











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
A partir del concepto de red eléctrica inteligente en la actualidad para llegar a una red eficiente y confiable se han generado varias etapas y subetapas con una misión definida y concreta. Así tenemos que la etapa de medición inteligente conformada por los medidores inteligentes obtiene la información de consumo eléctrico de los usuarios o consumidores (residenciales, comerciales e industriales), para esto se ha generado una infraestructura de medición inteligente que a partir de telecomunicaciones inalámbricas y de fibra óptica permite garantizar la conectividad de los medidores inteligentes y la oficina central de las empresas eléctricas según lo demuestran (Campaña, Inga, & Hincapié, 2017; Esteban Inga, Céspedes, Hincapié, & Cárdenas, 2017; Juan Inga, Inga, Hincapié, & Cristina, 2017; Arturo Peralta, Inga, & Hincapié, 2017). La información recolectada de millones de medidores inteligentes es almacenada en silos de información para su respectivo análisis y minería de datos para conocer el patrón de comportamiento eléctrico de cada usuario y con esta información tener una respuesta a la demanda más confiable con la cual se podrán a posteriori reducir los costos por generación, ya que al conocer el patrón de consumo se genera electricidad en estrecha relación con lo que se va a utilizar y se minimizan las pérdidas de energía (Inga-ortega, Inga-ortega, & Gómez, 2017).
Entonces, se prevé que la infraestructura de medición inteligente está estrechamente relacionada al sistema de gestión de datos medidos; es donde la cantidad de información va tomando una real importancia y un problema no trivial que requiere de un tratamiento de información con el menor costo por los recursos empleados en el proceso de tratamiento de información (E. Inga & Hincapié, 2016).
Para transportar la información desde los medidores inteligentes, se han generado modelos de planeación de redes inalámbricas heterogéneas representadas en un multigrafo-multicapa para llevar información con la mejor cobertura de los medidores inteligentes y considerar tecnologías de bajo costo en relación con otras opciones como la red celular, la misma que es limitada por la falta de cobertura en zonas suburbanas y rurales. En este sentido, el despliegue óptimo de una red inalámbrica a través de multisalto (Lichtensteiger, Bjelajac, Müller, & Wietfeld, 2010) ha sido considerado como la mejor opción, incluso en relación con trabajos iniciales que proponen el uso híbrido de fibra y red inalámbrica donde el costo por despliegue de una red soterrada de fibra óptica encarece la inversión para ser tomada en cuenta para una medición inteligente de energía eléctrica, esto se aprecia en el trabajo de (Inga-Ortega, Peralta-Sevilla, Hincapié, Amaya, & Tafur Monroy, 2015; J. Inga, Inga, Hincapié, & Gómez, 2016; A Peralta, Inga, & Hincapié, 2015).
De esta manera, una infraestructura de medición inteligente al articularse con el sistema de gestión de datos medidos en sus diferentes topologías como: centralizada, semi distribuida y totalmente distribuida que permiten optimizar el uso de la capacidad de la red de comunicaciones ya que en esta etapa de MDMS se puede reducir información poco relevante para la toma de decisiones (Moscoso-zea & Lujan-mora, 2017) y que no requiere de su transporte. En el MDMS también se articulan los procesos de encriptación y seguridad de información debido al uso de la información importante y que pudiera ser usado para fines delincuenciales por la importancia de conocer los detalles del patrón de consumo de energía de un usuario (Wan, Wang, Yang, & Shi, 2014),(Arian, Ameli, Soleimani, & Ghazalizadeh, 2011; Zhou, Hu, & Qian, 2012).
Es así que la cantidad de información almacenada con el consumo de energía de los usuarios superan los gigabytes(Correa, Inga, Inga, & Hincapié, 2017), lo cual incide en la necesidad de buscar un proceso computacional en paralelo que permita reducir el costo en término de recursos empleados por el tiempo empleado en este tipo de tratamiento de información; en otras palabras, hacer uso de una técnica de minería de datos nos facilita reducir los tiempos en procesamiento de información y por consiguiente obtener un rápido reporte por análisis para una subsiguiente toma de decisiones para mejorar la respuesta de la demanda de acuerdo con lo propuesto por (Ahmed, 2014; Grolinger, Capretz, & Seewald, 2016; X. Liu, Golab, Golab, & Ilyas, 2015; Munshi & Mohamed, 2017).
La Figura 1 muestra el esquema conceptual de la técnica de MapReduce para reconstruir el patrón de consumo de energía eléctrica de la información que fuera previamente tratada y almacenada por el MDMS.
En adelante este artículo se organiza de la siguiente manera. En la Sección 2 se introducen los fundamentos de MapReduce en medición inteligente de energía eléctrica. En la Sección 3 se plantea la formulación del problema. En la Sección 4 se realiza el análisis de los resultados a partir de métricas y tendencias. Finalmente, en la Sección 5 se concluye este artículo.
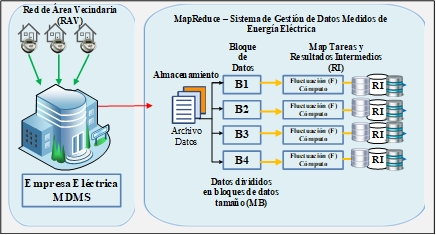
2. Procesamiento de datos paralelo en el Sistema de Gestión de datos medidos
Un sistema de gestión de datos medidos en cualquiera de sus topologías alberga una gran cantidad de información, lo cual genera información histórica con el comportamiento del consumo de energía de todos los usuarios del sistema eléctrico. Por esta razón, se advierte una posibilidad para la minería de datos que permita seleccionar, filtrar, leer y analizar la información recolectada desde los medidores inteligentes aporte sustancial de este trabajo.
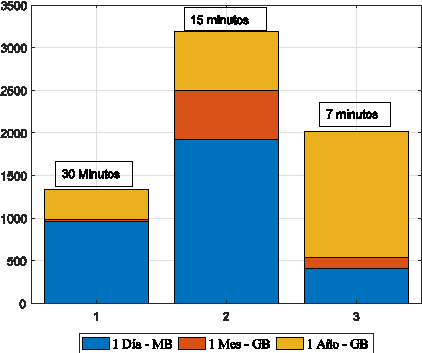
Para contemplar la necesidad de realizar un proceso en paralelo es importante justificar que el crecimiento de la información en un MDMS realmente cumple con las características de big data; por lo tanto, si se consideran medidores inteligentes de energía eléctrica con intervalos de lectura cada 15 minutos, en 24 horas se tendría 96 lecturas por día y en un mes 2880 lecturas. Además, si se considera que cada lectura representa 5 bytes; en un escenario de 4’000.000 de abonados, al multiplicar por 5 bytes genera una cantidad aproximada a 20’000.000 bytes por lectura. La Tabla 1 muestra el crecimiento de la información para un intervalo entre cada lectura.

De los datos preliminares se puede apreciar que el crecimiento de la información es considerable, más aún si se requieren obtener reportes de esa cantidad de datos de manera eficiente para una posterior toma de decisiones.
La medición inteligente puede incluir ciertas variaciones respecto de la decisión del intervalo de lectura del suministro eléctrico, en este caso podría ser inferior o superior a los 15 minutos antes mencionados. Esta decisión la estipula la empresa de distribución eléctrica en virtud de requerir una información en un intervalo reducido según las necesidades vinculadas al sistema de gestión de datos medidos, en caso de no requerir un intervalo reducido puede optar por 30 minutos. Sin embargo, empresas eléctricas advierten que la medición inteligente podría a futuro requerir una lectura de tiempo real, este particular encarece el sistema tanto a nivel de red de comunicaciones como en almacenamiento y procesamiento de información.
En la Figura 2 se muestra un análisis de datos con lecturas cada 7 minutos, se obtiene un total de 206 lecturas diarias. Si se toman como referencia lecturas cada 15 minutos, se tiene un total de 96 lecturas diarias. Finalmente, con lecturas cada 30 minutos, se tiene 48 lecturas diarias. Si advertimos un número de 4 millones de clientes, caso ecuatoriano, provocaría el verdadero efecto de Big Data; el almacenamiento; entonces, el tratamiento de la información tiene mucha validez para las empresas eléctricas especialmente en la toma de decisiones, patrón de consumo eléctrico y la respuesta de la demanda, para esto se debe recordar que una generadora no cuenta con almacenamiento de energía y su generación se da a partir de la demanda por lo cual conocer el patrón de comportamiento de los usuarios reduce costos por generación eléctrica. Los valores en color azul se encuentran en MB; mientras que en color anaranjado y rojo en GB.
Un MDMS integra y almacena información de una medición inteligente; por lo tanto, lo que se aprecia es una necesidad de escalabilidad en cuanto al almacenamiento y procesamiento de la información y al crecimiento de los recursos físicos; pero el problema de este trabajo se centra en la gestión misma de la información previamente almacenada en silos. Esta información requiere de un tiempo oportuno con la finalidad de obtener los reportes y/o estadísticas para determinar el comportamiento del consumo de energía eléctrica, y a partir del empleo de MapReduce como técnica para manejo de big data que a través de programación paralela o paralelismo incrementa el rendimiento computacional y reduce los costos por procesamiento como exprensan (Chihoub & Collet, 2016; Dai, Chai, Qiu, Zhang, & Jiang, 2016; Han & Yang, 2016; Shi et al., 2016; Zhang, 2017).
El modelo de programación MapReduce propone una función map que se encarga de procesar en partes la información, pero identificadas con una llave/valor que genera un conjunto de llave/valor intermedio y a través de la función reduce se encarga de unir o fusionar todos los valores intermedios asociados con la misma llave intermedia, este trabajo es paralelizado de manera automática. Es decir, la información es fragmentada con un identificador con el fin de reducir el tiempo de procesamiento ya presentado por (Lang & Patel, 2010; Selamat, 2016; Sieverts & Systems, 2015; Vaccaro, Troiano, Vaccaro, & Vitelli, 2016; Wang, 2014; Yildiz, Ibrahim, Phuong, & Antoniu, 2015).
MapReduce presenta una característica importante para resolver este tipo de problemas debido a su programación escalable, capaz de procesar un volumen masivo de información preveniente de la medición inteligente de energía eléctrica bajo una ejecución en un gran número de nodos de computo de productos (Ahmed, 2014; Fanibhare & Dahake, 2016; Grolinger et al., 2014, 2016; R. Liu, Kuo, Yang, Chen, & Liu, 2016; Mashayekhy, Member, Nejad, & Member, 2015; Nghiem & Figueira, 2016).
3. Formulación del problema
El problema de gestión de big data en MDMS requiere de un proceso recursivo en paralelo que permita adquirir el total o parte de la información según sean los requerimientos por el análisis o reportes deseados para la posterior toma de decisión de la respuesta de la demanda eléctrica; por lo tanto, el análisis de big data proveniente de medición inteligente de energía eléctrica no es un problema trivial, requiere una gestión de la información que responda de manera oportuna y escalable y que permita realizar una asignación de recursos con el menor costo, considerando las restricciones de capacidad de cada MDMS, a través de un adecuado gestor de reportes que permita obtener las tendencias del comportamiento del consumo eléctrico.
El algoritmo GDM-Mapreduce toma como entrada un archivo de extensión csv que tiene aproximadamente 11Gb de tamaño y lo almacena en la variable denominada ds. Esta variable contiene el criterio incorporado de búsqueda; a partir de ese momento todas las referencias de programación se orientan hacia la variable ds. Posteriormente, se debe preparar estos datos para ser mapeados; es decir, se debe dejar lista la data (sin espacios en blanco dentro de los campos) para que forme paquetes de datos más pequeños y pueda trabajar de forma oportuna. Se hace uso de las funciones propias de MapReduce para crear los paquetes mediante el método de clave-valor. La Tabla 2 muestra las variables presentadas por el algoritmo.
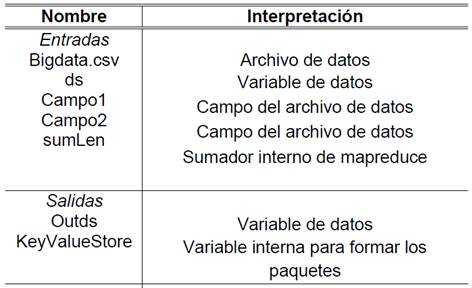
Una vez formado el paquete (mapeado) se procede con la etapa reduce que se encarga de realizar las operaciones y a su vez guardar los resultados parciales para posteriores cálculos. Este proceso se vuelve a iterar hasta que se termine con todos los datos almacenados en el ds. El pseudocódigo del algoritmo GDM-Mapreduce se presenta en la Figura 3. Es importante tener en cuenta que las restricciones o criterios de selección que formarán un subconjunto de registros que se requieren analizar, incurrirán en un mayor tiempo de gestión de mapreduce, es decir a más restricciones de búsqueda el algoritmo empleará mayor tiempo de procesamiento y por tanto, mayor consumo de energía empleado en el proceso.

4. Análisis de resultados
La construcción de un proceso recursivo en paralelo ha permitido que el tiempo computacional sea reducido en función del tratamiento de la información deseada, de esta manera se estima que existen procesos que pueden tomar un tiempo mayor o menor según el análisis a realizar. Este trabajo ha encontrado como aporte sustancial que un proceso que retarda o minimiza el tiempo de procesamiento se encuentra en la etapa de filtro de la información; por lo tanto, a más restricciones del espacio de búsqueda el tiempo de procesamiento se incrementa. El trabajo ha sido elaborado usando datos del orden de 11GB y procesado bajo entorno de Matlab del cual se obtienen resultados claros y pertinentes para el análisis de la respuesta de la demanda de energía eléctrica como se detallan a continuación en la Figura 4.
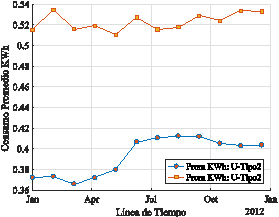
En la Figura 4 se visualiza el comportamiento del consumo promedio en KWh respecto de la variación en la línea del tiempo, obtenidos a partir de la técnica de mapreduce que permite a partir de datos históricos conocer la variación del consumo de energía; esto se puede aplicar a los tipos de clientes de cada empresa de distribución eléctrica y generar un análisis de demanda de energía en función de los datos históricos, de esta manera se consigue una línea de tendencia determinística para la respuesta de la demanda de energía eléctrica, que permitiría reducir los índices de generación eléctrica, al trabajar únicamente sobre la demanda debido a que el costo por energía no consumida es significativo para una empresa generadora.
En la Figura 5, la variación de registros que fueron efectuados a los medidores inteligentes para el usuario tipo1, se puede apreciar el patrón de consumo de energía obtenidos de 11GB de información en un proceso de big data mediante mapreduce.
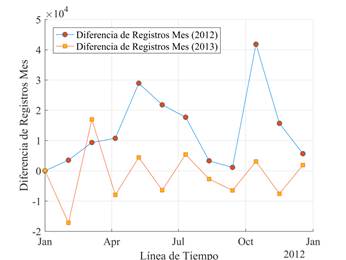
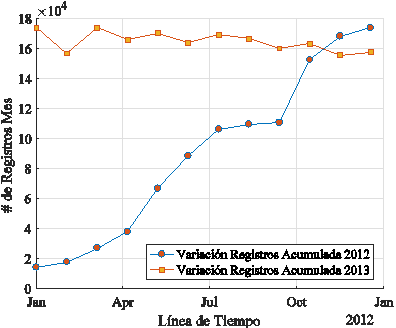
En la Figura 6 se presenta la variación de registros que fueron efectuados a los medidores inteligentes para el usuario tipo 1 en cada mes. Se puede apreciar que no tiene un comportamiento singular o uniforme en el número de muestras recolectadas, entonces se tiene meses en donde el número de registros fue mayor que otros meses en el mismo año.
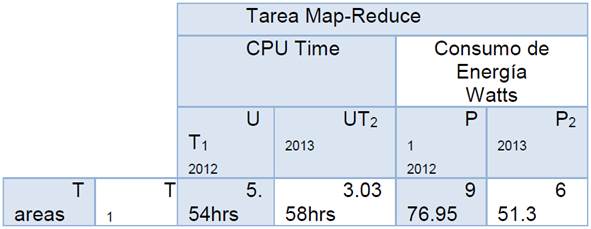
En la Tabla 3 se presentan el tiempo de procesamiento y el consumo de energía de la etapa mapreduce para una big data de 11GB, obtenidas a partir de un caso de estudio aplicado a la big data de uso libre obtenido del sitio Web London Data Store. Ver (Networks, 2017). En la tabla se observa el tiempo requerido por la técnica mapreduce para explorar y extraer la información de tres tipos de usuarios de energía eléctrica referidos por tipo1 UT1- 2012, tipo2 (UT2) - 2013; adicionalmente, se presenta el consumo de energía en cada proceso P1-2012, P2 - 2013 en watts. El número de registro evaluados fueron 1’074.204 distribuidos de forma no uniforme entre doce meses. En el transcurso se ha identificado que la big data analizada tenía un registro cada 30 segundos, muchos de esos registros tuvieron un valor 0, debido a las fallas del sistema de comunicaciones empleado o por un desperfecto del medidor inteligente. El ordenador utilizado para ejecución del algoritmo tiene un procesador I7, 3.4GHz-Procesador, 8MB-RAM, 19.5V, 3.34-Amp y desarrollado bajo entorno Matlab R2016b.
5. Conclusiones y recomendaciones
Un comportamiento del patrón de consumo eléctrico puede ser analizado a partir de la gestión de los datos históricos almacenados, proveniente de la medición inteligente de energía eléctrica; el patrón de comportamiento permite proyectar de forma determinística el comportamiento de años futuros del consumo de energía eléctrica.
La investigación muestra cómo la técnica de Mapreduce, a través del proceso “divide y vencerás” con una data de 11GB de información, logra obtener resultados de grandes cantidades de datos que no se pueden leer en un proceso simple debido a las limitaciones de memoria.
Una técnica como MapReduce aplicada al manejo de big data construida por datos históricos de medición inteligente de energía eléctrica presenta una gran opción para mejorar el rendimiento y así reconstruir el patrón de consumo de energía y optimizar el proceso de gestión de la información requerida en la toma de decisiones y respuesta de la demanda de energía eléctrica.
Futuros trabajos plantearán un análisis para optimizar los criterios de búsqueda asociados a la técnica de mapreduce, esto permitirá reducir aún más los tiempos de procesamiento.

