











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
Forma sugerida de citación:
Matute-Pinos, K. y Bojorque-Chasi, R. (2021). «Apoyo a los subsistemas de talento humano, selección y reclutamiento a partir de un sistema experto. Caso de estudio». Ingenius. N.◦ 26, (julio-diciembre). pp. 41-48. doi: https://doi.org/10.17163/ings.n26.2021.04
1. Introducción
En los últimos años distintos organismos y Gobiernos han considerado como punto importante en su gestión el mejorar la calidad de vida de las personas con discapacidad, tal es el ejemplo del Gobierno de Ecuador que dentro de su Plan de Desarrollo señala como una de sus metas «Aumentar el número de personas con discapacidad y/o sustitutos insertados en el sistema laboral a 2021» [1] y es así que apoyado en la Constitución vigente, Código de Trabajo y Ley Orgánica de Discapacidades se ha logrado una integración que contribuye a la inclusión de personas con discapacidad en la sociedad. En el ámbito laboral se han creado paulatinamente mecanismos de selección en dónde se han adecuado los procesos permitiendo así la participación de personas con discapacidad procurando la equidad de género y la diversidad de discapacidad [2].
Los datos de recursos humanos proporcionan una fuente valiosa de información para el descubrimiento de conocimiento y el desarrollo de sistemas de ayuda a la toma de decisiones al momento de reclutar al personal. Hoy en día, las organizaciones tienen que luchar eficazmente en términos de costo, calidad, servicio e innovación.
El éxito de estas tareas depende de disponer de suficientes personas adecuadas con las habilidades adecuadas, desplegadas en los lugares apropiados en el momento adecuado, lo que se conoce como gestión del talento humano. Gestionar el talento de una organización se ha convertido en un desafío para los profesionales de recursos humanos, esta tarea implica muchas decisiones administrativas para elegir a la persona correcta para el trabajo correcto en el momento correcto.
A veces, este tipo de decisiones son muy inciertas y difíciles; y depende de varios factores, como la experiencia humana, el conocimiento, la preferencia y el juicio [3]. El talento se considera la capacidad de cualquier individuo para marcar una diferencia significativa en el desempeño actual y futuro de la organización [4].
El reclutamiento se dificulta cuando se analiza el proceso de inclusión laboral a personas con discapacidad. Según la Organización Mundial de la Salud (OMS) actualmente en los países en desarrollo entre el 90 % y 80 % de las personas con discapacidad en edad para trabajar están desempleadas, en los países industrializados la estimación es entre 50 % y 70 %.
Las barreras para la entrada al mercado laboral de las personas con discapacidad varían según el tipo de discapacidad, por lo que, en el proceso de inserción laboral de una persona con discapacidad, se requiere tomar medidas que garanticen el acceso y la permanencia de esta persona en su lugar de trabajo, respetando su individualidad y su tipo de discapacidad [5]. Cuando un candidato cumpla con el perfil adecuado para un cargo, la empresa debería gestionar y realizar los cambios necesarios al lugar de trabajo, ayudando así a desarrollar las capacidades de esta persona.
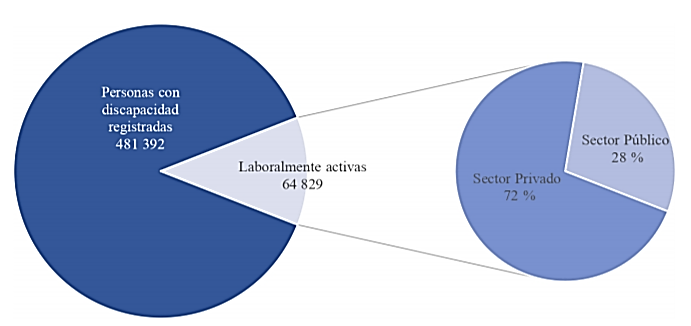
En el Consejo Nacional para la Igualdad de Discapacidades del Ecuador se encuentran registradas [6] a junio del 2020, 481 392 personas con discapacidad de las cuales el 13 % se encuentran laboralmente activas sin considerar sustitutos, de estas el 56,20 % posee discapacidad física, seguida por discapacidad auditiva 17,12 %, discapacidad visual un 14,31 %, discapacidad intelectual 8,88 % y, finalmente, discapacidad psicosocial con un 3,50 %. El sector privado tiene en su nómina a 46 496 personas con discapacidad y el sector público 18 333 personas. Ver Figura 1
Según [7], el proceso de reclutamiento ha mejorado mediante la implementación de tecnologías de información, que permiten simplificar el proceso de publicar vacantes y hojas de vida, enumerar trabajos y ver posibles candidatos. Sin embargo, el proceso de reclutamiento sigue siendo imperfecto y el estudio menciona tres razones:
Algunos pasos del proceso de reclutamiento no están automatizados. Como resultado, los reclutadores tienen que procesar una gran cantidad (a veces cientos, o incluso miles) de hojas de vida manualmente para elegir el mejor empleado potencial.
Los reclutadores generalmente no toman en consideración todas las alternativas posibles para el empleado.
Los reclutadores se guían solo por su opinión subjetiva, por lo que no hay garantía de que el candidato elegido sea realmente la mejor opción posible para el empleador.
La contratación y selección de personal afecta directamente la calidad de los empleados. Se han realizado varios estudios sobre currículums, entrevistas, centros de evaluación, pruebas de conocimiento del trabajo, muestra de trabajo, pruebas, pruebas cognitivas y pruebas de personalidad en la gestión de recursos humanos para ayudar a las organizaciones a tomar mejores decisiones de selección de personal. De hecho, los enfoques de selección existentes se centran en las funciones del trabajo y el análisis de tales funciones que se definen a través de actividades y tareas específicas basadas en sus propiedades estáticas [8]. Los procesos mencionados generan una cantidad importante de datos referentes al reclutamiento, el presente estudio pretende aprovechar las técnicas de aprendizaje automático sobre estas bases de datos.
El aprendizaje automático consiste en la aplicación de técnicas de origen estadístico sobre conjuntos de datos para el aprendizaje de patrones ocultos, proyecciones o predicciones de las observaciones, mediante la aplicación de algoritmos se puede extraer información valiosa de los datos de un dominio específico de manera automática [9].
El presente trabajo está organizado de la siguiente manera, en la sección 1.1 se presentan diferentes trabajos relacionados con el área de la inteligencia artificial y su aplicación en la gestión de recursos humanos, cuando se considera oportuno se introducen diferentes conceptos. La sección 2 presenta la metodología de trabajo, detallando las técnicas que se aplicaron. La sección 3 muestra los resultados relevantes que se obtuvieron y, finalmente, la sección 4 expone las conclusiones del presente trabajo.
1.1. Trabajos relacionados
Las organizaciones están comenzando a adoptar y capitalizar la funcionalidad de la inteligencia artificial en sus procesos de reclutamiento [10]. Las aplicaciones de sistemas expertos o sistemas de ayuda a la toma de decisiones para seleccionar personal y el reclutamiento está incrementando [8, 9, 11, 12, 13, 14]. Las organizaciones están comenzando a adoptar y capitalizar la funcionalidad de la inteligencia artificial en sus procesos de reclutamiento [10]. Las aplicaciones de sistemas expertos o sistemas de ayuda a la toma de decisiones para seleccionar personal y el reclutamiento está incrementando [8, 9, 11, 12, 13, 14].
Para la solicitud y selección de trabajo, la inteligencia artificial puede utilizar características conductuales y fisiológicas (por ejemplo, biometría) como parte del proceso general de toma de decisiones [10]. Algunos ejemplos de implementaciones son el uso de herramientas multimedia [15], sistemas de seguimiento de candidatos en línea [16], sistemas de aprendizaje automático [17], sistemas de soporte a la toma de decisiones que ayudan en el proceso completo de categorizar e identificar discapacidades [9], sin embargo, en la actualidad no se está aprovechando la riqueza de la minería de datos.
Hoy en día, existen un sinnúmero de técnicas de inteligencia artificial como la minería de datos, la analítica de datos y el descubrimiento de información en base de datos que, mediante técnicas de aprendizaje automático, proporcionan a las organizaciones tareas de predicción y clasificación, para dar soporte a la toma de decisiones, entre ellas las de gestión del talento humano.
La minería de datos hace referencia a la extracción de patrones o reglas útiles de una extensa fuente de datos, a través de la exploración automática o semiautomática y del análisis de datos [18]. Para este trabajo la aplicación de técnicas de aprendizaje automático constituye el proceso de minería de datos, según la literatura existe el consenso de clasificar las técnicas de aprendizaje automático en técnicas de aprendizaje supervisado, no supervisado y aprendizaje por refuerzo [19].
El presente trabajo se enfoca en la tarea de aplicar técnicas de aprendizaje supervisado como la clasificación y técnicas de aprendizaje no supervisado como el clustering a la base de datos recopilada en el proyecto de inclusión educativa y laboral de personas con discapacidad de la Universidad Politécnica Salesiana.
Las técnicas supervisadas nos permiten clasificar a un candidato con discapacidad para un puesto de trabajo como apto o no. Desde el punto de vista computacional se trata de una tarea de clasificación, sin embargo, la condición de discapacidad sesga los datos a una población muy reducida, en primer lugar, no existen suficientes datos sobre los mismos y la muestra está limitada al dominio de la ciudad de Cuenca-Ecuador.
Clasificar es una tarea de aprendizaje supervisado, donde la clase o el objetivo de clasificación es conocido. Existen varias técnicas usadas para clasificación en minería de datos como árboles de decisión, técnicas bayesianas, lógica difusa, máquinas de soporte vectorial, redes neuronales, algoritmos genéticos y el algoritmo de los vecinos más cercanos. En el presente estudio se aplican varias técnicas para determinar la que mejor se adapta a la información recolectada sobre los candidatos con discapacidad.
El clustering consiste en encontrar patrones ocultos en los datos, agrupamientos naturales que no son perceptibles en el entorno de alta dimensionalidad que presentan los conjuntos de datos modernos [19], en este caso setenta características. Debido a la alta dimensionalidad, el trabajo busca determinar correlaciones entre las distintas características para de esta manera eliminar aquellas que presenten un alto índice de correlación. Asimismo, se probó con técnicas de reducción de dimensionalidad.
Es importante mencionar una línea de investigación con mucha perspectiva de crecimiento en el campo del aprendizaje automático para el apoyo a la gestión de recursos humanos, se trata del procesamiento de lenguaje natural, y como tecnología disruptiva actualmente los chatbots se ocupan de tareas como entrevistas a candidatos, capacitación a personal, atención de clientes y cualquier tarea que requiera comunicación entre personas y un agente inteligente [20]. En el área de reclutamiento de personal es importante mencionar que los chatbots son capaces de manejar una cantidad significativa de información que muchas de las veces los entrevistadores pasan por alto [21].
2. Materiales y métodos
Se utilizó como línea de base el trabajo [22], que consiste en 120 muestras de datos, con 70 características referentes a edad, sexo, nivel de educación, experiencia laboral, dominio de lengua extranjera, tipo de discapacidad y las destrezas transversales de cada candidato. El estudio original utiliza un sistema basado en reglas validado por expertos. Nuestra propuesta incorpora como novedad el aprendizaje a partir del conjunto de datos original para predecir si un candidato es apto o no para un puesto, de esta forma, el sistema mediante técnicas de aprendizaje supervisado no requiere de la validación de expertos.
La dispersión de los datos es la característica más relevante del conjunto de datos, es decir, contamos con una matriz a la cual le falta información, y dicha información no puede ser considerada como 0 en el proceso de análisis puesto que esto podría sesgar los resultados del análisis. La Tabla 1 muestra un resumen de las diferentes características del conjunto de datos.
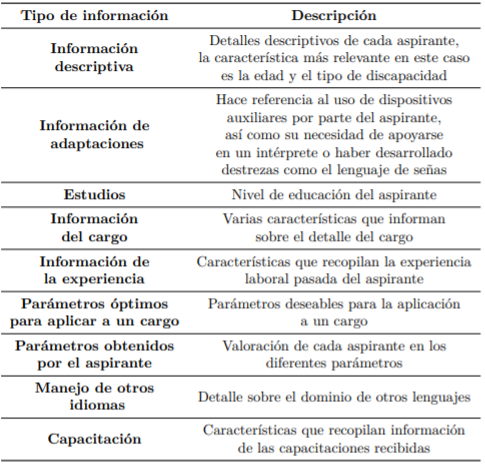
Para el presente trabajo se imputaron los datos y se eliminaron aquellas características que no aportaban suficiente información al sistema, ya sea porque los datos recopilados representaban una cantidad insignificante de la población de estudio o porque la característica presentaba descripciones tipo texto que no aportan información al sistema. Luego de este proceso se cuenta con una matriz completa.
Para validar la eliminación de características se realizó un análisis de similaridades entre el conjunto de datos original, el que contiene los datos dispersos; y el conjunto de datos posterior a la imputación. Se utilizaron diferentes métricas de similaridad según el estudio [23], siendo relevantes para este estudio la similaridad de Pearson y la de Jaccard para el conjunto de datos completo (con características dispersas) y con el conjunto de datos modificado se consideró únicamente la similaridad de Pearson.
En la Ecuación (1) se puede apreciar cómo se calcula la similaridad entre el aspirante u y el aspirante v en una matriz dispersa, donde i representa la enésima característica y r el valor de la característica. Sea, además, I´ el conjunto de todas las características en común entre u y v.
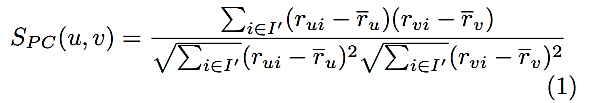
La Ecuación (2) es utilizada para calcular la similaridad de Jaccard, en este caso lo importante es determinar si existe intersección entre las características de u y v sin importar la diferencia de magnitud entre sus valores.
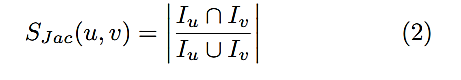
Los resultados muestran que el promedio de similaridad entre usuarios de un mismo grupo de aspirantes con la misma discapacidad está alrededor de un 0,1 tanto para la similaridad de Pearson y ligeramente inferior para la de Jaccard.
Con el conjunto de datos modificado no tiene sentido aplicar similaridad de Jaccard puesto que siempre dará uno, ya que se trata de una matriz completa, sin embargo, con la similaridad de Pearson se obtiene una mejoría en el promedio de similaridad entre usuarios de un mismo grupo de aspirantes con la misma discapacidad de 0,25, lo cual es evidencia que la eliminación de algunas características simplificó el sistema y mejoró los resultados.
Con el nuevo conjunto de datos se procedió a generar un mapa de calor para determinar correlaciones entre las características de los aspirantes. La Figura 2 nos presenta el mapa de calor entre las características más relevantes, donde la intersección de cada fila y columna representa el coeficiente de correlación en el rango de [–1 1], donde valores cercanos a –1 significan una correlación fuerte inversamente proporcional y valores cercanos a 1 significan una correlación fuerte directamente proporcional, valores cercanos a 0 significan que no existe correlación.
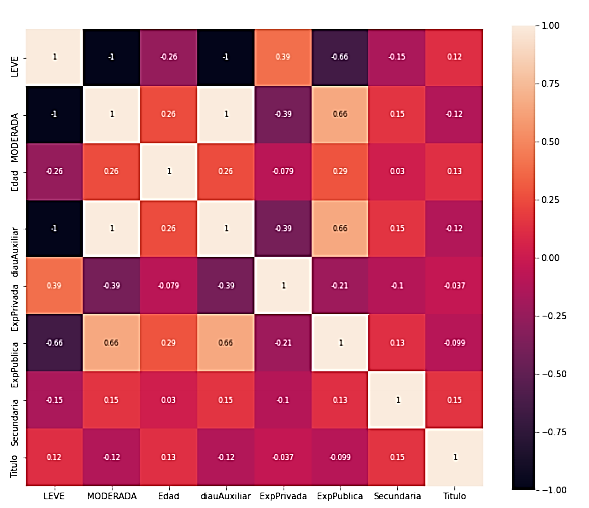
Figura 2. Mapa de calor de las correlaciones entre las características más relevantes del conjunto de datos.
En este primer análisis resulta notorio la relación directa que existe entre la experiencia y el nivel de discapacidad del aspirante (moderada, leve). Por un lado, la empresa privada tiene una relación directa con el nivel de discapacidad leve, y la empresa pública tiene una relación directa con el nivel de discapacidad moderado.
Adicionalmente, se procedió a visualizar si existen relaciones entre las diferentes características mediante un gráfico de dispersión. La Figura 3 permite apreciar la dispersión de puntos entre las diferentes parejas de características del conjunto datos, la diagonal muestra el histograma de cada característica.
Luego del análisis estadístico se procedió a la analítica de los datos, donde este trabajo tiene dos objetivos, el primero es generar un modelo de clasificación para la correcta asignación de una persona a un cargo. Segundo, mediante técnicas de clustering se pretende descubrir la cohesión de los grupos de aspirantes.
En el primer caso se compararán técnicas de clasificación como la regresión logística, máquinas de soporte vectorial y el algoritmo de los vecinos más cercanos. En el segundo caso se utilizará como algoritmo de clustering k-means
3. Resultados y discusión
3.1. Clasificación
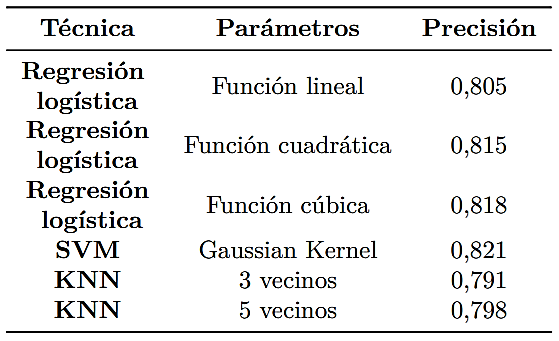
Al diseñar el modelo se utilizaron diferentes técnicas de clasificación, entre ellas, un esquema de regresión logística binaria, puesto que el objetivo es intentar predecir si una persona es adecuada para el cargo o no. La regresión logística fue probada con hipótesis de tipo lineal, cuadrática y cúbica, también se implementaron las técnicas de Support Vector Machines (SVM) con un kernel gaussiano y el algoritmo de los vecinos más cercanos (KNN) para resultados con 3 y 5 vecinos.
Para validar los resultados se procedió a dividir el conjunto de datos en cinco conjuntos aleatorios de train y test en una proporción de 80 % y 20 %, respectivamente. Los resultados muestran el promedio de los cinco conjuntos aleatorios en testing. La métrica utilizada para comparar la calidad de la predicción es la precisión según la Ecuación (3), donde TP representa el número de clasificaciones realizadas correctamente (verdaderos positivos) y FP el número de clasificaciones incorrectas (falsos positivos).
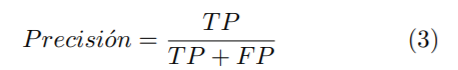
Los resultados de los diferentes modelos se aprecian en la Tabla 2. Si bien los mejores resultados se obtienen con SVM, la diferencia en la precisión con la regresión logística no es considerable, por ello para simplificar el modelo se puede utilizar la regresión logística.
3.2. Clustering
La técnica más famosa y bien conocida de hard clustering es el algoritmo k-means [24, 25] o hard c-means, que presenta las siguientes ventajas:
Conceptualmente es simple, versátil y fácil de implementar.
Presenta una complejidad lineal con respecto al número de elementos y clústers.
Se garantiza que el algoritmo termina con una tasa de convergencia cuadrática [23]
Para medir la calidad de clustering se utilizó la medida de cohesión Jc según la Ecuación 4, donde X representa la muestra del aspirante en cuestión y C representa el centroide al que pertenece.
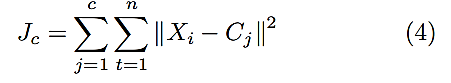
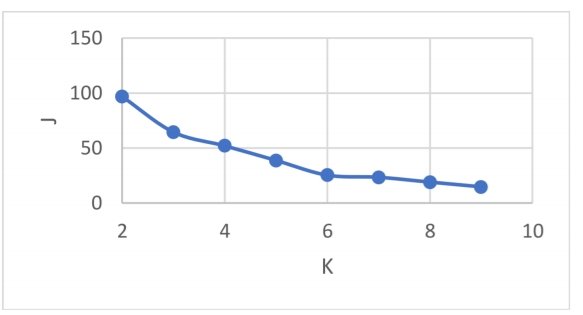
El algoritmo k-means utiliza el parámetro K como el indicador de los grupos a clasificar; sin embargo, el reto es determinar qué cantidad de grupos deben existir para expresar la mejor representación de los mismos. Para el conjunto de datos de los aspirantes se procedió a determinar la calidad de clustering desde k = 2 hasta K = 10. En la Figura 4 mediante el método Elbow [26] se puede apreciar que no existe una clara determinación en los grupos de aspirantes; se podría considerar tanto el valor de K = 3 como el valor de K = 6 como puntos de inflexión donde la calidad del clustering se estabiliza según la curva. Esto muestra que la información que se está recopilando en el sistema requiere más trabajo, tanto en cantidad como en calidad de las características.
4. Conclusiones
El presente estudio permite visualizar las correlaciones que existen entre diferentes variables del conjunto de datos, aportando como novedad la incorporación de técnicas de aprendizaje automático, tanto de aprendizaje supervisado para apoyar los procesos de selección del talento humano con discapacidad como de aprendizaje no supervisado para determinar en el alto espacio dimensional la cantidad de grupos de candidatos que existen en el conjunto de datos
De acuerdo con el estudio realizado se pudo observar que el factor más determinante a la hora de conseguir empleo para una persona con discapacidad es su experiencia, es decir, haber trabajado previamente en algún lugar; en el conjunto de datos existe una correlación directa entre los aspirantes que fueron considerados aptos y la experiencia previa, sin embargo, los aspirantes que pese a ser aptos y no han sido ubicados, tienen como factor común no disponer de dicha experiencia; lo cual evidencia que para el caso de estudio, la principal característica que determina que una persona con discapacidad obtenga un cargo es esta experiencia, factor que puede ser considerado discriminatorio ya que atenta contra la igualdad de oportunidades. El conjunto de datos con el que se trabajó es considerado el más completo de su tipo para selección de personal con discapacidad, sin embargo, el presente estudio ha demostrado que se requieren características más relevantes. Es preciso mencionar que el estudio también encuentra limitaciones en la cantidad de muestras, actualmente el conjunto de datos ofrece 120 lo cual nos limita a las técnicas de aprendizaje automático, para el futuro sería interesante contar con un conjunto de datos mucho más grande para aplicar técnicas de aprendizaje profundo.
Varios estudios demuestran que el nivel de educación mejora la oportunidad de conseguir empleo [27], situación que no se cumple en el conjunto de datos analizado. Dichos estudios demuestran también que las personas con discapacidades tienen un nivel de educación inferior, comparado con la población general, elemento que es fácilmente verificable en este caso de estudio. La preparación académica determina que las personas con discapacidad están en desventaja para las labores que exige el mercado por razones que van más allá de la misma discapacidad. Tanto la capacitación como el nivel educativo influye notablemente en las oportunidades de trabajo, ya que en este proceso de formación se adquieren las habilidades y conocimientos dentro un área específica [28]. Los sistemas actuales continúan siendo discriminatorios para estas personas, puesto que la mayoría de organizaciones privilegia la experiencia y esto induce a una pobre valoración de las actitudes de estas personas. Situación que se ve reflejada en la calidad de los sistemas de predicción y la incapacidad para descubrir patrones de clustering claros en los datos proporcionados.
Se considera que un campo novedoso de estudio en los procesos de reclutamiento es la aplicación de chatbots en las entrevistas de selección de personal, puesto que permite eliminar elementos subjetivos que los expertos consideran que son variables de confusión que orientan en uno u otro sentido las entrevistas, factores subjetivos como la imagen personal percibida por el entrevistador, su estado de ánimo son elementos difíciles de medir y que por tanto podrían eliminarse con una adecuada selección de grupos de experimentales y de control [29].
Si bien es cierto que las políticas públicas han contribuido a la inclusión laboral de personas con discapacidad, es necesario que las empresas apoyadas en la tecnología vayan acortando las brechas que actualmente existen, asimismo eliminar en los estereotipos que impiden reconocer y potenciar las cualidades de las personas con discapacidad impidiendo así aprovechar su talento.

