











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink

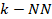
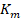
Introducción
Motivación
Las señales de tránsito tienen como objetivo el ayudar al movimiento ordenado y seguro de los actores, permitir un continuo flujo del tránsito tanto de vehículos como de peatones. Cada una de estas señales presenta instrucciones, las cuales proporcionan información acerca de rutas, destinos, puntos de interés, prohibiciones, alertas, etc. Estas señales deben ser respetadas por todos los usuarios viales con la finalidad de evitar inesperados y lamentables accidentes, y sobre todo, contar con una circulación confiable y segura [1]. El riesgo de que un peatón adulto muera tras ser atropellado por un automóvil es de menos el 20 % a una velocidad de 50 km/h, y de cerca del 60 % a 80 km/h, por lo que es fundamental para los conductores tener en cuenta la velocidad establecida por las señales de tránsito [2].
Actualmente, el Ecuador dispone de la mejor red vial de Sudamérica [3], sobre esta se ubican las señales de tránsito reglamentarias de Pare y Ceda el paso y Velocidad, en las intersecciones viales, redondeles y aproximaciones por vías secundarias. A pesar de esta importante infraestructura vial supera la tasa de muertes en accidentes de tránsito con un 3,14 % sobre la media de los países de la región andina. Así, los accidentes de tránsito son un problema constante, debido a varios factores críticos, como la imprudencia de los conductores al conducir con exceso de velocidad y al no respetar las señalizaciones de tránsito [4]. En el año 2015, el 13,75 % de todos los accidentes de tránsito sucedieron en las intersecciones viales [5] generando el 8,14 % de las personas fallecidas bajo este percance. Por otra parte, un peatón adulto tiene menos de un 20 % de posibilidades de morir si es atropellado por un automóvil a menos de 50 km/h, pero casi un 60 % de riesgo de morir si lo golpea a 80 km/h [2].
Los SDST toman cada vez mayor importancia [6], [7] porque pueden ayudar en la prevención y en la reducción de los accidentes de tránsito [8]. Sin embargo, estos sistemas aún están lejos de ser perfectos, y deben ser especializados por países, adaptados a las particularidades del diseño de la señalética de tránsito de cada nación [9].
Por lo tanto, en esta investigación se presenta un SDST especializado en tres tipos de señales de tránsito del Ecuador como son Pare, Ceda el paso y Velocidad. El poder detectarlas es importante porque permite alertar al conductor de que atravesará una zona con alto potencial de choque con otro vehículo. En el caso del disco Pare, el conductor debe detenerse completamente; en el caso de Ceda el paso, el conductor debe entrar en vigilia, y en el caso de velocidad el conductor debe respetar los límites de velocidad de 50 km/h y 100 km/h, en zonas urbanas y de autopista, respectivamente. La señal de velocidad de 50 km/h es el límite más cotidiano en ambientes urbanos y la de 100 km/h en autopistas.
Para la implementación de SDST se han utilizado modernas técnicas de visión por computador e inteligencia artificial con el fin de cubrir todos los casos que se presentan en la conducción durante el día, como son: variabilidad de la iluminación, oclusión parcial y deterioro de las señales.
El resto del documento está organizado de la siguiente manera: la segunda sección corresponde a los trabajos previos en la detección de señales de tránsito. En el apartado tres un nuevo sistema para la detección de señales de tránsito para el caso de las señales de tránsito ecuatorianas de Pare, Ceda el paso y Velocidad. Luego, la siguiente sección exhibe los resultados experimentales en condiciones reales de conducción. Finalmente, la última parte está dedicada a las conclusiones y los trabajos futuros.
Materiales y métodos
Trabajos previos
Para el desarrollo de sistemas de detección automática de las señales de tránsito se suele dividir al problema en dos partes, segmentación y reconocimiento/clasificación [10].
-
En el caso segmentación, una de las características predominantes, en el espectro visible, es el color, donde se han utilizado espacios de color y distintas técnicas de visión por computador para generar regiones con alta posibilidad de contener una señal de tránsito.
Tanto es así que la mayoría de las técnicas basadas en color buscan ser robustas frente a las variaciones de iluminación durante el día, en distintos escenarios como pueden ser soleados, nublados, etc. Así Salti et al. [14] han utilizado tres espacios de color derivados de RGB, el primero para resaltar las señales de tránsito con predominancia de los colores azules y rojos, el segundo es para las señales con rojo intenso y el tercero para los azules vivos. Li et al. [15] han construido un espacio donde resaltan los objetos dominados por los colores azul-amarillo y verde-rojo, sobre el cual, utilizando el algoritmo de agrupamiento K-means [16] construyen un método de clasificación por color para la generación de ROI. Nguyen et al. [6] han utilizado el espacio HSV con varios umbrales para generar un conjunto de ROI buscando colores rojos y azules. Lillo et al. [17] han utilizado los espacios L*a*b* y HSI para detectar señales donde predominan los colores rojo, blanco y amarillo, usando las componentes a* y b* han construido un clasificador para estos colores. Chen and Lu [18] han utilizado multirresolución y técnicas AdaBoost para fusionar dos fuentes de información, visual y localización espacial; en la visual construyen dos espacios de color basados en RGB denominados mapas salientes de color, en la espacial han usado el gradiente con distintas orientaciones. Finalmente, Han et al. [19] han usado la componente H del espacio HSI, para generar un intervalo, donde resaltan las señales de tránsito, y construir una imagen en grises donde se localizan las ROI. Villalón et al. [20] han implementado un filtro usando el espacio de color RGB normalizado, sobre el cual, mediante el cálculo de parámetros estadísticos han generado las regiones de color rojo y así han obtenido las ROI.
-
En el escenario reconocimiento/clasificación se han utilizado algunos métodos para la extracción de características en conjunto con un algoritmo de aprendizaje-máquina [11], [12], [13], para así clasificar y reconocer los distintos tipos de señales.
Esta etapa se divide en dos partes: i) método de extracción de características y, ii) elección del algoritmo de clasificación. En el primer caso se tiene una amplia variedad de propuestas. Así, Salti et al.[14], Huang et al.[21], Shi and Li [22] han utilizado el descriptor HOG [23] con tres variantes especializadas en señales de tránsito. Li et al. [15] han usado el descriptor PHOG, que es una variación de HOG en sentido piramidal. Lillo et al.[17] han implementado la extracción de características usando la transformada discreta de Fourier. Han et al.[19] han utilizado el método SURF [24]. Chen and Lu [18] emplearon DSC iterativo para la generación del vector de características. Mongoose et al.[9] implantaron en conjunto ICF y ACF para generar las características. Pérez et al.[10] han usado la técnica PCA para la reducción de la dimensión y la elección de características dominantes. Finalmente, Lau et al. [25] han usado una ponderación de los píxeles vecinos para resaltar las características del objeto de interés. En la segunda cuestión, los algoritmos preferidos son: SVM [13], [16], utilizado en los trabajos de Salti et al.[14], Li et al.[15], Lillo et al.[17] y Shi and Li [32]. SVR usado en Chen and Lu [18], [13] implementado en las investigaciones de Han et al.[19]. Redes neuronales artificiales, empleadas por Huang et al.[21] con el caso ELM y Pérez et al.[10] con la implementación MLP. Adaboost con árboles de decisión utilizados en el trabajo de Mogelmose et al.[9]. Villalón et al.[20] han desarrollado una plantilla estadística basada en un modelo en probabilidad ajustado sobre los espacios YCbCr y RGB normalizado. En los últimos años, las técnicas basadas en aprendizaje profundo van ganando mayor importancia, tanto es así que CNN y sus variaciones son utilizadas para la clasificación automática, donde el vector de características se extrae sin la intervención humana directa, en este caso están los trabajos de Lau et al. [25], Zhu et al.[26] y Zuo et al.[36].
Respecto a las bases de datos de señales de tránsito se puede mencionar que cada país tiene sus propias normativas en cuanto a su señalética, divida en las categorías de informativas, obligatorias, prohibitivas y advertencia [9], [14], [17], [18], [26]. En la actualidad, las principales bases de datos, presentes en la bibliografía, corresponden a países como Alemania [10], [21], Italia [14], España [17], Japón [6], Estados Unidos [9], Suecia [26], Malasia [25]; aisladamente se tiene el caso de Chile [20]. Esta revisión bibliográfica demuestra que no existe información importante, y menos aún, confiable de los países en desarrollo, como es el caso del Ecuador, en lo que respecta a las bases de datos de señales de tránsito; esto genera un reto para levantar este tipo de información, que además debe ser relevante para garantizar la seguridad vial y el mantenimiento de la infraestructura vial.
Métodos para la construcción del sistema de detección de señales de tránsito
El esquema del sistema propuesto en esta investigación se presenta en la Figura 1, donde están las etapas de segmentación (localización) y reconocimiento (clasificación). En el proceso de segmentación se genera un conjunto de ROI, que posteriormente será enviado a la etapa de clasificación para su reconocimiento. En esta propuesta únicamente se trabaja en el caso restringido de las señales de tránsito Pare, Ceda el paso y Velocidad de 50 km/h y 100 km/h. Estas señales tienen en común el color rojo, y pertenecen al tipo prohibición.
A) Segmentación por color y generación de ROI
-
La Figura 1 (izquierda) muestra el esquema de segmentación que se describe a continuación.
La segmentación se realiza discriminando el color rojo del fondo, es decir, del resto de colores. Experimentalmente se ha elegido el espacio de color RGB normalizado (RGBN) porque presenta una distribución más compacta en los canales Bn y Gn , cuyos valores se encuentran en los intervalos [20;90] y [0;90] respectivamente. La Figura 2 (a) muestra la distribución del color rojo en función de las condiciones de iluminación, normal, soleado y oscuro. Figura 2 (b) muestran las distribuciones de las clases, donde el rojo representa la clase de interés y el azul identifica la clase de no interés.

Figura 1. Esquema propuesto para la localización y reconocimiento de señales de tránsito en intersecciones viales en el Ecuador en el espectro visible, para los casos Pare y Ceda el paso; y su posterior extensión al caso de velocidad en 50 km/h y 100 km/h.


(c) Figura 2. Distribución del color en el espacio RGB normalizado Bn y Gn , (a) distribución en función de las condiciones de iluminación, (b) representación de las clases de interés y no interés, (c) gráfico de los centroides generadas con Kn -means.
-
1) Puntos representativos en el espacio Bn y Gn : Para generar un número reducido de puntos representativos de cada clase se utiliza el algoritmo de agrupación Km -means [12]; de esta manera, se obtienen Km centroides para cada una de las clases.
Utilizando los métodos de Calinski- Harabasz [27], Davies-Bouldin [28], Gap [29] y Silhouettes [30] se ha llegado a determinar experimentalmente el valor eficiente de Km , obteniéndose los siguientes valores, 30 y 40 para las clases rojo y no rojo (otros colores), respectivamente. La Figura 2(b) muestra los centroides de las dos clases generadas con Km . Para generar esta figura se han utilizado muestras en tres condiciones de iluminación: soleado, normal y oscuro.
2) Diseño del clasificador basado en K-NN: Para diseñar este clasificador es importante elegir un valor de K adecuado que permita la mejora discriminación entre las clases de interés y el fondo. En este sentido, se ha usado el valor del área bajo la curva, conocido como índice AUC, de la curva ROC [31]. Los valores utilizado para este procedimiento están entre 1 y 8. La Tabla 2 muestra los resultados para elegir el mejor valor de K.

3) Postprocesamiento de cuerpos: Posteriormente, utilizando los operadores morfológicos de dilatación y erosión [32] se eliminan ciertos cuerpos que no cumplen con características específicas de tamaño para ser candidatos a señales de tránsito. Experimental se ha fijado varios umbrales para este procedimiento.
4) Restricciones geométricas: Finalmente, se eliminan los cuerpos que no cumplen la relación alto/ancho, usando umbrales determinados experimentalmente; en la Tabla 3 se presentan los parámetros necesarios en función de la distancia de referencia. Esta distancia es parte de la zona de riesgo de colisión de un vehículo.

Tabla 3: Características geométricas que debe cumplir una ROI sobre una imagen de tamaño 640x480 en función de la distancia de referencia
-
B) Reconocimiento de las señales de tránsito
En esta etapa se clasifican las ROI provenientes de la etapa de segmentación, para determinar si corresponden a una señal de Pare, Ceda el paso, Velocidad u otro objeto que no sea de interés.
En la Figura 1 (derecha) se muestra el esquema de reconocimiento, el mismo que consta de las siguientes partes:
1) Preprocesamiento de los candidatos: Se transforma las imágenes correspondientes a las ROI a escala de grises, después se normalizan al tamaño 32x32 píxeles y posteriormente se realiza la ecualización del histograma para obtener una imagen con una distribución uniforme de los niveles de gris. Este proceso permite aumentar el contraste de la imagen y disminuir los cambios abruptos de iluminación.
2) Extracción de características: Se utiliza una nueva versión del descriptor HOG [33] para encontrar las características representativas de una señal de tránsito. La innovación desarrollada sobre este descriptor se centra en variar el tamaño de las celdas y las orientaciones, y encontrar la mejor combinación adaptada a las señales de tránsito. En este sentido, las celdas toman valores de 2x2, 4x4, 8x8 y 16x16 píxeles. La Figura 3 muestra esta forma de división en los cuatro casos. La orientación se obtiene dividiendo al rango de orientación sin signo de [-90°;90°] o
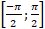 en 3,6,9,12 y 15 intervalos.
en 3,6,9,12 y 15 intervalos.
(d) Figura 3. Variación del tamaño de celda sobre imágenes de tamaño 32x32 pixeles: (a) 2x2, (b) 4x4, (c) 8x8 (d) 16x16.
-
3) Entrenamiento del clasificador basado en SVM: Se utiliza SVM [11], [12], [13] con tres núcleos diferentes para experimentar la mejor opción: lineal, polinómico y RBF. Para el entrenamiento se usan tres conjuntos de datos que corresponden a las señales Pare, Ceda el paso, Velocidad y otros elementos que no pertenecen a los casos anteriores.
Sobre esta gama de parámetros se escoge la mejor opción usando el índice AUC [31]. En total se evalúan 60 casos combinando los puntos 2 y 3, de los cuales se extraen los que generan mejores resultados en la siguiente sección.
Resultados y discusiones
A. Sistema de percepción y procesamiento
El sistema de detección de señales de tránsito total se presenta en la Figura 4. El sistema de percepción está compuesto por una cámara webcam con entrada USB a 25 fotogramas por segundo, una pantalla de visualización y un soporte para la cámara. El sistema de procesamiento es un computador instalado sobre el vehículo experimental ViiA. Este vehículo incorpora una fuente de poder de 12 V-120 AC que suministrar continuamente corriente eléctrica para el funcionamiento del sistema en carretera.

Figura 4: Sistema de detección de señales de tránsito del Ecuador, en los casos Pare, Ceda el paso y Velocidad (50 y 100), instalado sobre el parabrisas de un vehículo experimental.
Actualmente, este sistema es de fácil instalación en cualquier tipo de vehículo, y no interfiere con las labores de conducción debido a su reducido tamaño.
B. Base de datos de entrenamiento, validación y experimentación
Las bases de datos de entrenamiento y de validación han sido construidas con imágenes de señales de tránsito del Ecuador, tomadas en las ciudades de Latacunga, Ambato, Salcedo, Quito y Sangolquí, en escenarios reales de conducción, en distintas condiciones de iluminación durante el día. Estas condiciones corresponden a los casos de normal, soleado y nublado. Más detalles se encuentran en la Tabla 4.
En la Tabla 5 se indica el tamaño de los conjuntos de entrenamiento y de validación obtenidos por medio del método de Holdout [34] y en la Figura 5 se observan varios ejemplos positivos y negativos.
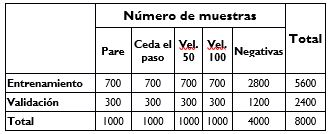
Tabla 5: Tamaño de los conjuntos de entrenamiento y validación por las señales Pare, Ceda el paso y negativas

(e) Figura 5: Ejemplos de la base de datos de señales de tránsito del Ecuador en distintas condiciones de iluminación y de estado, (a) Pare, (b) Ceda el paso, (c) límite de 50 km/h, (d) límite de 100 km/h y (e) ejemplos negativos.
Para incrementar el tamaño del conjunto de entrenamiento se rotaron aleatoriamente las imágenes hasta obtener un total de cinco veces el tamaño original. De esta manera, se incrementa la variabilidad de la base de datos.
Posteriormente para verificar el funcionamiento del sistema se construyó una base de datos con vídeos en situaciones reales de conducción, en el espectro visible bajo distintas condiciones de iluminación. Esta base está constituida por cinco ejemplares en diferentes condiciones de iluminación, donde las señales han sido localizadas manualmente con fines de evaluación [31].
C. Análisis de resultados
Los resultados se pueden resumir en los siguientes puntos:
1) Para el caso de la segmentación por color, el algoritmo de clasificación genera un AUC de 0,986, con K=4 y Km=30 para la clase de color rojo y K=3 y Km=40 para la clase otros colores.
2) Para el caso de la clasificación, los mejores parámetros del descriptor HOG son celdas de 8x8 píxeles, bloques de 2x2 celdas con solapamiento simple, 9 orientaciones sin signo y SVM polinomial de parámetros C=215, r=0, d=3, y=1/m, con m es el tamaño del vector de características. En la Tabla 6 se presentan los resultados para el caso de 8x8 píxeles, donde el mejor resultado se encuentra resaltado en negrilla.
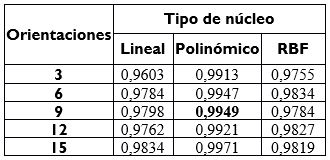
Tabla 6: Resultados de clasificación con características HOG con celdas de tamaño 8x8 píxeles en todas las orientaciones.
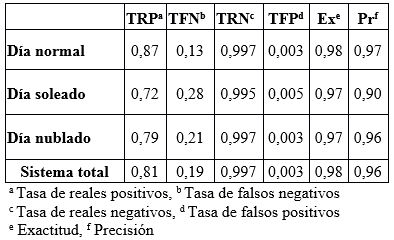
Para medir el poder de detección, la curva de la tasa de falsos negativos (taza de pérdida) versus la tasa de falsos positivos, en escala logarítmica en el rango de 0.01-1m [35], se presenta en la Figura 6, en ella se observa que el mejor desempeño se realiza en días normales con una tasa de pérdidas del 13 % y la peor ejecución es en días soleados con una taza de pérdidas del 28 %.
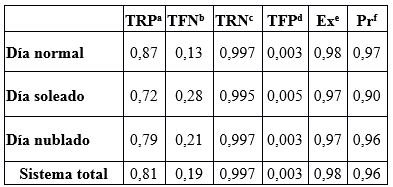
El sistema tiene un excelente desempeño, con una precisión promedio del 96 %. La peor precisión se logra en condiciones soleadas, ya que el exceso de luz impide una correcta segmentación para la generación de ROIS, ver Tabla 7.
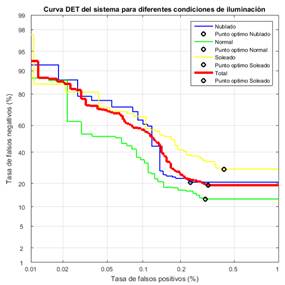
Figura 6. Curva DET del sistema de detección de señales de tránsito, separado en los distintos casos de iluminación y globalmente.

Tabla 7: Resultados del sistema de detección de señales de tránsito en diferentes escenarios de iluminación durante el día
Varios ejemplos generados por el sistema se los puede observar en las Figuras 7, 8, 9 y 10. Las muestras se encuentran en diversas condiciones de iluminación durante el día, amanecer e inicio de la noche, al recorrer zonas urbanas y zonas de autopista alrededor de las ciudades de Quito y Sangolquí.



(c) Figura 7: Resultados del sistema de detección de señales de tránsito en el caso Pare, durante un día soleado sobre una autopista; (a) imagen de entrada, (b) ROI y (c) detecciones.



(c) Figura 8. Resultados del sistema de detección de señales de tránsito en los casos Pare y Ceda el paso, durante un día oscuro en zona urbana; (a) imagen de entrada, (b) ROI y (c) detecciones.



(c) Figura 9. Resultados del sistema de detección de señales de tránsito en el caso de velocidad de 50, durante un día oscuro (al amanecer) en zona urbana; (a) imagen de entrada, (b) ROI y (c) detecciones.



(c) Figura 10. Resultados del sistema de detección de señales de tránsito en el caso de velocidad de 100, durante un día oscuro en zona urbana; (a) imagen de entrada, (b) ROI y (c) detecciones.
D. Tiempos de cómputo
En la Tabla 8 se presenta el tiempo de cómputo del sistema global.

Tabla 8. Tiempos de cómputo total del sistema de detección de señales de tránsito del Ecuador en el espectro visible en los casos Pare, Ceda el paso.
Estos resultados son los valores promedios del procesamiento de 37185 imágenes de tamaño 640x480 píxeles, distribuidos de la siguiente manera: 9999 en soleado, 14744 en normal y 12442 en nublado.
A partir de estos resultados experimentales se puede verificar que los tiempos de cómputo; en los casos de segmentación y de reconocimiento, son bastante reducidos y por ende competitivos para ser parte de aplicaciones en sistemas en tiempo real.
Conclusiones y trabajos futuros
En este trabajo de investigación, en el campo de los sistemas de asistencia a la conducción con énfasis en la detección de las señales de tránsito, se realizaron los siguientes aportes originales:
La construcción de una nueva base datos para el reconocimiento de señales de tránsito del Ecuador, en los casos Pare, Ceda el paso y Velocidad. Esta información está disponible para el libre uso de la comunidad científica.
El desarrollo de un nuevo método de segmentación por color para la generación de ROI utilizando el clasificador K-NN junto con el algoritmo de agrupamiento Km - means. Esta implementación cubre eficientemente los escenarios de iluminación normal, soleado y oscuro, durante el día. Además, se incluye la distancia como un parámetro de referencia para la preselección de ROI. De esta manera, esta propuesta alcanza una tasa de clasificación del 98,7 % en los píxeles de interés y el fondo.
La implementación de una nueva versión del descriptor HOG que consiste en celdas de 8 × 8 píxeles, bloques de 2 × 2 celdas con solapamiento simple y 9 orientaciones sin signo. La tasa de clasificación es del 99,49 usando SVM con núcleo polinómico.
La construcción de un sistema de detección de las señales de tránsito del Ecuador, especializado en los casos Pare y Ceda el paso. La curva DET indica que su desempeño es del 96 %, de manera que es competitivo respecto a las propuestas presentes en el estado del arte.
La construcción de un asistente de ayuda a la conducción que trabaja en tiempo cuasi-real, es decir, a 21,58 fotogramas por segundo, es un sistema de fácil instalación en un vehículo de uso cotidiano.
Para el futuro se extenderá esta metodología a todas las señales de tránsito del tipo prohibición del Ecuador, donde se encuentran el resto de las señales de límites de velocidad, para área urbana y autopsitas. Finalmente, indicar que se introducirá un método para comprobar y comparar la calidad del clasificador, en este sentido, se está preparando un método basado en ELM.

