











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
En bases de datos, la lógica difusa es utilizada para extender las bases de datos relacionales (BDR) a difusas (BDRD) (Barranco, C.D., Campaña, J.R., & Medina, J.M., 2008), estas bases permiten el almacenamiento y procesamiento de datos clásicos y difusos de manera conjunta, para lo cual los datos difusos deben ser sujetos de un proceso previo de traducción o transformación para asumir grados de pertenencia en base a funciones lineales o regresión lineal, y luego ser implementados con herramientas de procesamiento de datos, estas bases de datos brindan flexibilidad a aquellas empresas o instituciones donde se manipula información imprecisa y que no puede ser considerada de manera real para cálculos matemáticos o comparaciones estadísticas debido a la escasa información numérica que proveen.
En la teoría de lógica difusa, propuesta por Zadeh en 1965 se menciona el concepto de conjuntos difusos para explicar el sentido de pertenencia de los elementos que forman parte de este tipo de conjuntos. Un conjunto difuso A es parte o subconjunto de un conjunto difuso B si cumple con la siguiente condición: µA(x) ≤ µB(X) ∀ x ∈ X. (Pérez & León, 2007)
Para la definición de pertenencia, se establecen reglas que serán consideradas como indicadores de referencia de lo que un elemento debe cumplir para pertenecer a un concepto dado, de esta forma, es posible guiarse a través de enunciados en lenguaje natural para conocer el grado de pertenencia de cada elemento de un conjunto difuso, también se debe mencionar que, para operar posteriormente con estos elementos difusos, existen etiquetas las cuales se pueden reconocer por su tipo. (Pérez & León, 2007)
La tutoría académica de la UTE se la realiza a través de entrevistas, en la misma constan preguntas que buscan conocer detalles sobre los niveles de concentración de los estudiantes, el tiempo que consideran para la preparación de sus exámenes, la relación que tienen con los docentes de las asignaturas en conflicto, así como también temas personales de relevancia que pudieran ser causas de un mal desempeño académico (G. Bravo, 2012), obteniéndose atributos y valores imprecisos e inciertos en su mayoría, por lo que no se pueden plasmar de forma veraz y adecuada en una base de datos relacional.
El artículo describe la implementación de la base de datos relacional difusa de la tutoría académica de la Facultad de Ciencias de Ingeniería e Industrias de la UTE utilizando etiquetas tipo I, a través de la herramienta Fuzzy Lookup (Network, 2016) que es parte de los servicios de integración de SQL Server (SQL Server Integration Services - SSIS), permitiendo asignar un valor de pertenencia a aquellos datos difusos en base a su naturaleza que sería considerado como el conjunto universo. Finalmente, se desarrolla una interfaz que permite recolectar datos clásicos y difusos y permite obtener resultados que respondan a demandas difusas específicas.
2. Metodología
Para la implementación de la base de datos relacional difusa se utilizó la arquitectura ANSI/X3/SPARC (American National Standard Institute - Standards Planning And Requirements Committee), que utiliza modelos de datos en los diferentes niveles para lograr independencia (A. Silberschatz, 2002), además en cada nivel se incorporan elementos propios de las bases de datos difusas. A continuación se explica lo realizado en cada nivel.
Nivel externo.- en esta etapa a través de un estudio exploratorio y descriptivo se realizó el análisis de requisitos de información que forma parte de las tutorías académicas y que será almacenada en la base de datos relacional difusa, como resultado de esto se identificó información clásica y difusa.
Nivel conceptual.- en esta etapa se maneja la estructura conceptual de la base de datos, se identifican los elementos lógicos, tales como las entidades, sus atributos y las relaciones entre dichas entidades, además se consideró la relación existente entre datos clásicos y difusos en los tres niveles de modelamiento de datos difusos, es decir, en la lógica del negocio o la empresa, en cuanto a los datos por sí mismos como sujetos de procesamiento y en el lenguaje de consultas, para determinar si son procesados de forma tradicional o si deben pasar previamente por un proceso de traducción, que es el caso de los datos difusos.
Una vez definido la estructura de los datos y clasificarlos en clásicos y difusos, se procedió a establecer el modelo difuso establecido por GEFRED (R.M. Cicília, 2011), el cual incluye las siguientes etapas:
Etapa de Fusificación.- En esta etapa se definió las funciones de relevancia por medio de las cuales se busca establecer los grados de pertenencia a los elementos del conjunto universo.
Reglas Base.- Se establecieron las reglas por las cuales se realizaron las traducciones o transformaciones de los datos difusos para ser procesados con los datos clásicos.
Etapa de Inferencia.- Se evaluó cada uno de los conjuntos difusos y se combinó con la información definida dentro de las reglas base.
Etapa de Difusificación.- Etapa final en la cual se obtuvo los resultados de la traducción y procesamiento de los datos difusos.
Estas etapas implican el uso de métodos matemáticos para establecer los conjuntos difusos y los grados de pertenencia que corresponden a las etiquetas lingüísticas que son elementos de dichos conjuntos, el agrupar de esta manera permite a su vez reconocer aquellas entidades difusas e integrarlas y relacionarlas según sus atributos difusos en el modelo conceptual.
Nivel interno.- una vez definido el modelo conceptual de la base de datos, se utilizó la herramienta CASE Power Designer para generar el script SQL para la implementación en el DBMS SQL Server y para la transformación de las entidades difusas se utilizó la herramienta Fuzzy Lookup del mismo DBMS, esta herramienta requiere de tablas de referencias para realizar este proceso, estas tablas se agregaron en el modelo conceptual sirviendo de catálogo de búsqueda para encontrar coincidencias entre los datos difusos que ingresan al proceso de transformación y los datos de referencia que serán ingresados en base a los grados de pertenencia calculados en el nivel conceptual.
La herramienta Fuzzy Lookup genera como resultado dos tipos de puntuaciones por cada búsqueda: Puntuación de Similitud y Puntuación de Confianza, en este caso se definió el modelo de unificación mediante relaciones de similitud para manejar de forma precisa tanto la información de entrada, es decir las demandas, como los resultados después de haber pasado por el proceso de transformación y comparación de la puntuación de similitud obtenido entre el dato difuso y las tablas de referencias.
Estas etapas implicaron el uso de la técnica de regresión lineal con el método de mínimos cuadrados para establecer los conjuntos difusos y los grados de pertenencia. (D. Anderson, 2008)
El método de mínimos cuadrados es empleado para encontrar la ecuación de regresión estimada a través de datos tomados de una muestra.
Al graficar un conjunto de datos de una muestra, se obtiene un gráfico de dispersión, por lo que se aplica un método de regresión lineal para encontrar la recta que se ajuste a los datos de la muestra.
La ecuación de regresión lineal simple está dada en la siguiente expresión matemática:
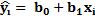
Dónde:
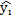 = Valor estimado de grados de pertenencia.
= Valor estimado de grados de pertenencia.
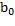 = Intersección de recta de regresión con el eje y.
= Intersección de recta de regresión con el eje y.
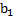 = Pendiente de la recta de regresión.
= Pendiente de la recta de regresión.
 = Definición de atributos difusos.
= Definición de atributos difusos.
La definición de cada uno de los elementos de la expresión antes descrita, está dada en base al caso particular del análisis de datos difusos.
El criterio del método de mínimos cuadrados, se muestra en la siguiente expresión:
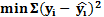
Dónde:
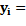 Valor real de la variable dependiente.
Valor real de la variable dependiente.
 Valor estimado de la variable independiente.
Valor estimado de la variable independiente.
Al sustituir la ecuación de regresión lineal simple en la expresión matemática de mínimos cuadrados, se obtiene la siguiente expresión:
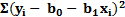
Para el desarrollo de la interfaz se basará en el ciclo de vida del modelo espiral propuesto por (Pressaman, 2010), este modelo describe el desarrollo en un corto plazo, donde el usuario final y sus requisitos se encuentran definidos, para de esta manera tener lo más pronto posible un ejecutable que pueda ser probado por el usuario final. Este modelo está compuesto por las siguientes fases:
Análisis de interfaz
Diseño de interfaz
Desarrollo de interfaz
Validación de interfaz
3. Resultados
Como parte del estudio exploratorio y descriptivo de la tutoría académica se revisó el manual interno de tutorías académicas (SITUTOR) (G. Bravo, 2012), se determinó que el proceso se inicia con la planificación de la entrevista de los estudiantes de una carrera, la información se registra en una hoja de Excel parametrizada, esta se encuentra formada por 21 preguntas referentes a la información personal del estudiante e información general sobre la carrera y las asignaturas en las cuales registra segunda y tercera matrícula. A través de 16 preguntas, se analizan aspectos que afectan el desempeño académico del estudiante, se toma en cuenta hábitos de estudio, ambiente de estudio, actividades adicionales y la relación que existe con los docentes, entendiendo por relación al estado de confianza, respeto y comprensión entre las partes durante el tiempo de clases. El análisis de conocimientos se basa en 4 preguntas fundamentales: conocimientos de informática, desenvolvimiento en internet, manejo de la plataforma o campus virtual de la UTE y conocimiento del idioma Inglés. El estudiante a través del dialogo con el tutor proporciona aspectos como nivel de comunicación, grado de responsabilidad, capacidad de trabajar en equipo y una última pregunta que permite conocer cuáles son las expectativas del estudiante con respecto a las tutorías académicas.
Del análisis realizado se identificó datos clásicos y difusos de las tutorías académicas, información parcial de estos se muestran en la Tabla 1.

El universo de datos de la tutoría académica permite clasificar y englobar los datos difusos en tres conjuntos:
Conjunto Difuso 1: Alto, medio, bajo.
Conjunto Difuso 2: Excelente, buena, mala.
Conjunto Difuso 3: Nada, poco, bastante, mucho.
Estos tres conjuntos de datos difusos, son procesados para obtener el modelo difuso, como ejemplo se muestra una parte del proceso en cada etapa.
Etapa de Fusificación.- la referencia del grado de pertenencia dentro del universo de datos difusos, en primera instancia se lo realizó en lenguaje natural ejemplo:
Niveles de concentración (alto, medio, bajo)
Relación con el docente (excelente, buena, mala)
Análisis de conocimientos - informática, internet, plataforma, idioma inglés (nada, poco, bastante, mucho)
Reglas Base.- Cada conjunto de datos difusos fue tratado por separado para la transformación matemática, debido a que representan una escala diferente de grados de pertenencia, los cuales están dentro de un rango de (0,1). En el caso práctico de las tutorías académicas, los conjuntos de datos difusos se encuentra definidos con un número de 3 a 4 datos por conjunto, para definir con mayor claridad los grados de pertenencia, se procede a colocar atributos difusos intermedios entre los atributos, estos datos intermedios son representados básicamente como puntos de referencia dentro de las gráficas de dispersión y ajuste de recta bajo el criterio de mínimos cuadrados.
Etapa de Inferencia.- Dentro de las reglas base se declaró tres reglas fundamentales, que se aplican a los conjuntos de datos difusos, para tener un mejor entendimiento se utilizan gráficos de dispersión, ubicando en el eje horizontal (x) los atributos difusos, y en el eje vertical (y) los grados de pertenencia, las reglas aplicadas son:
Regla Base 1: Transformación matemática por separado de cada conjunto de atributos difusos.
Regla Base 2: Los grados de pertenencia a definirse deben estar dentro del rango [0,1].
Regla Base 3: Colocar atributos difusos intermedios como puntos de referencia.
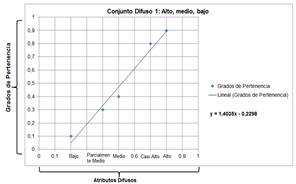
Como ejemplo se muestra la aplicación de estas reglas de inferencia al conjunto difuso 1 (Alto, medio, bajo) en la Figura 1.
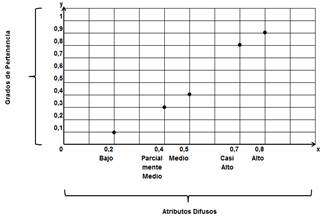
Etapa de Difusificación.- Una vez estimados los grados de pertenencia de cada conjunto de atributos difusos, se inicia el procesamiento de dichos valores a través de la regresión lineal simple con el método de mínimos cuadrados. Como ejemplo los valores obtenidos para el Conjunto Difuso 1 (Alto, medio, bajo) se muestran en la Tabla 2.
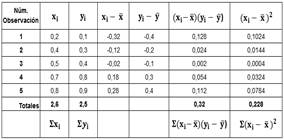
La gráfica de la recta ajustada a los puntos del Conjunto Difuso 1 se muestra en la Figura 2.
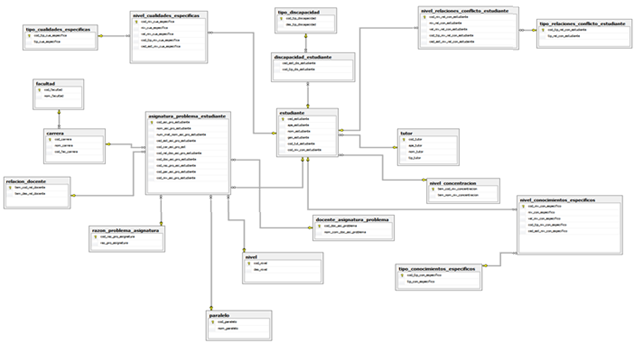
El modelo relacional difuso consta de 19 tablas que contienen atributos clásicos (Crisp) y atributos difusos como se indica en la Tabla 3.

Las tablas que contienen atributos clásicos (Crisp) son tratados dentro de un modelo Entidad - Relación común, mientras que las tablas que contienen atributos difusos, son sujetos de transformación a través de etiquetas lingüísticas almacenadas en lenguaje natural dentro de las respectivas tablas. El esquema final de la base de datos se presenta en la Figura 3, el mismo que consta de 19 tablas con datos clásicos y difusos.
El proceso de transformación se realizó mediante la herramienta Fuzzy Lookup que es parte de los servicios de integración de SQL Server (SQL Server Integration Services - SSIS), este proceso requiere de una tabla de origen que contiene la información difusa recolectada a través de las entrevistas y la tabla de referencia que contiene los atributos difusos con sus grados de pertenencia encontrados en el proceso de transformación matemático.
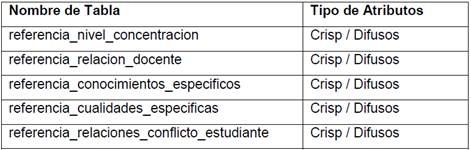
Las tablas de referencia de aquellas tablas que contienen atributos difusos, se muestran en la Tabla 4.
A continuación se muestra un ejemplo SQL para la creación de la tabla nivel de concentración, la misma que va a contener datos clásicos y difusos:
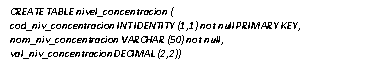
La Figura 4 muestra las tablas que alojan datos clásicos y difusos, la diferencia radica en que aquellas tablas difusas, cuentan con un campo donde se registrará el valor numérico resultante de la transformación difusa de las etiquetas lingüísticas registradas en lenguaje natural, de manera provisional, este campo se registra inicialmente con el valor de cero (0.00).

Posterior a la creación de las tablas se procedió a ingresar la información. Un ejemplo de inserción se muestra para la tabla nivel de concentración.

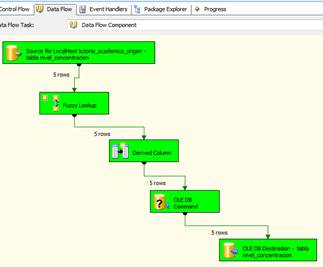
El flujo de transformación difusa para cada tabla que contiene atributos difusos se refleja en la Figura 5, las tablas de origen, pasan por una transformación difusa, derivación de columnas y ejecución de comandos SQL para finalmente desembocar en las tablas de destino que son las mismas tablas, pero internamente modificadas por la transformación.
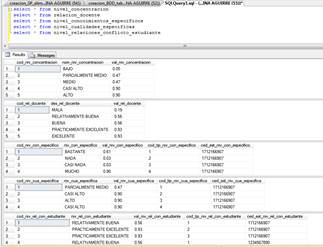
Posterior a la ejecución del flujo de transformación se comprueba que, los registros difusos de la base de datos ya cuentan con los valores numéricos equivalentes a las etiquetas lingüísticas, los registros que han sido transformados pueden ahora ser consultados y visualizados, con la sentencia select respectiva del lenguaje SQL como se muestra en la Figura 6.
En otros sistemas gestores de bases de datos es necesario contar con un servidor FSQL (A. Urrutia, 2008) que permita a través de un lenguaje extendido realizar consultas difusas, un ejemplo de este lenguaje es la siguiente consulta:

Cada vez que sea necesario ejecutar la transformación difusa, se debe ejecutar un proceso de limpieza de atributos difusos, que consiste en “encerar” el campo de valores numéricos equivalentes a las etiquetas lingüísticas de las tablas a ser transformadas, con el objetivo de preservar la integridad de los datos difusos anteriores al integrar nuevos datos a las tablas difusas y transformar de manera global todos los datos que contenga las tablas, este proceso de limpieza consiste en ejecutar un procedimiento almacenado creado en la base de datos el cual se ejecuta directamente desde el SQLServer o desde SSIS mediante un flujo independiente a los flujos de transformación difusa, a continuación se muestra el procedimiento almacenado.

Al aplicar el modelo de espiral para el desarrollo de la aplicación, se inició con el análisis de la interfaz en seis secciones, luego se procedió a diseñar las interfaces de las secciones, el diseño incluye un menú principal para guiar al usuario hacia la interfaz de ingreso de nuevas entrevistas o hacia la interfaz de consultas difusas. La Figura 7 muestra la interfaz principal.
Para verificar el funcionamiento de la aplicación, se realizó pruebas ingresando varias entrevistas de estudiantes de diferentes carreras de la Facultad de Ciencias de la Ingeniería, en la Figura 8 se puede observar una de las consultas difusas ejecutadas antes del proceso de transformación, se puede constatar que los valores numéricos de equivalencias de las etiquetas lingüísticas son cero (0.00).
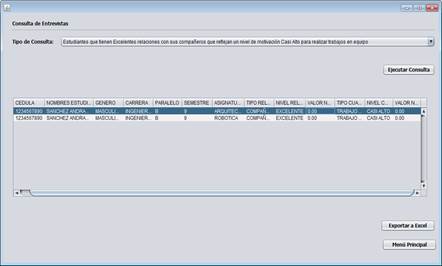
Posterior al proceso de transformación, en la Figura 9 se puede observar que la misma consulta arroja los valores resultantes de la transformación difusa, con lo cual esta información ya puede ser procesada para comparaciones numéricas o estadísticos según lo requieran la comunidad de tutores académicos.

4. Discusión
Este trabajo ha permitido identificar atributos difusos de la base de datos de la tutoría académica, bajo un modelo relacional difuso, que permite extender el esquema tradicional de los sistemas de base de datos (objeto, atributo, valor) a la información imprecisa (en su representación) e incierta (en su consulta) con los conceptos de conjuntos difusos. El nuevo esquema, lo podemos representar como: (objeto, atributo difuso, valor), donde, los atributos difusos del modelo relacional difuso, se encuentran clasificados en: Tipo I (valores precisos), Tipo II (valores imprecisos sobre referencial ordenado), y Tipo III (valores imprecisos sobre referencial no ordenado). Los valores, pueden ser: valores numéricos, escalares simples, etiquetas lingüísticas.
Los elementos de cada conjunto difuso, tienen un grado de pertenencia o grado de posibilidad, en SQL Server la herramienta Fuzzy Lookup permite calcular este grado, además permite traducir o transformar los datos difusos para poder procesarlos como datos clásicos, eliminando la complejidad de otros servidores FSQL que utilizan SQL extendido realizar consultas difusas.
La simulación de la imprecisión y la incertidumbre en una base de datos relacional difusa, es posible hacerlo en un sistema de información cartesiano (0 o 1), lo que implica la creación de múltiples tablas de conversión para simular el hecho que un valor se encuentra en el intervalo [0,1]
5. Conclusiones y Recomendaciones
Es necesario contar con un proceso matemático para analizar información difusa, debido a que, la mayoría de datos difusos son expresados en lenguaje natural a través de etiquetas lingüísticas, es conveniente asumir valores que representen grados de pertenencia en una escala de [0, 1] y en base a estos valores proceder con cualquier método de regresión lineal a encontrar los valores reales que sean bases en la transformación difusa
La definición del modelo de base de datos difusa, debe ser en base al DBMS que vaya a ser utilizado, ya que estos pueden basar sus transformaciones difusas en servidores FSQL o en herramientas CASE donde los resultados obtenidos tienen como fundamento umbrales de similitud, grados de confianza, distribuciones de posibilidades o únicamente grados de pertenencia de cada atributo difuso.
El sistema gestor utilizado permite analizar la información difusa en base a umbrales de similitud y grados de confianza, lo cual pone a disposición dos opciones para garantizar los resultados de las transformaciones difusas.
Al implementar el modelo de bases de datos difusos basados en puntuaciones de similitud y al definir un umbral de similitud del 50%, proveen un nivel de confianza del 0.9875, brindando la seguridad de que los atributos difusos que cumplan con esta condición puedan asumir los valores numéricos según la tendencia que tiene los atributos originales con respecto a los atributos de referencia que son la base de búsqueda en la herramienta Fuzzy Lookup.
SQL Server Integration Services - SSIS, es una herramienta muy útil que facilita el procesamiento de datos clásicos o difusos y permite integrarlos para ser sujetos de consulta o procesamiento dentro del mismo ambiente de SQL, en SSIS es posible condensar dentro de un mismo flujo de procesos, tres actividades, automatizando en su mayoría el proceso de transformación difusa y delegando como proceso manual únicamente la ejecución de dicho flujo.

