











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1. Introducción
En la actualidad, los controladores son implementados usando sistemas computacionales en los cuales la tarea de control comparte recursos de procesamiento y red con otras tareas. El muestreo periódico establece que la tarea de control se debe ejecutar (disparar) en función del tiempo, es decir, cada vez que el período de muestreo se cumple, incurriendo a menudo en la sobreutilización de recursos (Astrom, 1999). Sin embargo, los esquemas no periódicos de muestreo pueden ser más efectivos que los periódicos, al balancear el rendimiento de control en lazo cerrado (calidad de control) en función de la utilización de recursos (Gommans, 2015).
Dos tipos de aproximaciones que abandonan el paradigma de control periódico son el control disparado por eventos (ETC, Event-Triggered Control) y el control auto-disparado (STC, Self-Triggered Control), (Heemels, 2012). El primero es reactivo y requiere de la ejecución de la tarea de control cuando algún estado de la planta sobrepasa cierto valor de umbral (Arzén, 1999). El segundo calcula previamente cuándo será la próxima vez que la tarea de control se debe ejecutar (Velasco, 2003). Tanto ETC como STC se componen de dos elementos: un controlador con realimentación que calcula la entrada de control, y un mecanismo de disparo que determina cuándo debe actualizarse de nuevo esta entrada de control.
El presente artículo se centra en analizar reglas para muestreo aplicadas en STC, direccionadas a producir secuencias de entradas de control con costo menor o igual que el costo óptimo, el cual corresponde al mínimo dado por el regulador cuadrático lineal (LQR, Linear Quadratic Regulator) de tiempo discreto (Astrom, 1997). El problema de la regla para muestreo óptimo ha sido recientemente abordado en (Rabi, 2008), (Velasco, 2011), (Meng, 2012), (Molin, 2013), (Bini, 2014), (Gommans, 2014) y (Velasco, 2015), cuya contribución ofrece formulaciones factibles en diferentes entornos, a la vez que identifica posibles limitaciones en términos de optimalidad, tratabilidad computacional y/o aplicación práctica. Sin embargo, dentro de la literatura existente, no se encuentra un marco comparativo o una metodología para evaluar sus propiedades.
Para superar esta limitación el presente trabajo considera dos enfoques de STC, (Gommans, 2014) y (Velasco, 2015), con el objetivo de identificar los aspectos claves que una metodología de comparación debe tener en cuenta para la evaluación del rendimiento. La contribución de este trabajo consiste en presentar un análisis comparativo de las dos aproximaciones, donde el rendimiento de control y la utilización de recursos son las principales métricas de interés. Además, el equilibrio inherente entre rendimiento y utilización es la base para establecer la metodología utilizada en el análisis comparativo de desempeño. Los resultados obtenidos a través de simulaciones revelan sus posibles beneficios y limitaciones, a la vez que permiten extraer lineamientos para el diseño futuro de nuevas reglas de muestreo óptimo.
El resto del documento está estructurado de la siguiente manera. La Sección 2 presenta la base teórica necesaria para comprender los dos enfoques de control; muestra las pautas a seguir para desarrollar el análisis comparativo. La Sección 3 ilustra numéricamente la evaluación de rendimiento y muestra la discusión de los resultados. Finalmente, la Sección 4 concluye el manuscrito.
2. Metodología
En adelante, la aproximación en Gommans (2014) llamada control cuadrático lineal auto-disparado (Self-Triggered Linear Quadratic Control) se citará como STLQ. La aproximación en Velasco (2015), llamada control auto-disparado inspirado en muestreo óptimo (Optimal-Sampling-Inspired Self-Triggered Control), se mencionará como OSIST.
Ambos enfoques de STC consideran un sistema lineal continuo invariante en el tiempo (LTI, Linear Time-Invariant), regido por
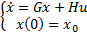 (1)
(1)
donde 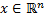 es el vector de estados y
es el vector de estados y  es el vector de señales de entrada,
es el vector de señales de entrada, 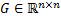 y
y 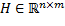 son matrices que describen la dinámica del sistema, y
son matrices que describen la dinámica del sistema, y 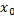 es el vector de estados iniciales.
es el vector de estados iniciales.
Una diferencia fundamental entre STLQ y OSIST, consiste en que el primero contempla el trabajo bajo condiciones de ruido. Sin embargo, el estudio desarrollado a través de este artículo no lo considera, ya que ambos enfoques presentan contribuciones comparables para el caso de condiciones ideales.
La señal de entrada de control continua 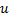 en (1) está limitada a ser constante a trozos,
en (1) está limitada a ser constante a trozos,
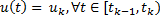 ,
(2)
,
(2)
donde  es la entrada de control en tiempos discretos
es la entrada de control en tiempos discretos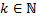 , y
, y 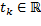 simboliza los instantes de muestreo. El patrón de muestreo está representado por los valores que separan dos instantes consecutivos llamados intervalos de muestreo
simboliza los instantes de muestreo. El patrón de muestreo está representado por los valores que separan dos instantes consecutivos llamados intervalos de muestreo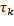 . Los instantes de muestreo y los intervalos de muestreo están relacionados entre sí a través de
. Los instantes de muestreo y los intervalos de muestreo están relacionados entre sí a través de
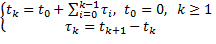 (3)
(3)
El problema óptimo LQR de horizonte infinito en tiempo continuo contempla la búsqueda de una señal de entrada que minimiza la función de costo
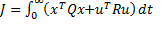 (4)
(4)
considerando las matrices 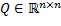 positiva semidefinida, y
positiva semidefinida, y 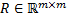 positiva definida. Para el control LQR de horizonte infinito en tiempo discreto, se pueden usar formas discretas conocidas (Astrom, 1997).
positiva definida. Para el control LQR de horizonte infinito en tiempo discreto, se pueden usar formas discretas conocidas (Astrom, 1997).
En el muestreo periódico se tiene 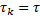 para todos los
para todos los 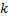 , donde
, donde 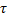 es el período de muestreo. A través de técnicas de discretización usuales (Astrom, 1997), y considerando
es el período de muestreo. A través de técnicas de discretización usuales (Astrom, 1997), y considerando
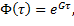 (5)
(5)
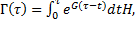 (6)
(6)
la dinámica (1) puede ser descrita por el sistema LTI en tiempo discreto
 (7)
(7)
donde 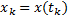 es el estado muestreado en
es el estado muestreado en 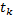 . La ecuación (4) puede describirse como un problema óptimo LQR de horizonte infinito en tiempo discreto,
. La ecuación (4) puede describirse como un problema óptimo LQR de horizonte infinito en tiempo discreto,
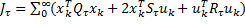 (8)
(8)
con las matrices 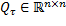 positiva semidefinida,
positiva semidefinida, 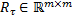 positiva definida y
positiva definida y 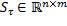 , todas obtenidas a través de discretizaciones conocidas (Astrom, 1997).
, todas obtenidas a través de discretizaciones conocidas (Astrom, 1997).
2.1. Enfoques de control auto-disparado
En STLQ y OSIST, tanto la regla de muestreo como la entrada de control a trozos se resuelven minimizando el costo LQR. La regla de muestreo genera intervalos de muestreo según el estado muestreado 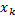 y un conjunto de parámetros. La entrada de control consiste en una ganancia calculada para trabajar durante el intervalo y depende además del estado muestreado .
y un conjunto de parámetros. La entrada de control consiste en una ganancia calculada para trabajar durante el intervalo y depende además del estado muestreado .
2.1.1. Control Cuadrático Lineal Auto-Disparado (STLQ)
Esta aproximación presenta una regla de muestreo inspirada en el problema clásico LQR de tiempo discreto que busca mantener constante cada entrada de control durante el mayor número de pasos posible, ampliando así cada intervalo de muestreo, y garantizando un rendimiento de control (Gommans, 2014). Esta garantía de rendimiento se da en términos de una función de costo LQR de tiempo discreto; las muestras se activan de acuerdo con una degradación permisible, especificada en el costo LQR y limitada por un intervalo de muestreo mínimo dado.
La regla de muestreo puede ser descrita a través de una notación diferente a la original, así
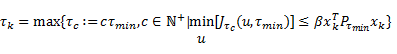 ,
(9)
,
(9)
considera una función de costo
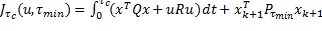 (10)
(10)
El cálculo de en (9) busca maximizar el intervalo de muestreo actual  (múltiplo del intervalo de muestreo mínimo
(múltiplo del intervalo de muestreo mínimo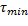 dado) durante el cual se aplica una señal de control constante . El valor específico de debería incurrir en un costo (10) menor que
dado) durante el cual se aplica una señal de control constante . El valor específico de debería incurrir en un costo (10) menor que 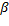 veces el costo mínimo que obtendría un controlador periódico LQR de tiempo discreto, con intervalo de muestreo , donde
veces el costo mínimo que obtendría un controlador periódico LQR de tiempo discreto, con intervalo de muestreo , donde 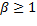 . En (9),
. En (9),  es la única solución semidefinida positiva a la ecuación algebraica discreta de Riccati (DARE, Discrete Algebraic Ricatti Equation) del costo cuadrático discreto (8) para periódico. El primer sumando en (10), el término integral, es el costo cuadrático en tiempo continuo (4) sobre el intervalo de muestreo actual. El segundo sumando en (10), es el costo al suponer que las muestras restantes, después del intervalo de muestreo actual, se realizan periódicamente con .
es la única solución semidefinida positiva a la ecuación algebraica discreta de Riccati (DARE, Discrete Algebraic Ricatti Equation) del costo cuadrático discreto (8) para periódico. El primer sumando en (10), el término integral, es el costo cuadrático en tiempo continuo (4) sobre el intervalo de muestreo actual. El segundo sumando en (10), es el costo al suponer que las muestras restantes, después del intervalo de muestreo actual, se realizan periódicamente con .
Además, esta aproximación sugiere que la señal de control, para un intervalo de muestreo dado , es descrita por
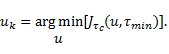 (11)
(11)
En el documento original (Gommans, 2014) se proporciona una expresión alternativa para (11) que tiene una forma estándar de retroalimentación lineal de estados 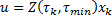 donde la ganancia
donde la ganancia 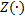 cambia en cada ejecución del controlador. Sin embargo, por propósitos de comparación, la expresión dada en (11) ha sido considerada la más adecuada.
cambia en cada ejecución del controlador. Sin embargo, por propósitos de comparación, la expresión dada en (11) ha sido considerada la más adecuada.
2.1.2. Control Auto-Disparado Inspirado en Muestreo Óptimo (OSIST)
Establece una regla de muestreo que genera entradas de control de tal manera que la señal de control a trozos resultante, se aproxima a la entrada de control LQR de tiempo continuo, proporcionando un muestreo más denso cuando la señal de control exhibe más variación. La garantía de rendimiento se da en términos de densidad de muestreo, definida como el número de muestras a lo largo de un intervalo de tiempo (véase (Bini, 2014)). Las muestras se disparan de acuerdo con la derivativa de la entrada de control LQR de tiempo continuo y tienen como límite superior un valor máximo dado.
La regla de muestreo se sintetiza como
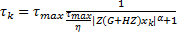 (12)
(12)
donde 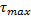 es el límite superior para los intervalos de muestreo,
es el límite superior para los intervalos de muestreo,  determina la densidad de la secuencia de muestreo (pequeños valores de producirán instantes de muestreo más densos, es decir muestras más frecuentes, y viceversa). El término
determina la densidad de la secuencia de muestreo (pequeños valores de producirán instantes de muestreo más densos, es decir muestras más frecuentes, y viceversa). El término 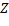 es la ganancia óptima de retroalimentación en tiempo continuo, obtenida al minimizar el costo cuadrático continuo (4). El parámetro
es la ganancia óptima de retroalimentación en tiempo continuo, obtenida al minimizar el costo cuadrático continuo (4). El parámetro  determina la distribución del conjunto de muestras, permitiendo la aparición de más muestras cuando la derivativa de la entrada de control LQR en tiempo continuo es mayor. Véase (Bini, 2014) para una discusión sobre los ajustes del parámetro
determina la distribución del conjunto de muestras, permitiendo la aparición de más muestras cuando la derivativa de la entrada de control LQR en tiempo continuo es mayor. Véase (Bini, 2014) para una discusión sobre los ajustes del parámetro 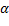 .
.
Además, este enfoque sugiere que la señal de control a trozos a ser aplicada en (2) para un intervalo de muestreo dado , es descrita por
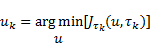 (13)
(13)
que es la señal de control óptima a trozos que se aplicaría al suponer un muestreo periódico con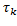 . La señal de control en (13) también puede expresarse usando una forma estándar de retroalimentación lineal
. La señal de control en (13) también puede expresarse usando una forma estándar de retroalimentación lineal 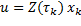 donde la ganancia cambia en cada ejecución del controlador y corresponde a la ganancia de retroalimentación óptima en tiempo discreto, encontrada al minimizar el costo (8) para un período de muestreo .
donde la ganancia cambia en cada ejecución del controlador y corresponde a la ganancia de retroalimentación óptima en tiempo discreto, encontrada al minimizar el costo (8) para un período de muestreo .
2.2. Análisis de rendimiento
STLQ se centra en ampliar los intervalos de muestreo, acepta cierta degradación en los costos y enfatiza la utilización de recursos. Además, OSIST se enfoca en producir una señal de control a trozos para imitar la entrada de control óptima continua y da importancia al rendimiento de control.
En la Tabla 1 se agrupan las ecuaciones (14) y (15) tomadas desde (Gommans, 2014), y las ecuaciones (16) y (17), desde (Velasco, 2015). Se usan para resumir las directrices de diseño, tanto para las reglas de muestreo , como para la entrada de control a trozos 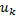 . A través de estas se pueden identificar los parámetros que afectan el funcionamiento en términos de utilización de recursos y rendimiento de control.
. A través de estas se pueden identificar los parámetros que afectan el funcionamiento en términos de utilización de recursos y rendimiento de control.

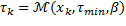 (14)
(14)
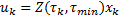 (15)
(15)
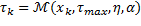 (16)
(16)
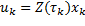 (17)
(17)
2.2.1. Condición inicial e intervalo de muestreo promedio
En STLQ se señala que en ausencia de ruido (caso bajo análisis), cualquier condición inicial a lo largo de un segmento 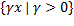 , conducirá a una misma secuencia de intervalos de muestreo. Dado que la ganancia del controlador es óptima, la dinámica dominante oscilará, lo que significa que los estados saltarán a través de diferentes rayos. Esto producirá un patrón de muestreo oscilatorio que para una ejecución suficientemente larga tendrá el mismo período promedio, independientemente de la condición inicial. Para una caracterización extendida de las secuencias de muestreo véase (Velasco, 2009).
, conducirá a una misma secuencia de intervalos de muestreo. Dado que la ganancia del controlador es óptima, la dinámica dominante oscilará, lo que significa que los estados saltarán a través de diferentes rayos. Esto producirá un patrón de muestreo oscilatorio que para una ejecución suficientemente larga tendrá el mismo período promedio, independientemente de la condición inicial. Para una caracterización extendida de las secuencias de muestreo véase (Velasco, 2009).
En la regla de muestreo de OSIST en (12), en estado de equilibrio (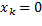 ), los intervalos de muestreo son lo más largos posible (
), los intervalos de muestreo son lo más largos posible (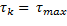 ). La tendencia consiste en obtener intervalos largos a medida que la dinámica de lazo cerrado se aproxima al equilibrio, así, si el estado inicial ya proporciona un intervalo largo, existe una alta probabilidad que la secuencia trabaje en el tope superior de valores. Por lo tanto, pueden alcanzarse intervalos de muestreo promedio más grandes.
). La tendencia consiste en obtener intervalos largos a medida que la dinámica de lazo cerrado se aproxima al equilibrio, así, si el estado inicial ya proporciona un intervalo largo, existe una alta probabilidad que la secuencia trabaje en el tope superior de valores. Por lo tanto, pueden alcanzarse intervalos de muestreo promedio más grandes.
El estado inicial más adecuado será el que para OSIST proporcione el período promedio más corto; el tiempo de ejecución deberá ser lo suficientemente largo como para permitir que ambos enfoques pongan al sistema de lazo cerrado en equilibrio.
2.2.2. Parámetros de muestreo
Con el fin de asegurar una comparación equitativa, es necesario que STLQ y OSIST generen intervalos de muestreo con límites inferior y superior. En la regla de muestreo (14), STLQ tiene un límite inferior , mientras que en (16), OSIST un límite superior . Por lo tanto, los intervalos de muestreo generados por STLQ deberían ser limitados en valor máximo, y los generados por OSIST, en valor mínimo.
En (14), también especifica la granularidad temporal del espacio de búsqueda para (véase (9)), limitando el conjunto de valores posibles que puede tomar. Sin embargo, esta limitación no se cumple para (16) donde puede tomar cualquier valor menor que . Así, se debe ajustar un valor pequeño para en la configuración del experimento.
Es necesario considerar que un intervalo de muestreo corto proporciona mejor rendimiento de control (menor costo), mientras que un intervalo de muestreo largo permite menor demanda de recursos (menor utilización). Alternativamente se puede usar el intervalo de muestreo promedio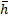 como una métrica de utilización de recursos, considerando
como una métrica de utilización de recursos, considerando
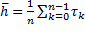 (18)
(18)
donde 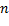 es el número de intervalos de muestreo en un período de tiempo determinado. Mediante la aplicación de restricciones en este valor, se evita distorsionar la operación original de cada regla de muestreo, con el fin de obtener resultados aptos para la comparación.
es el número de intervalos de muestreo en un período de tiempo determinado. Mediante la aplicación de restricciones en este valor, se evita distorsionar la operación original de cada regla de muestreo, con el fin de obtener resultados aptos para la comparación.
En (14), considerando que cuando se tiene un muestreo periódico cada existe un costo óptimo discreto, el factor de escalamiento especifica una degradación permitida con respecto a este costo. Se ajusta así un grado de suboptimalidad en términos de rendimiento de control, pero intrínsecamente, también se configura la demanda de recursos del controlador auto-disparado. Por lo tanto, al permitir una mayor degradación (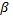 más grande) se obtiene un espacio de búsqueda más amplio para , el cual termina con intervalos de muestreo más largos.
más grande) se obtiene un espacio de búsqueda más amplio para , el cual termina con intervalos de muestreo más largos.
El factor de densidad en (16), regula la frecuencia de muestreo y consecuentemente afecta la utilización de recursos. Considerando que un muestreo más denso ( más pequeño) implica la producción de una señal de control a trozos más cercana a la óptima continua, especifica un grado de suboptimalidad en términos de rendimiento de control.
El parámetro de diseño en (16), permite realizar un ajuste extra en el rendimiento de control. Esta variable ajusta el muestreo de tal manera que se pueden producir más muestras ante una mayor variación de la derivada de la entrada de control óptimo continuo (Bini, 2014); para 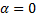 se obtiene un muestreo periódico.
se obtiene un muestreo periódico.
2.2.3. Señales de Control
Una vez calculado el intervalo de muestreo actual , la entrada de control a trozos 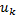 generada por (15) o (17), difiere solamente en la ganancia
generada por (15) o (17), difiere solamente en la ganancia 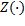 que se aplica. En la expresión de control para STLQ (11), la ganancia se calcula suponiendo que el resto de muestras después de la muestra actual, será igual a . En el control de OSIST (13), se supone que el resto de muestras será igual a la muestra actual .
que se aplica. En la expresión de control para STLQ (11), la ganancia se calcula suponiendo que el resto de muestras después de la muestra actual, será igual a . En el control de OSIST (13), se supone que el resto de muestras será igual a la muestra actual .
3. Resultados y Discusión
Esta sección ilustra numéricamente varias cuestiones discutidas en la Sección 2. Sobre una planta conocida, se aplican los criterios enunciados para evaluar el rendimiento de los dos enfoques de control auto-disparado. Además se presentan los resultados de este análisis comparativo.
3.1. Planta
La planta considerada es un sistema LTI que tiene la forma de (1) y consiste en un circuito electrónico doble integrador, tal como se describe en Astrom (1997). Su dinámica se representa a través de
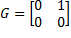 (19)
(19)

El costo (4) se caracteriza por las matrices de ponderación
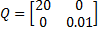 (20)
(20)

cuyos valores han sido elegidos para obtener gráficas lisas. En una función de costo LQR, la matriz Q define los pesos en los estados mientras que la matriz R especifica los pesos en la entrada de control. Se puede consultar Murray (2006) para mayor información sobre el ajuste de estas matrices.
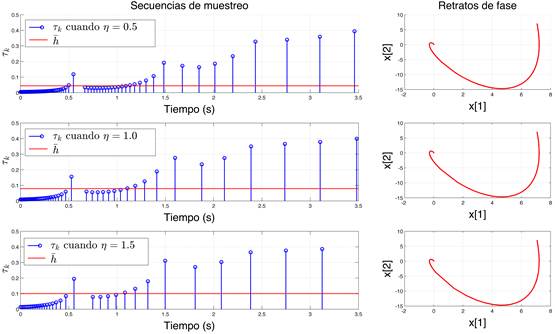
A continuación, en las Figuras 1 y 2 se observa el rendimiento de STLQ y OSIST respectivamente. Las gráficas de tallo en azul (Stems) representan las secuencias de muestreo. En el eje-x se encuentran representados los instantes en que cada muestreo se realiza durante el experimento, mientras que en el eje-y, la longitud de los tallos ilustra la magnitud de cada instante de muestreo . Además, las gráficas en rojo exhiben la evolución de los estados 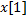 y
y  del sistema en (19). Estas representaciones en particular, son curvas paramétricas (con como parámetro) que trazan la trayectoria de cada particular solución
del sistema en (19). Estas representaciones en particular, son curvas paramétricas (con como parámetro) que trazan la trayectoria de cada particular solución 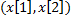 , cuando el tiempo del experimento
, cuando el tiempo del experimento 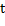 se encuentra dentro del rango
se encuentra dentro del rango 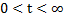 .
.
3.2. Evaluación de rendimiento
En la Figura 1 se ilustra la secuencia oscilante de muestreo de la respuesta natural obtenida con STLQ dada una condición inicial arbitraria 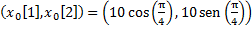 , un intervalo de muestreo mínimo , y un conjunto de parámetros de diseño . Se observa el alcance que tiene sobre la utilización de recursos: valores más pequeños de producen patrones de muestreo más densos (mayor utilización), y viceversa, como se enunció en la Sección 2.2.2. Este mismo efecto de utilización se puede advertir a través de la métrica de intervalo de muestreo promedio
, un intervalo de muestreo mínimo , y un conjunto de parámetros de diseño . Se observa el alcance que tiene sobre la utilización de recursos: valores más pequeños de producen patrones de muestreo más densos (mayor utilización), y viceversa, como se enunció en la Sección 2.2.2. Este mismo efecto de utilización se puede advertir a través de la métrica de intervalo de muestreo promedio 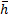 en (18). Además, los retratos de fase ilustran la convergencia de los estados de la planta hacia el punto de equilibrio
en (18). Además, los retratos de fase ilustran la convergencia de los estados de la planta hacia el punto de equilibrio 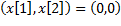 , indicando estabilidad del sistema a pesar de las diferentes densidades del muestreo.
, indicando estabilidad del sistema a pesar de las diferentes densidades del muestreo.
La Figura 2 muestra el patrón de muestreo (que primero oscila y luego se estabiliza) de la respuesta natural obtenida a través de la estrategia OSIST, considerando la misma condición inicial que la usada para evaluar STLQ (Figura 1), un intervalo de muestreo máximo , un parámetro de distribución de muestras , y un conjunto de valores de densidad de la secuencia de muestreo . Es evidente que el valor del parámetro 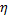 influye en la utilización de recursos, produciendo muestreos más densos cuando su valor es menor, como se mencionó en la Sección 2.2.2. Además, el muestreo promedio es más pequeño para muestreos más densos, corroborando un mayor uso de recursos. En cuanto a los retratos de fase, se puede observar que los estados convergen al punto de equilibrio indistintamente de las secuencias de muestreo, confirmando la estabilidad del sistema. Es importante distinguir que conforme los estados tienden al equilibrio, el muestreo tiende a .
influye en la utilización de recursos, produciendo muestreos más densos cuando su valor es menor, como se mencionó en la Sección 2.2.2. Además, el muestreo promedio es más pequeño para muestreos más densos, corroborando un mayor uso de recursos. En cuanto a los retratos de fase, se puede observar que los estados convergen al punto de equilibrio indistintamente de las secuencias de muestreo, confirmando la estabilidad del sistema. Es importante distinguir que conforme los estados tienden al equilibrio, el muestreo tiende a .

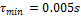
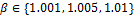
En la Figura 3 se analiza el impacto del estado inicial sobre el desempeño de cada enfoque, considerando al intervalo de muestreo promedio como función de la orientación inicial de los estados (véase la Sección 2.2.1). Cada aproximación estabiliza la planta ante diferentes condiciones iniciales expresadas en términos de magnitud constante y orientación variable (se muestran solo ángulos dentro del intervalo  ya que la segunda mitad del círculo es simétrica con respecto a la primera mitad). Si se observa la Figura 3, se obtiene menor utilización (mayor muestreo promedio) para el intervalo de orientaciones
ya que la segunda mitad del círculo es simétrica con respecto a la primera mitad). Si se observa la Figura 3, se obtiene menor utilización (mayor muestreo promedio) para el intervalo de orientaciones 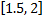 , en las dos reglas de muestreo. Finalmente, tanto en STLQ como en OSIST el intervalo de muestreo promedio depende de la condición inicial.
, en las dos reglas de muestreo. Finalmente, tanto en STLQ como en OSIST el intervalo de muestreo promedio depende de la condición inicial.
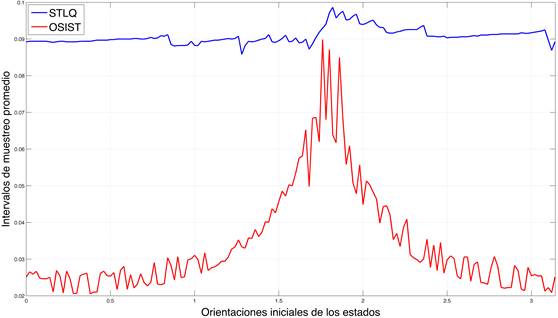
Fig. 3: Efecto de la orientación de estado, en STLQ (azul), con 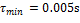 ,
, 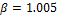 , y en OSIST (rojo), con
, y en OSIST (rojo), con 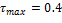 ,
, 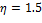 y
y 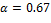 para OSIST
para OSIST
La Figura 4 muestra el impacto que tienen y en el rendimiento de control. Para ello se utiliza como métrica el costo normalizado, definido en la (21) como
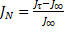 ,
(21)
,
(21)
donde  es el costo LQR mínimo del sistema en tiempo continuo (4), y
es el costo LQR mínimo del sistema en tiempo continuo (4), y 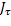 es el costo discreto en (8) pero con intervalos de muestreo variables. En la misma Figura 4, la línea negra corresponde al costo obtenido a través del control LQR periódico en tiempo discreto, para diferentes períodos de muestreo. Como puede observarse, el desempeño del controlador periódico disminuye a medida que el período de muestreo aumenta. La curva en azul corresponde a STLQ y la curva en rojo a OSIST, para diferentes parámetros y respectivamente, con configuraciones y estados iniciales arbitrarios. Si se tiene en cuenta que y indican la densidad de la discretización, se evidencia que para valores pequeños, ambos enfoques proporcionan tanto intervalos de muestreo promedio cortos (mayor utilización), como menores costos. Las dos aproximaciones superan al caso periódico.
es el costo discreto en (8) pero con intervalos de muestreo variables. En la misma Figura 4, la línea negra corresponde al costo obtenido a través del control LQR periódico en tiempo discreto, para diferentes períodos de muestreo. Como puede observarse, el desempeño del controlador periódico disminuye a medida que el período de muestreo aumenta. La curva en azul corresponde a STLQ y la curva en rojo a OSIST, para diferentes parámetros y respectivamente, con configuraciones y estados iniciales arbitrarios. Si se tiene en cuenta que y indican la densidad de la discretización, se evidencia que para valores pequeños, ambos enfoques proporcionan tanto intervalos de muestreo promedio cortos (mayor utilización), como menores costos. Las dos aproximaciones superan al caso periódico.
Un posible espacio para investigar dentro del enfoque STLQ (Gommans, 2014) consistiría en, cumpliendo la misma restricción en el costo, no solo considerar el intervalo de muestreo actual, sino más de un intervalo de muestreo. Además, una nueva alternativa podría explorar si la ocurrencia de intervalos cortos de muestreo adicionales, mejoraría el costo sin poner en riesgo la utilización. Lo anterior se enuncia considerando que ampliar los intervalos de muestreo tanto como sea posible, no es una garantía para lograr un costo mínimo.
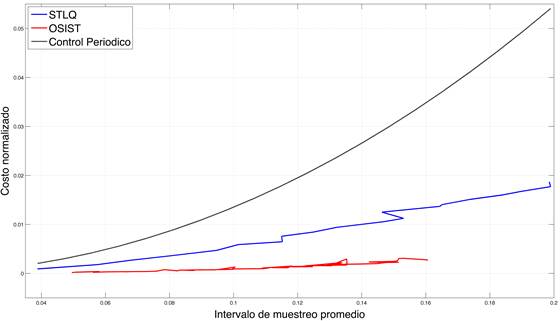
Fig. 4: Efecto del factor de escala 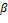 en STLQ (azul) para
en STLQ (azul) para 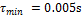 y
y 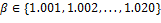 , y efecto del factor de densidad
, y efecto del factor de densidad 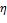 en OSIST (rojo) para
en OSIST (rojo) para 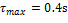 , y
, y 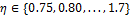
En OSIST (Velasco, 2015), dado que el costo normalizado bordea cero (Figura 4), y que el algoritmo para ajustar los parámetros de diseño todavía está incompleto, investigaciones futuras podrían explorar el efecto que estos parámetros ejercen sobre el costo. La sencillez de la regla de muestreo (12) facilita su implementación, pero introduce un grado de suboptimalidad cuando se utiliza la aproximación de primer orden de la dinámica de lazo cerrado. Por lo tanto, en estudios posteriores, podría considerarse el uso de aproximaciones de orden superior.
Como trabajo futuro sería factible la formulación de una búsqueda de los ajustes de control que minimicen el costo sujeto a una restricción en demanda de recursos (común para los dos enfoques). Se puede considerar al intervalo promedio de muestreo como una restricción adecuada, utilizando condiciones iniciales que proporcionen al menos un intervalo promedio similar entre las dos aproximaciones.
4. Conclusiones y Recomendaciones
Se ha presentado un análisis comparativo de dos enfoques de control auto-disparado que siguen principios de diseño distintos. Este estudio ha demostrado que: ambos tienen un desempeño que supera al del muestreo periódico y queda campo por explorar en la formulación de métricas y condiciones de trabajo aplicables en su evaluación conjunta.

