











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
I. INTRODUCTION
Due to the ever-evolving nature of software engineering and the continuous emergence of new languages, dialects, and language versions, the precise number of programming languages in current use remains uncertain. According to a study by Nanz and Furia, which examined 7,087 programs addressing 745 distinct issues, the most popular programming languages were found to be C, Java, C#, Python, Go, Haskell, F#, and Ruby (1).
In the realm of modem software application development, artifacts originating from a variety of programming languages are often used, particularly in large-scale projects (2), The objective is to take advantage of specific aspects of each language to create more comprehensive, efficient, and effective systems. However, the complexity of programming tasks and the demand for engineers proficient in multiple programming languages pose challenges that make development more intricate. The intricate nature of programming lies in the unique syntax of each language.
In order to aid development and maintenance activities, development teams heavily rely on the utilization of tools. Assessing the structure and interconnections among system components becomes challenging, especially when programmers need to evaluate programs written in different programming languages. Various techniques, such as examining source code for patterns and interdependencies, computing quality metrics (e.g., complexity, cohesion, direct and indirect coupling and logical coupling), as well as identifying clones and defects, are employed (3).
In this context, it is crucial to recognize that software quality is a fundamental attribute that distinguishes software and companies. The ISO / IEC 9126 standard, along with its successor, the ISO/IEC 25000 series, defines a multidimensional model for evaluating software qualify based on factors such as functionality, reliability, maintainability, efficiency, usability, and portability. Additionally, developers often rely on tools to facilitate development and maintenance processes.
Methods for source code analysis in various programming languages, which adhere to different paradigms and possess distinct syntaxes, typically necessitate the development of unique analyzers for each language grammar. However, given the vast array of existing languages and the continuous emergence of new ones, creating a dedicated analyzer for every language is impractical.
An alternative approach is to implement a single analyzer that operates on a generalized representation of languages. Such an analyzer would collect information for metric calculation, internal software analysis, and investigation of interconnections among system components. This approach can contribute to cost reduction and minimize the need for language-specific analyzers.
To achieve this, all syntactic aspects of the represented languages must be considered and the representation itself should be scalable to accommodate the inclusion of additional languages. Furthermore, it should be able to adapt to the evolving characteristics of languages. The aim of this project is to develop a technique to automatically convert the syntax of a specific language into a generic syntax, capturing the unique traits of each language to enable software project analysis.
The methods for translating a language into a generic format that are currently available are limited in number and replete with drawbacks. These methods require separate tools for each language, such as SonarQube (4) and Moose (5), to analyze the source code.
This article presents the findings of the implementation of a Generic Abstract Syntax Tree (GAST) that possesses a unified structure across multiple programming languages. The efficacy of this method is demonstrated through two experiments, which showcase the successful transformation of diverse languages into the GAST and the ability to conduct various types of structural analysis on it.
The subsequent sections of the article are structured as follows. Section H provides an overview of related works related to techniques for the transformation of source code. Section HI outlines the design and structure of the GAST, together with the validation method used for language-specific transformations. Section IV delves into the results and analyses derived from the experiments conducted, which substantiate the equivalence between specific languages and the GAST. Finally, sections V and VI present the conclusions drawn from the study and outline potential avenues for future research.
II. RELATED WORK
The program source code is often translated from one language to another using transpilers. These tools enable code to be written once and then translated into multiple target languages, allowing translated scripts to be executed across various platforms(6). Transpilers commonly employ a syntax processing module, linear mappings, and code generation as integral components(7).
Various strategies are employed by transpilers, including machine learning techniques, translation rules, and the use of Abstract Syntax Trees (AST). The general principle underlying AST techniques involves creating an AST representation of the source code units and then mapping its components into an AST representation of the target language.
Semantic Program Trees (PST)*transpilers follow the following procedures(8)to convert the source code of the program from one language to another:
Analyze the source code of the original program to determine its PST.
Collect the libraries and dependencies utilized by the original program.
Create a second PST with appropriate references for the destination program.
Utilize the second PST and the grammar of the target language to generate the source code for the final program.
Kijin et al. propose a cross-platform strategy based on translation rules(9). This approach uses linear mappings, transformations, and translation rules to establish equivalences across syntactic elements, with the aim of automating software translation between languages. Other approaches attempt to convert pseudocode to source code by constructing an intermediary model that incorporates a metamodel to represent pseudocode in a more structured manner(10).
CRUST employs an intriguing technique, a transpiler that converts C / C++ programs to Rust**code. In the CRUST conversion process, a set of compact syntactic analyzers calledNano-Parsers(11)is utilized. TheseNano-Parsersare designed to handle specific grammars and cooperate with other analyzers, including aMaster Parser,to handle complex text inputs.
The CRUST architecture comprises two key components: the syntax analyzer module and the code generator. TheNanoParsers,constituting the syntactic processing element, employ a matching function that is activated when a regular expression identifies a valid pattern corresponding to Rust code. However, this strategy has two notable limitations: the need to develop parsers for each language and the requirement to specify regular expressions for multiple programming languages, including the complex RPG language, which is responsible for generating millions of lines of legacy code.
A technique known as tree-to-tree encoding and decoding uses parse trees and deep neural networks to convert source code from one language to another(12). This approach includes a training phase to enhance the encoding process. The input is encoded using a list of symbols, which assesses the likelihood of elements and selects the one with the best fitness value from the set. The subsequent decoding stage involves constructing nodes in the target programming language, starting from the root and generating offspring. Neural networks are used to implement a tree-to-tree encoding and decoding model, maintaining consistency with this concept(13).
Machine learning (ML) techniques have been employed in numerous research projects for automatic source code translation(14). While supervised methods are commonly used, ML techniques can be classified as unsupervised, supervised, or reinforced. Many studies leverage source code from GitHub projects to train supervised learning algorithms. Since ASTs exhibit some degree of equivalence across languages, this type of research is particularly effective for languages with a similar level of abstraction.
Some research efforts use machine learning (ML) to translate source code(14)automatically. ML methods are classified as supervised, unsupervised, and reinforced, although the most common approaches use supervised methods. Much research uses source code from GitHub projects to train supervised methods. This type of research operates correctly with languages of a similar level of abstraction because the ASTs have some equivalence with each other.
Deep learning is often employed for language translation tasks. For example, Pengcheng and Graham utilize decoders and encoders to construct a neural network architecture that generates code from an AST(15). Recurrent Neural Networks (RNNs) are employed in the decoders to simulate the sequential creation of a predefined AST, while Long Short-Term Memory (LSTM) networks are utilized in the encoders to generate a set of words. Token generation can utilize a predefined vocabulary or directly copy from the language input. Their study aims to produce an AST by employing grammatical model actions.
Another promising approach is the adoption of an abstract syntax network, although this method is prone to creating unstructured mappings during code production(16). The model architecture is based on a hierarchical encoder-decoder. The decoder represents and constructs outputs in the form of ASTs using a modular structure, as opposed to a dynamic decoder that simultaneously develops the output tree structure. The HEARTHSTONE benchmark yielded favorable results for code generation, achieving a BLEU (Bilingual Evaluation Understudy) score of 79.2 % and an accuracy rate of 22.7 % for precise matches.
Another approach to translating source code into different languages is Statistical Machine Translation (SMT). Oda et al. utilized this method to convert Python code into pseudocode(17). Their approach involves examining the source code file word-by-word to determine the best output based on the specified model. The code is then structured using an AST, from which the pseudocode is generated. Although this method is fast and automated, it does not guarantee semantic validity. Therefore, human evaluation is necessary to assess the output’s correctness.
Similarly, Nguyen et al. employed SMT to convert Java source code for Android and C# for Windows Phone(18). The concept behind their approach is to utilize SMT to infer translation rules by leveraging already migrated code as a baseline, rather than manually defining additional rules. They generate a set of annotations by training a model with the ASTs extracted from the source code. Subsequently, further training is conducted to construct lexemes, which are combined to produce the final C# source code.
III. GENERIC ABSTRACT SYNTAX TREE
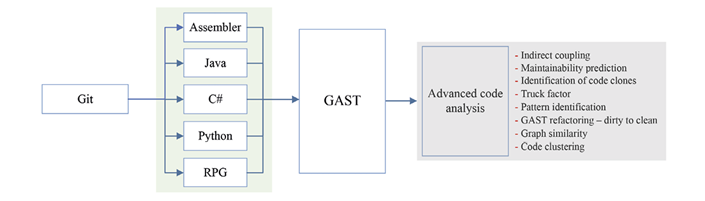
The GAST is designed to serve as a representation of language-specific ASTs (SASTs) in order to facilitate source code analysis across multiple programming languages. The definition of the GAST is based on the Meta Object Facility Specification (MOF)(19).Figure 1provides an overview of the GAST-supported process and its interaction with other components of the analysis framework. The general steps of this process are as follows.
Obtain the source code of the desired language from a Git software repository. The GAST currently supports several languages, including Assembler, Java, C#, Python, and RPG.
Map the corresponding GAST component to each syntactic part of the SAST for each language (seeFigure 2).
The Advanced Code Analysis Engine (ACAE) utilizes the GAST format as input to perform various types of analysis.
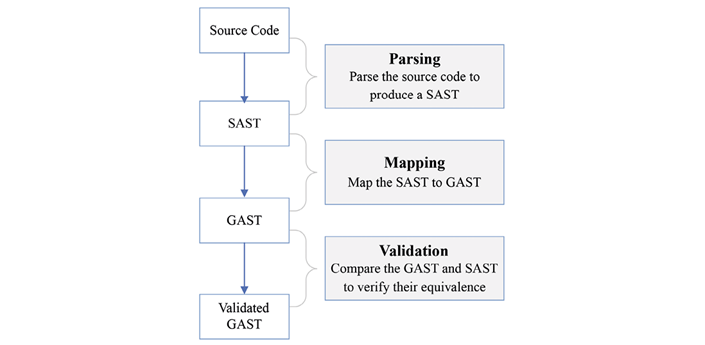
Figure 2specifically illustrates the process of integrating a specific language into the GAST. The input for this process is the source code of the target program, while the validated GAST representation serves as the output. This process consists of three steps:
During the parsing phase, the source language and source code are provided to obtain the SAST.
Certain syntactic elements of the SAST are transformed into corresponding constituents of the GAST.
The mapping’s validity is verified by comparing the structures of the GAST and SAST to ensure their similarity.
To generate each unique Abstract Syntax Tree (AST), a parser generator or specialized tool is necessary. In this study, ANTLR is used for languages other than Java, where the Java Development Toolkit (JDT) is employed for parsing Java source code and obtaining the corresponding AST(20).
The mapping stage determines the equivalence between syntactic components of the SAST and the corresponding structures in the GAST. The mapping rules that establish the connection between SAST and GAST elements are specified.MapStruct(21)is utilized to define these rules and perform the mapping of elements. In addition to supporting linear mappings between objects,MapStructis capable of recursive processing during element mapping.
Once the parsing and structure mapping stages are completed, the validation phase begins. This phase ensures that the mapper has correctly linked all syntactic components from the SAST into the GAST tree. The validation phase is discussed in more detail in Section III A.
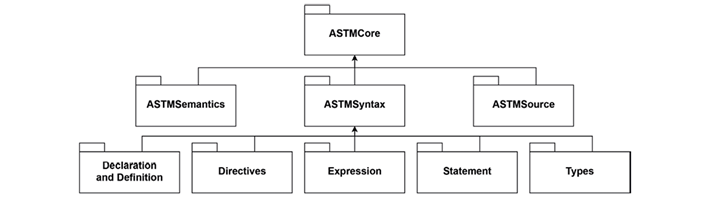
Figure 3depicts the high-level package diagram illustrating the structure of the GAST. The primary package, denoted as ASTMCore, encompasses three sub-packages: ASTMSemantics, ASTMSyntax, and ASTMSource. Each of these packages serves a distinct purpose within the GAST framework, as follows:
ASTMSemantics: The GAST structure is not concerned with semantic elements. However, it requires some elements to establish connections between syntactic elements, such as variable scopes within code blocks, is crucial. Considering the possibility of nested blocks, such as conditionals and nested loops, it is important to incorporate recursion in the class that models the scope.
To determine the validity scope of a component, various syntactic element scopes are implicitly modeled. For example, a variable defined within an if statement can only be used within the block of instructions associated with that if statement and not within an else statement. The ASTMSyntax package of the GAST structure is responsible for emulating the syntactic components of programming languages and encompasses a significant number of classes within the GAST framework. The main components of this package are outlined inFigure 3.
ASTMSyntax: The ASTMSyntax package of the GAST structure is responsible for emulating the syntactic components of programming languages and encompasses a significant number of classes within the GAST framework. The main components of this package are outlined inFigure 3.
Declarations and Definition: This package includes all syntactic elements that involve the declaration or definition of variables, functions, or data. It provides modeling capabilities for these elements.
Expressions: The Expressions package represents composed instructions that relate to other valid expressions. It includes binary operations, conditionals, type conversions, aggregations, function calls, and arithmetic operations.
Statement: This package closely resembles expressions as it employs expressions to control the flow of execution for each instruction. It encompasses statements such as while, if, for, return, or break. For instance, an if statement consists of the then and else parts, each containing instructions that may have their own scope. These instructions are often associated with an expression that determines the flow of execution, thereby establishing connections with classes in the expressions package.
Types: The Types package encompasses both primitive types and built-in types. It is relevant to the Declarations and Definitions package as it models named, aggregate, function, and namespace types, as well as formal parameter types.
ASTMSource: This package focuses on the compilation unit, which serves as an abstraction of a source file. The class contains attributes such as language, package, scope, and import fist, which define the fundamental structure of object- oriented code. The class representing a compilation unit also models additional data such as the file’s location, the position of its lines of code, and references to other files.
After mapping the instructions from a SAST into the GAST, the accuracy of the result is validated.
A. GAST validator
Following the completion of the mapping process, an essential automated task involves validating and verifying the accuracy of the mapping. Name equivalences play a key role in this process, as dictionaries are employed to establish connections between the two structures. The validator not only obtains the names of the leaf nodes but also establishes the corresponding nodes between the GAST and the SAST, ensuring the information contents of these nodes are equivalent.
The objective of this task is to verify the effectiveness of the mapping by ensuring that every element present in the SAST is also accurately represented in the GAST. Successful completion of this task confirms that the attributes of the analyzed files have been correctly mapped, thus demonstrating the GAST’s fidelity as a representation of the original program.
The GAST validator generates a report that highlights the differences between the mapping of the SAST and the GAST. It identifies the file paths where non-conformances are located, providing insights into any inconsistencies.
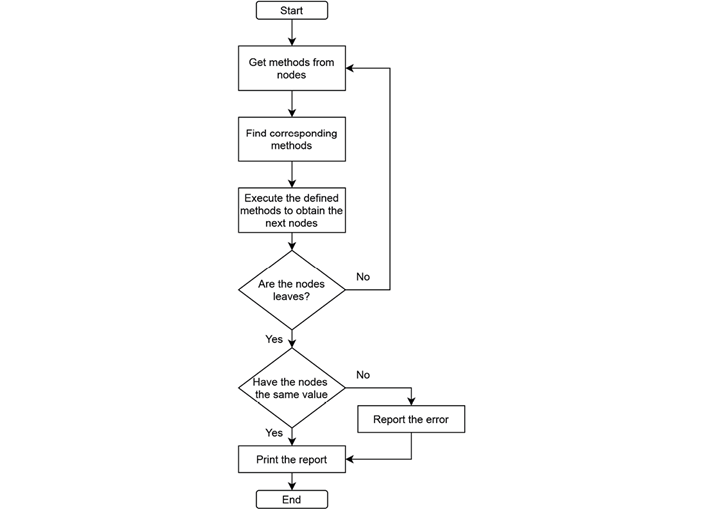
The flowchart inFigure 4illustrates the algorithmic process of the validator. It operates after generating the SAST and GAST for the given file. The initial phase of the algorithm involves retrieving the methods of a node. Subsequently, it compares the approaches of the two syntactic trees to determine their equivalence.
The dictionary containing the equivalences between the structures is utilized to facilitate the comparison. The algorithm then traverses the trees, ensuring that all nodes and leaf nodes in both trees are equivalent. Given that variables, constants, or modifiers are crucial components in both the SAST and GAST, their names can be used as values for comparison in the leaf nodes. If any discrepancies arise in the values of these elements between the two trees, the validator generates a report accordingly.
IV. RESULTS AND ANALYSIS
This section presents and analyzes the results of two experiments conducted to substantiate the following:
The feasibility of employing a unified AST to represent programs written in multiple programming languages. This is demonstrated in Section IV-A where the mapping of different SASTs to the GAST is discussed.
The adoption of the GAST representation allows for the development of a unified source code analyzer capable of analyzing diverse programming languages. Sections IV-B and IV-C validate the use of the GAST for the analysis of source written in multiple languages.
Furthermore, we showcase the structural capabilities of the GAST by applying various metrics to the GAST of the JDT project.
A. Mapping SAST to GAST
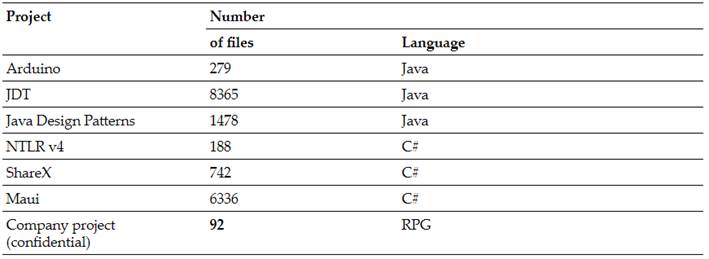
The aim of this experiment is to evaluate the GAST’s ability to accurately represent the syntactic elements of multiple SASTs and assess the feasibility of establishing a linear mapping between their corresponding elements. To ensure equivalence between the created SASTs and the GAST, RPG, C#, and Java were selected as target languages for testing. The projects selected for this experiment are listed inTable I. The assessment was carried out through the following steps:
1) The experiment proceeds as follows:Create the GAST structure for each project. 2) Verify the correct mapping between all SAST elements and the corresponding elements in the GAST. 3) Generate of a report highlighting the mapping differences between the SAST and the GAST. Compile statistics on the execution times of the project’s code transformations.
The experiment proceeds as follows:Create the GAST structure for each project.
Verify the correct mapping between all SAST elements and the corresponding elements in the GAST.
Generate of a report highlighting the mapping differences between the SAST and the GAST.
Compile statistics on the execution times of the project’s code transformations.
The GAST is a tree-based structure that serves as a representation of the source code. In this context, the code fragment depicted inFigure 5can be directly correlated with the corresponding tree representation displayed inFigure 6.


The code fragment depicted inFigure 5exemplifies a public method called setAttributes. In the GAST, this method is represented within the modifier tag with a value of public. Additionally, the GAST represents the return type of the method as void within the returnType tag. The method name, setAttributes, is represented as a leaf node in the GAST within the identifierName branch.
InFigure 6, the formalParameters branch of the GAST displays a single offspring representing the parameter of the function described in the code fragment, which is also illustrated in the same Figure. The parameter’s name in the source code, identifierName, is represented as a leaf node within the GAST under the attributes section of the function. Additionally, the function body contains an expression involving left and right operand operators, both of which are listed under the subStatements branch in the GAST.
The code fragment serves as an illustrative example of mapping source code to the GAST structure, and the aforementioned statements facilitate a manual examination of the syntactic components of the setAttributes function. However, relying solely on manual verification is time-consuming, error-prone, and may lead to overlooking certain issues. To address this limitation, the technique incorporates a mapping validator that automates the verification process.
Figure 7, similar toFigure 8, depicts the source code mapped to the corresponding GAST structure. The same tests conducted on previous examples were also applied to this specific sample, ensuring consistency and enabling a comprehensive evaluation of the GAST’s ability to accurately represent the syntactic components and structures of the source code.
Although the process of syntactic verification for the two trees is time-consuming, it is essential to establish the equivalence between the SASTs of each language and the GAST (as shown inTable II). The lack of parallelism in the procedure significantly contributes to the prolonged duration of the study. Currently, the analysis is performed in serial mode, sequentially checking each file, which consumes a considerable amount of time.
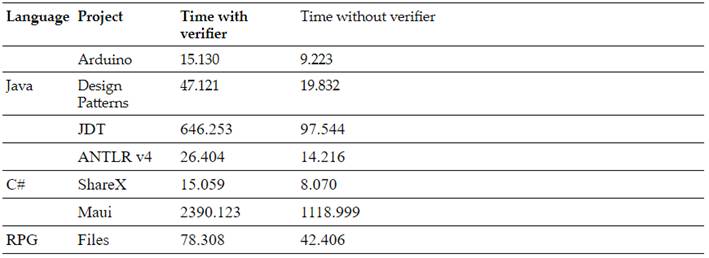

However, the results demonstrate the effective conversion of source code in the supported languages into the GAST, even for large projects like JDT, which encompasses over 8.000 files.
B. Homogenizing the analysis
This experiment aims to demonstrate the feasibility of standardizing the analysis of program constituents and grammatical structures across different programming languages. The experimental procedure is outlined as follows:
Develop two applications, one in Java and another in C#, with identical functionality.
Create Specific Abstract Syntax Trees (SASTs) for each program, corresponding to Java and C#.
Verify the similarity between the resulting Generic Abstract Syntax Trees (GASTs) generated for Java and C#.
Evaluate the results of code clone analysis when applied to the generated GASTs.
To illustrate this experiment, a representative chess game code was implemented in both Java and C# to showcase the analysis of the representation rather than the original syntax of the programs. The objective is to transform equivalent programs written in different programming languages into a generic syntax, enabling their analysis.
The chess program’s architecture incorporated abstract classes and object arrays, utilizing class inheritance and association. This design choice adds complexity to the transformed GAST structure and enhances its ability to accurately represent real-world development programs.

For the purpose of comparison, the clone detection metric, capable of distinguishing Type I, U, and HI clones(22)(with our research focusing on evaluating Type H clones), was implemented.Figures 9and10present an excerpt of a clone found in the Java version, corresponding to the C# version of the program.
Table IIIlists the significant clones identified by the clone detector, excluding set and get methods. All identified clones were discovered in both the C# and Java versions of the Chess project using the GAST representation. The source code for both versions and the identified clones can be found at https://github.com/JasonLeiton/Ajedrez.
The results demonstrate that the GAST representation of both programs effectively identified clones, yielding reliable outcomes. This outcome supports the notion that analysis can be standardized by utilizing a universal structure to generate equivalent representations across various programming languages. As such, the development of a unified analyzer capable of operating with multiple programming languages and facilitating cross-language comparisons becomes a feasible endeavor with the utilization of this abstract syntax.


C. GAST applications
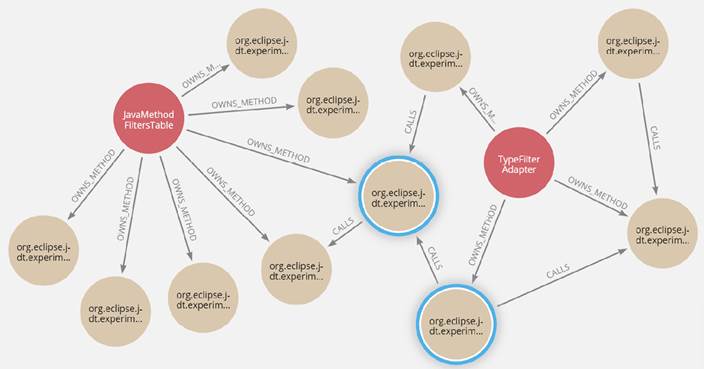
The conversion of source code from a specific programming language to a universal language enables the evaluation of software quality and maintainability. In our study, we conducted an analysis of the JDT project to generate code analysis tests for key applications. The resulting JDT GAST was stored in a Neo4j database, a graph-oriented database that facilitates the visualization of classes, methods, and relationships, and enables the calculation of various metrics.
To determine the indirect connections between nodes, we devised metrics that capture the methods of classes and establish associations between them(23).Figure 11illustrates two distinct classes, JavaMethodFiltersTable and TypeFilterAdapter, each with methods that call other methods, allowing us to establish two types of associations. The first type, CALLS, signifies that one method in the code invokes another method. The second type corresponds to OWNS_METHODS, indicating that the method is a member of the class.
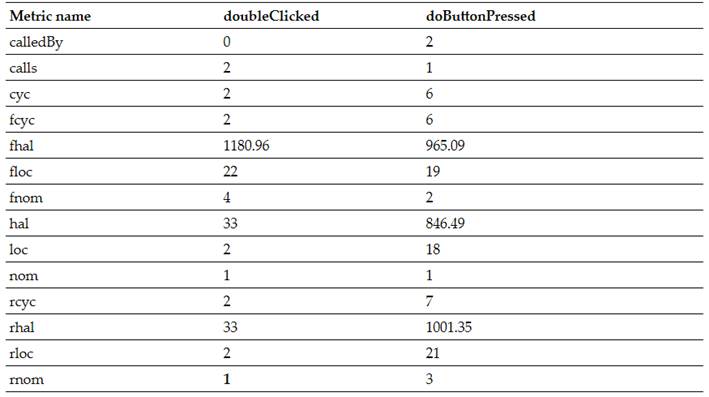
Moreover, employing a universal language analysis enables the collection of quantitative and analytical software measurements. Examples include metrics such as lines of code (LOC), methods called (CALLS), methods being called by other methods (CALLED BY), and cyclomatic complexity (CYC). The work by Navas-Su et al.(23)provides detailed explanations of how these metric values were computed.Table IVpresents the results of each metric for the two JDT approaches.
The primary objective of gathering these metrics is to enhance software maintainability and facilitate informed decisionmaking to ensure positive effects of code modifications. Cyclomatic complexity (CYC), a particularly relevant metric, provides insights into the extent of a method’s utilization within a software project. This understanding allows for an assessment of the potential impact of modifying, eliminating, or creating a new method that depends on others (or vice versa), and can assist in identifying ineffective approaches.
Furthermore, the application of GAST in academic settings offers additional benefits, particularly in supporting programming instructors and guiding students. GAST automates the examination of various aspects of computational thinking, including flow control, data representation, problem decomposition, and the identification of common programming errors. As a result, it can effectively contribute to student assessments. By leveraging GAST, instructors can assess and evaluate students’ levels of computational proficiency, providing valuable assistance in teaching activities. This automated evaluation process enhances efficiency and ensures consistent, objective assessment criteria, benefiting both students and educators.
V. CONCLUSIONS
The evaluation of software quality heavily relies on source code analysis, which traditionally requires the development of language-specific metrics to accommodate the unique syntax of each programming language. In this paper, we propose an alternative approach by introducing a universal structure based on the MOF 2.0 specification.
This universal structure serves as a representation for multiple abstract syntax trees from various programming languages. Its design emphasizes extensibility, allowing for the inclusion of new languages and enabling comprehensive support for quality control and software maintenance tasks.
The adoption of a universal representation for multiple programming languages contributes to standardizing the field of software analysis. By creating metrics once for all languages, this approach offers the advantage of reusability as new languages are integrated into the universal structure, enhancing flexibility in analysis.
The Generic Abstract Syntax Tree (GAST) plays a crucial role in establishing equivalence among elements from diverse programming languages. This allows for consistent analysis techniques to be applied across languages belonging to different paradigms. By utilizing a single structure with adaptable metric definitions, it becomes possible to compare the behavior of components in RPG, Java, C#, and other languages. Even though these components may differ, it can be demonstrated that they are substantially equivalent, and metrics can be derived accordingly for software developed in various languages.
However, the method’s limitation lies in the conversion process from language-specific Abstract Syntax Trees (ASTs) to the GAST, as it relies solely on the structure of the AST.
Each language requires a unique mapping procedure, specifying equivalence criteria for every syntactic element. To ensure accurate transformation of all syntactic elements into the GAST the other modules that use the GAST do not need to verify the completeness of the syntactic elements due because they are checked during the process of constructing the transformer.
The results obtained showed that the validation of the mapping is a time-consuming task. However, it represents an advantage because the other modules that use the GAST do not need to verify the completeness of the syntactic elements due to the checking performed when building the transformer.
The outcomes of our study clearly demonstrate the GAST’s efficacy in facilitating program analysis, cross-language code comparisons, and educational assessments. This research paves the way for the development of advanced source code analyzers, software metric collection and calculation tools, and training resources that seamlessly operate across multiple programming languages.
VI. FUTURE WORK
The GAST serves as a foundational framework for various ongoing initiatives within our research team. To thoroughly validate and understand its potential limitations and challenges, we are actively converting source code from different languages to the GAST and conducting comprehensive studies.
Exploring the reverse process of generating source code from the general abstract syntax tree and producing code in specialized languages is a topic of future investigation. Currently, the GAST structure is successfully used to generate code in Java, C#, and Python. This opens up possibilities for the development of many-to-many language translators, enabling code generation in multiple target languages from a single GAST representation.
To expedite the syntactic verification process for the two trees, we propose the incorporation of parallelism into the analysis workflow. By leveraging the computational power of modem systems, parallel processing can be employed to simultaneously analyze multiple files. This approach efficiently distributes the workload across threads or processors, resulting in faster analysis and significantly reduced turnaround time. Harnessing the potential of parallelism enhances the speed and efficiency of analysis, ultimately improving the overall effectiveness of the verification task.
The GAST project also finds utility in the analysis of malware code. Decompiling binary files and converting them to GAST representation allows for the extraction of associated assembly code. By employing search algorithms, it becomes possible to identify coding patterns associated with malicious code, enabling early detection of malware.
Furthermore, the GAST serves as the foundation for a novel initiative in clone detection across programs written in different languages or different versions of the same language. Our experiments involve improved meta data and semi-structural code-to-code comparisons, utilizing deep learning techniques for resemblance analysis of digital images derived from GAST representations, and structural GAST-based similarity analysis.

