelo de Ohlson. Otro factor a analizar es el resultado general o promedio, ya que, al desagregar los resultados, las empresas clasificadas como cerradas presentan valores superiores al promedio general: 30,13% (logit) y 23,52% (probit); sin embargo, al existir una mayor cantidad de empresas activas en el análisis (ver Figura 1), el valor medio tiende a bajar, afectando de esta manera al promedio general que se mencionó anteriormente. Cabe indicar que el modelo logit presenta una mayor capacidad predictiva (95,98%) que el modelo probit (95,53%) (Ver Anexos 4 y 5). Además, el valor de corte o punto discriminatorio entre empresas quebradas y no quebradas es de 50%, esto de acuerdo a Camm y otros (2019).
Se analizó también la probabilidad de fracaso por tamaño empresarial, considerando que es una de las variables que incluye Ohlson (2010) dentro de su modelo e indicando que las empresas grandes son menos riesgosas; bajo este escenario, Kuběnka y Myšková (2019) aseveraron que los indicadores más importantes de predicción de quiebras pueden describirse como indicadores de tamaño de la empresa, utilizando el valor de las ventas y el total activos. En el análisis provincial, Guayas presentó los niveles más bajos de riesgo, seguida de Azuay y Pichincha.
Los modelos de regresión logística son muy populares para analizar el fracaso empresarial. En el caso de la utilización de modelos logísticos, estos evitan problemas asociados al análisis discriminante multivariante (MDA), tal como se menciona en la investigación. Además, este modelo, si se compara con modelos que utilizan inteligencia artificial, presenta resultados favorables. Aquí, es importante analizar la información disponible y el lugar en donde se realiza el estudio, ya que estos factores son críticos y pueden influir en los resultados obtenidos. En el caso de los modelos propuestos, estos fueron obtenidos a partir de información financiera de empresas ecuatorianas, obteniéndose de esta manera las variables estadísticamente significativas que son parte de los modelos logit y probit que predicen la probabilidad de fracaso empresarial, esto, bajo un contexto o escenario más acorde al de la situación del país, considerando que el modelo original se lo elaboró bajo un contexto de países desarrollados.
Contribución de autores
L.B.T.O. Revisión de literatura, metodología, análisis de datos, discusión y conclusiones, y revisión de redacción.
I.F.O.O. Metodología, análisis de datos, discusión y conclusiones, y revisión de redacción.
L.G.P.L. Metodología, análisis de datos, discusión y conclusiones, y revisión de redacción.
M.A.R.C. Metodología, análisis de datos, discusión y conclusiones, y revisión de redacción.