











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1. INTRODUCCIÓN
Los sistemas de calentamiento, ventilación y acondicionamiento de aire (HVAC por sus siglas en inglés) han sido objeto de numerosos trabajos de investigación durante los últimos años. Una de las principales razones es que estos sistemas representan hasta un 50%, o más, del consumo total de energía de los edificios donde se encuentran instalados (Afram & Janabi-Sharifi, 2015; Moradi & Vossoughi, 2016; Müller et al., 2014; Shah et al., 2017; Xiong & Wang, 2020; Yan et al., 2020), por lo que su operación eficiente resulta muy importante. También, ha sido de interés el mejoramiento del confort térmico en los edificios y el diagnóstico y detección de fallos en el sistema de climatización. Una herramienta sumamente valiosa para los fines antes expuestos, resulta el desarrollo de modelos matemáticos del sistema bajo estudio.
La investigación realizada en García et al. (2021) muestra que se ha dedicado un número no despreciable de trabajos al desarrollo exclusivo de modelos matemáticos de sistemas HVAC, cuyo interés fundamental es el futuro desarrollo, a partir de los modelos obtenidos de estrategias de control para los sistemas o subsistemas modelados. Por otra parte, en el control propiamente de dichos sistemas se han enfocado también numerosos trabajos, los cuales se interesan fundamentalmente en un buen seguimiento de referencias, respuestas rápidas, sobreimpulsos y tiempos de establecimiento pequeños, lograr el confort térmico y alcanzar los anteriores objetivos con un menor consumo de energía.
La mayor parte de los trabajos citados en la investigación anterior se centran en las dinámicas de las variables: temperatura y humedad, siendo muy pocos los que abordan el flujo de aire o la presión, que suele ser una medida indirecta de este. El estudio de las anteriores variables se realiza en Sun et al. (2011), que desarrolla un modelo en ecuaciones algebraicas para relacionar la velocidad del ventilador con la presión estática del aire. En Abdo-Allah et al. (2018) se desarrolla un modelo multivariable en el espacio de estados que incluye la presión estática del aire entre las variables de salida, haciendo uso de datos del proceso controlado para estimar parámetros. En Razban et al. (2019), también se desarrolla un modelo multivariable, en este caso, en ecuaciones diferenciales donde una de las variables de salida es el flujo másico de aire, en función de la velocidad del ventilador. Los parámetros se estiman a partir de datos históricos del proceso. Por otra parte, en Yan et al. (2020) se utiliza una función de transferencia continua de primer orden con retardo para describir la relación entre la frecuencia suministrada al motor del ventilador y la presión estática generada por su velocidad, en un sistema con volumen de aire variable. El sistema fue identificado a partir de la aplicación de una secuencia binaria de máxima longitud como estímulo y los parámetros del modelo se estimaron mediante el método de mínimos cuadrados.
Una de las funciones fundamentales que cumplen los sistemas HVAC en la industria farmacéutica es mantener presurizadas las áreas que deben permanecer más limpias que aquellas que les rodean. Esto se logra proporcionando más aire dentro de los espacios más limpios que el que es mecánicamente removido de los mismos (Zaki & Mishra, 2015), de ahí la importancia del control del flujo de aire. El interés por desarrollar algoritmos de control que busquen la estabilidad del sistema de suministro de aire se justifica además por la significación del mismo en la calidad del ajuste de todo el sistema y por el consumo de energía (Yan et al., 2020), que aunque de acuerdo con Galitsky et al. (2006) no son los ventiladores los elementos de la UMA que más consumen, estrategias de control como la propuesta en Yan et al. (2020) permitieron un ahorro de energía de un 18.2% en el sistema estudiado.
En el presente trabajo de investigación, se estudió una UMA que climatiza varias salas limpias en un centro biotecnológico, y en ella, el control del flujo de aire de suministro, el cual se hace indirectamente a través del control de la presión diferencial en la sección de impulsión. El centro produce actualmente uno de los candidatos vacunales cubanos contra la Covid-19 y debe ser muy riguroso el mantenimiento de la limpieza de las salas, lo cual no solo se logra con los filtros, sino también cumpliendo con el número de recambios de aire por hora establecidos y suministrando en cada momento el volumen requerido de aire para mantener las diferencias de presión establecidas entre las diversas áreas. La capacidad productiva del centro se encuentra en estos momentos en expansión, con la adición de nuevas plantas de producción, lo que implica la instalación de nuevas UMAs.
Para dar respuesta a las exigencias de calidad del aire en las salas limpias y hacerlo de una manera eficiente desde el punto de vista energético, se propone en este trabajo la obtención de una familia de modelos del subproceso de presión diferencial en la sección de impulsión. Los modelos serán usados para la resintonía del controlador PID actual, puesto que este fue inicialmente sintonizado a prueba y error. También se pretende usarlos para el futuro diseño y evaluación de otras estrategias de control que, por el momento, al no contarse con la licencia del software del PLC, solo pueden ser evaluadas mediante simulación. Por esta razón, el trabajo presta especial atención al procedimiento para validar los modelos obtenidos, pues se busca la fiabilidad de los resultados de las simulaciones basadas en modelos de un proceso con la particularidad de tener una variable de salida cuyos valores medidos presentan una variabilidad de carácter aleatorio muy marcada. De ahí que el aporte de este trabajo sea fundamentalmente metodológico y procedimental, ya que se hace un estudio y selección de un conjunto amplio de técnicas de validación de acuerdo a las características del proceso y los objetivos de los modelos.
A partir de la experimentación y la simulación también se sugieren las opciones de pretratamiento que ofrecen mejores resultados para este proceso, así como modificaciones a los modelos obtenidos que mejoran considerablemente los resultados de estos en las pruebas de validación aplicadas. La utilización de los procedimientos aquí descritos evidencia la posibilidad de obtener, para procesos como el estudiado, modelos fiables y sencillos. Se incentiva, por tanto, la aplicación de estos procedimientos, así como de las técnicas de validación expuestas, como paso previo e imprescindible al diseño de cualquier sistema de control, sea convencional o no, con el aval de los resultados de simulación del sistema controlado que se muestran también en el trabajo.
2. MODELO Y METODOLOGÍA UTILIZADA
Sopesando las ventajas y desventajas de los tipos de modelos que se pueden utilizar en la descripción de unidades manejadoras de aire , mencionadas en Santoro et al. (2019) y Afram & Janabi-Sharifi (2014), dadas las características del proceso bajo estudio, la información disponible sobre el mismo y su rango de operación, se han seleccionado modelos de caja negra lineales, con estructura polinomial, específicamente, estructura Box-Jenkins (BJ), para representar el subproceso de presión diferencial en la sección de impulsión de la UMA. Por lo tanto, se hizo uso de la identificación de sistemas para la obtención del modelo, siguiendo una metodología expuesta en García et al. (2021) que se basa en las metodologías propuestas por Ljung (1999b), Roffel & Betlem (2006) e Isermann & Munchhof (2011). A continuación, se exponen las etapas de la metodología utilizada.
Estudio preliminar del proceso
Las UMAs son el componente fundamental de los sistemas HVAC (Shah et al., 2017). Estas permiten controlar variables como: la temperatura, la humedad y la velocidad del aire, y pueden ser de volumen de aire constante o variable. En el primer caso, la velocidad del ventilador es constante, mientras en el segundo, el flujo de aire es controlado (Ghiaus et al., 2007). Las UMAs se componen de varias secciones y pueden presentar diferentes configuraciones. La estudiada en este trabajo, cuyo esquema se muestra en la Figura 1, climatiza varias salas limpias en el Centro de Ingeniería Genética y Biotecnología (CIGB) de La Habana, y está compuesta por: una sección de mezcla (en la cual el aire que retorna de los locales climatizados se mezcla con una porción de aire exterior), seguida por una sección de filtrado (prefiltro de mediana eficiencia seguido de filtro de alta eficiencia), una sección de enfriamiento (serpentín por donde circula agua enfriada a 7 ℃), una sección de calentamiento (banco de resistencias eléctricas, regulado por un controlador de potencia trifásico con disparo por ráfagas y dos fases, al cual se le suele llamar válvula eléctrica) y una sección de impulsión (con un ventilador radial sin caracol tipo “plug fan”).
El proceso bajo estudio es el caudal de aire en la UMA descrita. Dicha variable se controla indirectamente a través de la medición de presión diferencial en la sección de impulsión, dado que el ducto de suministro no tiene la longitud necesaria para instalar un sensor de caudal de aire. El lazo de control de la variable consta de un controlador que recibe la señal correspondiente a la medición (0 a 10 V) del sensor de presión diferencial y genera la señal de control, la cual es transmitida (0 a 10 V) a un variador que regula la velocidad del motor trifásico de 460 V que mueve al ventilador, en función de la cual está el caudal de aire que suministra la UMA. La referencia de este lazo de control es de 2280 Pa.
El objetivo perseguido con la obtención de un modelo matemático de presión diferencial en la sección de impulsión de la UMA es, en primer lugar, resintonizar el controlador PID que regula dicha variable, garantizando el suministro a las salas limpias del caudal de aire necesario en cada momento. Dicho ajuste se realizó a prueba y error y se desea comprobar si un ajuste basado en un modelo del proceso permite un mejor desempeño del lazo de control. La Figura 2 muestra el comportamiento de dicho lazo
con la sintonía actual, la cual consiste solamente en un tiempo integral de 5 s, que, de acuerdo a la información técnica del controlador, hace que el mismo funcione como un controlador On-Off, al no tener un valor distinto de cero en la ganancia proporcional. Por otra parte, también se persigue el diseño de estrategias de control avanzadas para el proceso, así como el estudio y evaluación de las mismas mediante simulación, tanto desde el punto de vista del desempeño del controlador (estabilidad, rechazo a perturbaciones, entre otros aspectos de interés) como desde el punto de vista de la eficiencia energética.
Como recurso para la realización de experimentos se contó con un sistema de supervisión, control y adquisición de datos (SCADA) que permite intervalos de muestreo fijos (de un minuto o superiores) o muestrear cada vez que se detecte un cambio en la variable. Al seleccionar esta segunda opción se observó que las mediciones de presión diferencial tenían lugar, casi siempre, cada un segundo. También, a través del controlador y del panel de operador, es posible cambiar los lazos de control de modo automático a manual, abrir los lazos de control y forzar los valores de la señal de control.
El valor de la presión diferencial se almacena y muestra en el sistema SCADA en pascal (Pa). La señal de control, aunque se transmite en el rango y unidades antes mencionados, se muestra en un rango de 0 a 100 %, existiendo una relación lineal, en la que 0 % se corresponde a 0 V y 100 % a 10 V. De ahí que se trabajó con el porcentaje de la señal de control, pues, además, se conoce que la salida del bloque PID en el programa del controlador está configurada para que sus valores se encuentren en un rango de 0 a 100.
Selección de las variables de interés y diseño de experimentos
Teniendo en cuenta el objetivo de la identificación y los medios disponibles para realizar experimentos, se seleccionó como variable de entrada el porcentaje de la señal de control y como variable de salida la presión diferencial (variables de interés). Se realizaron tres experimentos, cuyos resultados se muestran en la Figura 2, de los cuales, el primero de ellos se puede considerar como pasivo, de acuerdo a las clasificaciones de los métodos de identificación hechas en Mikleš & Fikar (2007). Este experimento consistió en la recolección de datos del régimen de operación normal del proceso controlado en lazo cerrado. Se tomaron datos en tres ocasiones durante intervalos de tiempo de 186, 267 y 452 s y se promediaron los valores de la presión diferencial en cada uno de ellos, obteniéndose como resultado 2275,2, 2277,5 y 2275,9 Pa para cada intervalo respectivamente. De esta manera, se concluyó que la media de la presión diferencial, dependiendo de la cantidad de muestras tomadas, es un valor cercano a la referencia, aunque ligeramente inferior.
Para la realización de los experimentos activos se abrió el lazo de control y la entrada fue forzada manualmente desde el PLC, para que tomara determinados valores, de acuerdo al diseño de cada experimento. El primero de estos experimentos consistió en la aplicación de varios pasos de tipo escalón en la entrada. Pudieron así analizarse la linealidad, la ganancia del proceso (K) y parámetros de la respuesta temporal como la constante de tiempo (τ), el retardo (L), el tiempo de subida (T r ), y el pico máximo (M p ), lo cual fue importante tanto en el diseño del experimento posterior como en otras etapas de la identificación, especialmente en la validación.
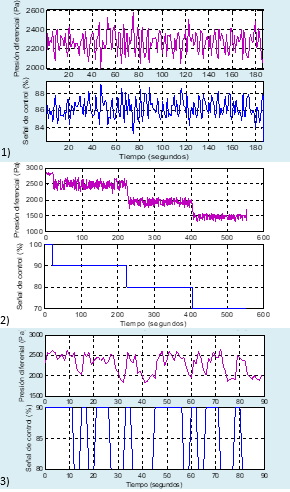
Figura 2 Datos recolectados de los diferentes experimentos. El primer juego (1) corresponde a la operación normal del sistema controlado en lazo cerrado; el segundo juego (2) a los experimentos con pasos de tipo escalón y el tercero (3) a los experimentos con PRBS
Estos experimentos iniciales permitieron observar que la variable presión diferencial nunca alcanza el estado estacionario, sino que oscila permanentemente. Por otra parte, se apreció que, para el rango de valores de entrada mostrado, la salida del sistema no se comporta linealmente. Para un paso del 80 al 70 % de la señal de control se obtuvo K ≈ 45, mientras que, del 90 al 80 %, el resultado fue K ≈ 54,74. No obstante, como la entrada del sistema opera normalmente entre el 83 y el 89 %, puede asumirse que en ese intervalo el sistema se comporta aproximadamente de manera lineal y la ganancia debe ser similar a la calculada para el paso que incluye dicho intervalo.
La constante de tiempo principal del sistema se estimó gráficamente por el método del 5 %, resultando ser τ ≈ 2,27 s. El tiempo de subida, tomado como el tiempo requerido para que la respuesta del sistema pase del 0 al 100 % de su valor final (Ogata, 2010), fue T r ≈ 4s, aunque pudiera ser ligeramente superior (1 o 2 segundos más) ya que las oscilaciones de la variable no permiten apreciar bien los instantes en los cuales comienza y termina el desplazamiento de un punto de operación, forzado durante el experimento con entradas tipo escalón, a otro. El retardo de tiempo (L) se estimó por el mismo método que la constante de tiempo principal, resultando ser L ≈ 0,27 s.
Para el tercer experimento (segundo experimento activo) se escogió como estímulo una secuencia binaria pseudoaleatoria (PRBS), sobre la base de que se busca un modelo lineal y que la señal de estímulo debe ser persistentemente excitante (Isermann & Munchhof, 2011). Para el diseño de la PRBS, como norma general, el tiempo de muestreo (T s ) debe seleccionarse tal que 0,25τ ≤ T s ≤ 0,5τ (Roffel & Betlem, 2006). Dado el valor previamente estimado de τ y las características del sistema anteriormente expuestas, se puede tomar T s = 1 s. Para escoger el tiempo de pulso (T p ) existe el criterio general de que 0,33τ ≤ T p ≤ 3τ y se recomienda que T s se escoja de forma que T p sea un múltiplo exacto de T s (). Para cumplir con ambos criterios se escogió T p = 3T s = 3 s. Esta selección pretendió mejorar la estimación de la ganancia, al costo de disminuir la excitación de las altas frecuencias (). La longitud de la secuencia se calculó como 5τ + L (), que es aproximadamente el tiempo de establecimiento del sistema, que resultó ser 11,62 s. El número de términos de la secuencia se calculó partiendo de dividir la longitud de la secuencia entre el tiempo de muestreo, luego se tomó el menor resultado de la operación 2 n - 1 que fuera mayor o igual que este cálculo, en este caso 23 - 1 < 11,62 < 24 - 1, por lo que la secuencia tuvo 15 bits. Para tener más datos se aplicó dos veces consecutivas la secuencia generada.
Generación de señales, medición, recolección y análisis de datos
Dado que no se dispuso de la licencia del software del controlador, no fue posible programar en este la generación de las señales tipo escalón y de la PRBS diseñada. Por lo tanto, mediante el panel de operador se cambió el lazo de control de la variable presión diferencial de modo automático a manual, con lo que se abrió dicho lazo, y, a través de los botones del módulo de salida del controlador, se aplicaron estos estímulos con el apoyo de un cronómetro, en el caso de la PRBS. Los valores de las variables de entrada y de salida fueron adquiridos mediante la aplicación Trend Viewer del Desigo Insight (sistema SCADA). En la Figura 2, se aprecian los resultados de graficar los datos recolectados durante estos experimentos.
Una vez adquiridos y graficados los datos, lo primero que se comprobó fue que el estímulo en la entrada se hubiese aplicado como se diseñó. Siendo aparentemente así, se comprobó el nivel de excitación en la entrada (para el experimento con PRBS), la cual es persistentemente excitante de orden 30, lo que significa que se deben estimar modelos de orden inferior. Para este análisis, así como para los que a continuación se mencionan, se hizo uso del software MatLab®. Para la detección de valores anómalos (outliers) se inspeccionaron visualmente las gráficas de la Figura 2, lo cual es una forma empírica muy común, aunque subjetiva e inexacta, de detectar outliers basada en la experiencia (Yu et al., 2016), dado que las mediciones que se alejan considerablemente del rango esperado del proceso pueden considerarse potencialmente como datos malos (Roffel & Betlem, 2006).
Para agilizar la etapa de estimación de parámetros, se hizo una estimación previa de los retardos basada en los coeficientes de correlación cruzada. Primero, se calcularon los coeficientes de covarianza cruzada c uy a partir de una serie de datos de entrada u 1 , u 2 , … , u n y una de datos de salida y 1 , y 2 , … , y n según (1), donde i es la cantidad de intervalos de muestreo k que se retarda la entrada respecto a la salida, ū y ȳ son las medias de las series u y y respectivamente y N es el número de observaciones. Con frecuencia es más conveniente trabajar con la correlación cruzada adimensional r uy , dada en (2) (Roffel & Betlem, 2006). La Figura 3 muestra los resultados del cálculo de los coeficientes de correlación de acuerdo a (1) y (2).
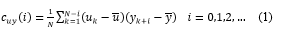
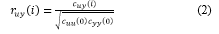
Luego de calcular estos coeficientes, se puede tomar el retardo i con mayor valor absoluto de r uy como la cantidad de períodos de muestreo de retardo que hay entre la entrada y la salida. Por este método se estimó un retardo de un período de muestreo, aunque, como el estimado mediante el experimento con paso escalón es más cercano a 0 s que a 1 s, en la estimación de parámetros, se consideraron ambas posibilidades.
Preprocesamiento de los datos
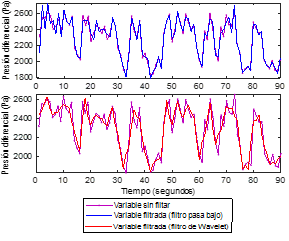
Como variantes de preprocesamiento fueron consideradas: 1) el filtrado de los datos; 2) el escalamiento de los datos; 3) la eliminación de medias, offsets o tendencias y 4) el remuestreo. Debido a que las variaciones observadas en la salida con apariencia de ruido se deben, en lo fundamental, a la turbulencia del flujo de aire, no se hizo uso del filtrado con el fin de remover componentes de frecuencia indeseadas, pues fue de interés preservar este comportamiento del proceso a modelar. El filtrado solo se aplicó a la señal de salida con la función de suavizarla ligeramente, como se muestra en la Figura 4.
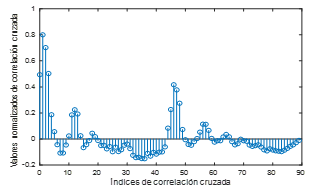
Figura 4 Resultado de aplicar un filtro de Butterworth pasa bajo de orden 2 con una frecuencia de corte de 0.96 Hz y un filtro de Wavewlet de la familia Daubechies, db2, nivel 6, a los datos de salida recolectados del experimento
Dada la notable diferencia en cuanto a la magnitud de los valores de la entrada y la salida, para evitar darle un significado indebido a los grandes valores absolutos de la presión diferencial y sus variaciones, se aplicaron los métodos de escalamiento (normalización) dados por (3) y (4). El primero consiste en restarle a cada variable x su media x y dividir por su desviación estándar σ, mientras que el segundo resta a cada variable su valor mínimo x min y divide el resultado por la diferencia entre sus valores máximo x max y mínimo x min . Como la ganancia de un modelo obtenido con datos normalizados difiere de la de un modelo obtenido con datos sin normalizar, en las simulaciones se aplicaron las operaciones inversas de (3) y (4), según fuese el caso, sobre los datos de entrada y salida de los modelos que se obtuvieron a partir de datos normalizados.


La eliminación de la media a los datos recolectados de ambas variables se consideró como una opción si los modelos estimados con los datos originales no fuesen satisfactorios, sobre la base de que este tipo de preprocesamiento tiene menos impacto en la exactitud de modelos como los ARMAX y BJ (Ljung, 2015). En el caso del remuestreo, debe tenerse en cuenta que los valores generados por interpolación entre las muestras originales no representan información sobre nuevas mediciones del sistema (). Como no fue posible repetir el experimento a una frecuencia de muestreo superior, se valoró esta opción de preprocesamiento como una alternativa si los modelos obtenidos con datos muestreados a la frecuencia actual no eran suficientemente buenos.
Selección del tipo y estructura del modelo a identificar
Siempre que sea posible, se debe desarrollar un modelo lineal con un número pequeño de parámetros. Solo si esto no es así se debe recurrir a otras opciones (Roffel & Betlem, 2006). Teniendo en cuanta esto y el estudio del proceso, previo al experimento con PRBS, la estructura de modelo lineal invariante en el tiempo (LTI) seleccionada fue la familia general de modelos de función de transferencia representados, en tiempo discreto, por (5) (Ljung, 1999b). Estos modelos, conocidos como polinomiales (), expresan la relación entre la entrada u(k), la salida y(k) y el ruido e(k), donde A, B, C, D y F son polinomios dados por (7) (Forssell & Ljung, 2000), k es el instante de tiempo discreto, n k es el retardo de tiempo, en períodos de muestreo, entre la entrada del proceso y la salida y q-1 es el operador de desplazamiento (q-1y(k) = y(k - 1)).
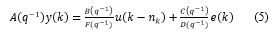
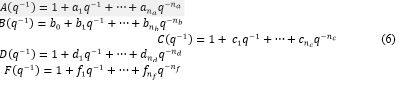
Esta familia de modelos polinomiales incluye estructuras como la ARX, ARMAX, OE, BJ, entre otras, cada una con sus correspondientes polinomios y parámetros. La práctica demostró a los autores de este trabajo que la selección a prueba y error de los órdenes de los polinomios de cada estructura y la posterior validación de cada modelo obtenido, constituía, dadas las características de los datos obtenidos de presión diferencial, un proceso largo, demandante de mucho tiempo y esfuerzo, al repetir los mismos procedimientos muchas veces sin obtener resultados satisfactorios. Como solución a esta problemática, se aplicó la metodología de la identificación de sistemas y el algoritmo de validación propuestos en García et al. (2021).
La aplicación de esta metodología, parcialmente programada en MATLAB®, y algoritmo de validación, totalmente programado, automatiza la selección de los órdenes de los polinomios, la estimación de sus parámetros, y parte de la validación. Por consiguiente, luego de tener listos los datos para identificar, el trabajo humano se reduca a la selección de los órdenes máximos para cada polinomio, la posibilidad de flexibilizar las pruebas de validación programadas (por ejemplo, el porciento de ajuste, conocido como Fit, mínimo, que se puede admitir, o que tan alejada puede estar la ganancia del modelo estimado de la ganancia del modelo de primer orden con retardo estimado en el experimento con entrada tipo escalón) y la realización de otras pruebas de validación que se estimen convenientes, según las características particulares del proceso.
De esta manera, el algoritmo programado estimó todos los modelos resultantes de las posibles combinaciones de los órdenes de todos los polinomios, partiendo del valor cero hasta los valores máximos fijados, con lo cual fueron probadas todas las estructuras de la familia de modelos polinomiales, para luego descartar los modelos que no cumplieron los requisitos establecidos en las pruebas de validación programadas.
Al aplicar los procedimientos antes descritos, se observó que evaluando rígidamente las pruebas de validación propuestas en García et al. (2021), se obtenían muy pocos modelos válidos, que al realizarles las restantes pruebas de validación propuestas en este trabajo, fallaban en algunas o en todas. A raíz de esto, se decidió relajar la evaluación de las pruebas de validación programadas (aceptar Fits un poco más bajos, aceptar algún grado de autocorrelación de los residuos, respuestas al paso más oscilatorias) y se obtuvieron más modelos candidatos a continuar evaluando y a aplicarles los procedimientos descritos en las subsecciones siguientes.
Fue notable que, a pesar de tenerse en cuenta todos los polinomios mostrados en (6) limitados hasta cierto orden, los modelos obtenidos resultaron ser en su mayoría modelos con 𝑛 𝑎 =0 (BJ), además, los modelos con esta estructura fueron los que mejor pasaron las pruebas de validación programadas en la metodología. También se pudo observar que aumentar hasta cierto valor los órdenes de los polinomios que conforman la función de trasferencia que describe la parte estocástica del modelo mejoraba los resultados en la validación, mientras que se podían mantener órdenes relativamente bajos en la función de transferencia que describe la parte determinística del modelo (relación entrada/salida).
Luego, buscando obtener modelos que pasaran lo mejor posible las pruebas de validación sin comprometer la sencillez de estos, y teniendo en cuenta los resultados de la aplicación de la metodología y algoritmo de validación citados, se hizo evidente que convenía modelar el ruido sin que la dinámica del modelo que caracteriza la relación entrada-salida y el modelo de ruido fueran dependientes, como ocurre en los casos de las estructuras ARX (donde 𝑛 𝑐 = 𝑛 𝑑 = 𝑛 𝑓 = 0) y ARMAX (donde 𝑛 𝑑 = 𝑛 𝑓 = 0) (Forssell & Ljung, 2000). De esta forma, utilizar la estructura BJ ofrece la ventaja de obtener modelos de bajo orden en su parte determinística y de un orden mayor en la parte estocástica. Téngase en cuenta además que, para una nueva iteración de la metodología de la identificación utilizada, limitar a cero el valor máximo de 𝑛 𝑎 permitió aumentar los valores máximos de 𝑛 𝑐 y 𝑛 𝑑 , manteniendo el número máximo de parámetros que podía tener un modelo, lo que implicó que, sin aumentar el tiempo que tarda la aplicación de la metodología, pues se estiman y evalúan la misma cantidad de modelos, se alcanzarán mejores resultados con los modelos obtenidos.
Estimación de parámetros del modelo
El procedimiento de estimación de parámetros utilizado selecciona el “mejor” modelo dentro de la estructura de modelo escogida (Ljung, 1999b). En el caso de los modelos polinomiales, se trata de para determinada combinación de grados de los polinomios dados por (6), previamente seleccionada, estimar los coeficientes de los mismos de manera que la diferencia entre la salida del sistema y la del modelo sea la menor posible (Ljung, 2015; Mikleš & Fikar, 2007). Para dicha estimación se hizo uso del método iterativo de predicción del error de identificación (PEM), implementado en la caja de herramientas de identificación de MatLab®.
Se seleccionó la predicción como objetivo de la estimación, lo que determina cómo el error entre las salidas medida y predicha es pesado a frecuencias específicas durante la minimización de la predicción del error. Respecto al método de búsqueda para la estimación iterativa de parámetros, el algoritmo ofrecido por el software selecciona entre el método de los subespacios de Gauss-Newton, una versión adaptativa del mismo, el método de Levenberg-Marquardt y el método del gradiente descendente, de forma tal que la dirección descendente es calculada utilizando los anteriores métodos de manera sucesiva en cada iteración. Las iteraciones continúan hasta que es alcanzada una reducción suficiente del error.
Teniendo en cuenta que el orden del modelo no debe exceder el nivel de excitación en la entrada, (se obtuvo un valor de 30, a partir de la información que ofrece sobre los datos el comando advice de MatLab®), y que se buscan los modelos más sencillos que representen adecuadamente al sistema, se establecieron como límites máximos para los órdenes de los polinomios dados por (6) los siguientes valores: n b = 5, n c = 5, n d = 15, n f = 6 y n k = 1. Luego, se estimaron todos los modelos resultantes de las posibles combinaciones de los anteriores órdenes. Para la estimación se hizo uso del 70% de las muestras recolectadas del experimento con PRBS.
Validación
La validación de un modelo puede definirse como la justificación de que el mismo posee, dentro de su dominio de aplicabilidad, un rango satisfactorio de exactitud, consistente con el uso que se le desea dar. Esta puede considerarse como un proceso dentro del proceso de desarrollo del modelo (Sargent, 2013).
Debido a la forma en que se llevó a cabo la etapa de estimación de parámetros y a que se utilizaron varios juegos de datos, al aplicar varias opciones y combinaciones de pretratamientos sobre los datos arrojados por el experimento con PRBS, se partió de cierta cantidad (decenas) de modelos. Como uno de los fines de un modelo de este proceso es su uso en el diseño de un controlador para el mismo, se buscó una combinación y compromiso entre tener un conjunto pequeño de modelos, tal que la tarea de construir un controlador con un desempeño aceptable en lazo cerrado para todos los modelos sea más fácil de resolver y, a la vez, que el conjunto sea lo suficientemente grande como para incrementar la probabilidad de que el diseño sea exitoso en la vida real (Ljung, 1999a).
El primer criterio considerado para validar fue el cálculo del ajuste (Fit), según (7), el cual expresa el porcentaje de la salida que el modelo reproduce (Ljung, 2015), donde y es la salida medida, ŷ es la salida predicha (simulada) por el modelo, ȳ es la media de y y es aplicada la norma 2 a las diferencias y - ŷ y y - ȳ.
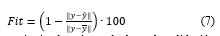
La aplicación de este criterio al conjunto de datos de validación (30 % restante de las muestras recolectadas del experimento con PRBS), programada como parte de la metodología seguida, descartó todos los modelos con Fit inferior al 77 %. A continuación, sobre la base de la ganancia estimada en el experimento con entrada tipo escalón, se aceptaron los modelos con ganancias entre 52 y 57. No se aceptaron modelos inestables ni en límite de la estabilidad y se fue flexible con el grado de autocorrelación de residuos permitido.
A los modelos que fueron seleccionados hasta este punto por el algoritmo de validación se les graficó la respuesta ante un paso escalón (haciendo e(t) = 0 en la simulación). A partir de la observación de las gráficas obtenidas, se seleccionaron modelos con un tiempo de subida entre 4 y 7 segundos. Se fue flexible con el sobreimpulso y el tiempo de establecimiento, dado que las variaciones en los datos recolectados no permiten apreciar estos parámetros con claridad en el sistema real. No obstante, se seleccionaron modelos con tiempos de establecimiento y sobreimpulsos pequeños y, en los casos en que la respuesta presentó oscilaciones, no se escogieron modelos con oscilaciones de gran magnitud.
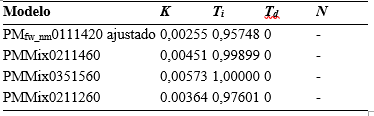
La Tabla 1 resume los modelos seleccionados teniendo en cuenta los anteriores criterios, donde las letras PM indican que es un modelo polinomial, los subíndices n y nm, si como pretratamiento fueron normalizados los datos según (3) o según (4), respectivamente, y los subíndices fblp y fw, si los datos fueron filtrados con filtro de Butterworth pasa bajo o con filtro de Wavelet, respectivamente. Si hay combinación de subíndices, como por ejemplo fw_n, los datos fueron primero filtrados y luego normalizados. La combinación de números después de las letras se corresponde con n a , n b , n c , n d , n f y n k .
Otro criterio que da una medida de la calidad de un modelo es el error de predicción final de Akaike (FPE). De acuerdo a la teoría de Akaike, el modelo más exacto tiene el menor FPE (Ljung, 2015). La Tabla 1 incluye el cálculo del FPE para cada uno de los modelos seleccionados, que, de acuerdo a este criterio y a los demás tomados en cuenta hasta el momento pueden ser considerados como buenos modelos.
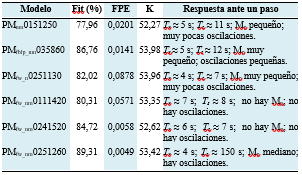
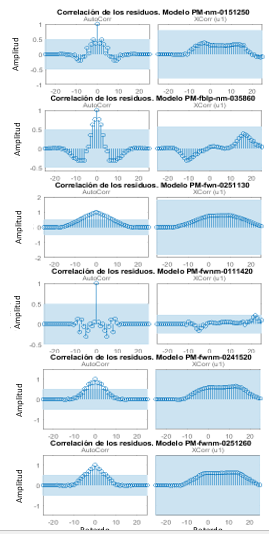
La Figura 5 muestra las gráficas correspondientes al análisis de los residuos de los modelos de la Tabla 1. Los residuos son diferencias entre la salida predicha un paso adelante por el modelo y la salida medida. De esta manera, los residuos representan la porción de los datos de salida no explicada por el modelo (Ljung, 2015). El análisis de los residuos consta de dos pruebas: la de blancura y la de independencia. De acuerdo a la primera, un buen modelo tiene la función de autocorrelación de los residuos dentro de un intervalo de confianza, indicando que los residuos no están correlacionados. De acuerdo a la segunda, un buen modelo tiene residuos no correlacionados con entradas pasadas; evidencia de correlación indica que el modelo no describe como parte de la salida se relaciona con la entrada correspondiente (). Ambas pruebas se aplicaron con el conjunto de datos de validación y los intervalos de confianza seleccionados fueron del 99%.
En la Figura 5, puede apreciarse que las funciones de correlación de los residuos con entradas pasadas se encuentran dentro de los intervalos de confianza sombreados, indicando que son estadísticamente insignificantes con una probabilidad del 99 %. Luego, se puede decir que no hay evidencias de que los residuos de los modelos de la Tabla 1 dependan de valores pasados de la entrada, y, por tanto, de que ante dichos valores la salida no sea adecuadamente descrita por los modelos.
En la prueba de blancura, dado que, por la propia definición de la función de autocorrelación, esta toma valor 1 en el retardo 0, sólo en los modelos PMnm0151250 y PMfwnm0111420 no hay evidencias de autocorrelación de sus residuos y, por tanto, estos en ningún instante de tiempo dependen (también con una probabilidad del 99 %) de los residuos en instantes anteriores. De esta manera, se tendría que estos dos modelos son los que pasan con más éxito las pruebas de validación realizadas.
Hasta aquí, pudiera pensarse que los modelos mencionados en el párrafo anterior son los más adecuados para representar al sistema y ser utilizados en el diseño y evaluación de algoritmos de control. Sin embargo, salvo el algoritmo PID, otras estrategias de control no podrían comprobarse actualmente en el sistema real, lo que hace necesario evaluarlas mediante simulación. Para asegurar la validez de los modelos a utilizar en la simulación, fueron considerados en este trabajo otros análisis, enfocados en la parte estocástica del modelo y en la operación normal del sistema.
A partir del juego de datos recolectado de la operación normal del sistema (controlado en lazo cerrado), se aplicó la señal de control a los modelos de la Tabla 1 y se compararon sus salidas con la salida medida del sistema. En este caso no tiene sentido calcular una medida del error entre las salidas de los modelos y la salida del sistema, debido a que las variaciones en la presión diferencial causadas por las variaciones en la señal de control no son lo suficientemente grandes comparadas con aquellas de carácter aleatorio debidas a la turbulencia del aire. Por tal motivo, incluso dos simulaciones del mismo modelo pueden tener diferentes valores de la presión diferencial en cada instante de tiempo. Luego, se utilizaron criterios propios de variables aleatorias, para las cuales, propiedades y funciones como medias y varianzas, son usualmente de mayor interés y utilizadas en determinar la validez del modelo (Sargent, 2013).
Se eligieron como medidas de cuan bien los modelos describen al sistema en su operación normal a la media y a la desviación estándar. Ambas fueron calculadas para los datos recolectados y, en el caso de la salida de los modelos, se hicieron varias corridas de estos ante la misma señal de control que produjo los datos recolectados, para poder observar la variabilidad estocástica (interna) en los modelos. Una gran cantidad de variabilidad (falta de consistencia) puede causar que los resultados del modelo sean cuestionables (Sargent, 2013).
Esta técnica de validación, útil para modelos estocásticos, se denomina validez interna (Sargent, 2013). La Figura 6 muestra el comportamiento de la media y la desviación estándar de la salida de los modelos para 100 simulaciones en comparación con la media y la desviación estándar de la salida del sistema ante la misma señal de control.
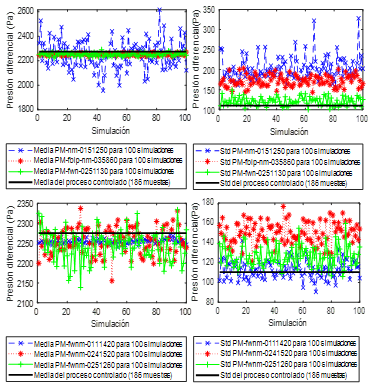
Es evidente que los modelos PMnm0151250, PMfw_nm0241520 y PMfw_nm0251260 tienen medias de la salida muy dispersas y alejadas de la media de la salida del sistema real para las simulaciones efectuadas. Las desviaciones estándar de estos modelos también están dispersas y alejadas de la del sistema real. Los modelos PMfblp_nm035860, PMfw_n0251130 y PMfw_nm0111420 presentan medias bastante concentradas y cercanas a la de la salida del sistema real, aunque un poco inferiores. Mientras, solo las desviaciones estándar de los dos últimos son menos dispersas y más cercanas a la de la salida del sistema. Puede decirse entonces que, al aplicar la técnica de validez interna, salvo los dos últimos modelos citados, el resto son poco consistentes y, por tanto, cuestionables.
Sin embargo, el modelo PMfw_n0251130 tiene sus residuos autocorrelacionados, por lo que, luego de adicionar la prueba de validez interna a las antes realizadas, se puede decir que el modelo PMfw_nm0111420 es el único que ha pasado bien todas las pruebas de validación hechas. A pesar de eso, este modelo, para 100 simulaciones, muestra una media de los valores de salida ligeramente inferior a la media de la salida del sistema real, calculada con 186 muestras, así como desviaciones estándar en las simulaciones un poco dispersas alrededor de la desviación estándar calculada para la salida del sistema.
Para mejorar los resultados en la prueba de validez interna se pueden hacer algunos ajustes a los modelos. Uno de ellos es multiplicar la entrada del modelo por un coeficiente para ajustar su ganancia, pues existe cierta incertidumbre en la ganancia estimada en el experimento con paso escalón, debido a la turbulencia del aire. También se puede añadir un offset a la salida del modelo si las medias en las simulaciones son inferiores a la media de la salida del sistema. Además, disminuir la varianza estimada de la componente ruido e(t), para que la desviación estándar en las simulaciones varíe menos alrededor de la correspondiente a la salida del sistema, también contribuye a disminuir las variaciones en la media.
Los resultados de aplicar los anteriores ajustes sobre el modelo PMfw_nm0111420 se aprecian en la Figura 7. A este se le ajustó la ganancia, multiplicando su entrada por 1,04, con lo que aumentó de 53,35 a 55,48 aproximadamente. Se le añadió un offset de 22 Pa y se redujo la varianza de la componente ruido de 0,011 a 0,0095. Como se observa en la Figura 7, dichos ajustes aumentaron ligeramente el Fit del modelo, sin afectar los buenos resultados en las pruebas de blancura e independencia y, además, le dieron mayor consistencia al lograr que la media de los valores de su salida para sucesivas simulaciones variara poco y alrededor de la media de la salida del sistema real. También los valores de la desviación estándar en las simulaciones varían un poco menos alrededor de la desviación estándar de la salida del sistema con los ajustes hechos.
Otra variante considerada en este trabajo para obtener modelos que superen lo mejor posible las pruebas de validación aplicadas, sin tener que retornar a etapas anteriores de la metodología y repetir el procedimiento desde allí, es construir modelos mixtos con polinomios de dos o más modelos. Para ello se tomaron los polinomios B y F de un modelo, que caracterizan la relación entrada-salida, y se probó sustituir el polinomio C, el D, o ambos, por los mismos polinomios de otros modelos. Dichos polinomios determinan el comportamiento de la perturbación, y, por lo tanto, influyen notablemente en el Fit, los residuos, y el comportamiento de la desviación estándar y la media de la salida.
Esta construcción de nuevos modelos del proceso a partir de los ya existentes se hizo aplicando la técnica de prueba y error. Como resultado, se pudo observar que, teniendo modelos con Fit aceptable, donde unos tienen una consistencia también aceptable, pero residuos correlacionados y otros tienen residuos no correlacionados, pero son inconsistentes, combinar los primeros con los segundos de la forma antes descrita podía resultar en modelos consistentes y con residuos poco correlacionados o sin evidencias de correlación. El Fit podía aumentar o disminuir. La observación de este resultado sirvió de guía para obtener mejores modelos del proceso, sin existir un criterio que asegure que combinando tal parte de un modelo con la de otro se van a obtener los resultados esperados.
La Figura 7 muestra también el desempeño de los modelos mixtos, obtenidos a partir del procedimiento anteriormente explicado, que tuvieron mejores resultados en todas las pruebas de validación realizadas hasta el momento a los demás modelos hasta aquí analizados. Estos modelos mixtos se denominaron PMMix0211460, PMMix0351560 y PMMix0211260 y, luego de obtenerlos, también les hicieron ajustes. El primero se obtuvo a partir de combinar los polinomios B y F del modelo PMfw_nm0251260 con los polinomios C y D del modelo PMfw_nm0111420. Se ajustó la varianza de la componente ruido a 0,0085, se multiplicó la entrada por 1,05, aumentando la ganancia de 53,42 a 56,09 aproximadamente y se agregó un offset de 23 Pa a la salida.
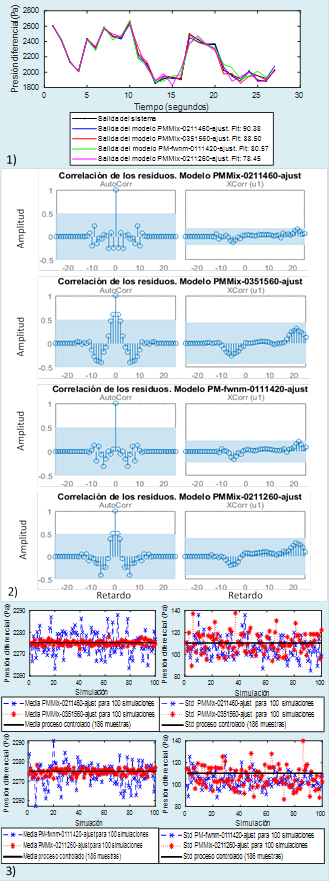
Figura 7 Resultados del modelo ajustado y los modelos mixtos en las pruebas de simulación: 1) comparación de datos y cálculo del Fit, 2) análisis de residuos, 3) validez interna
El segundo se obtuvo al combinar los polinomios B, C y F del modelo PMfblp_nm035860 con el polinomio D del modelo PMfw_nm0241520. Se ajustó la varianza de la componente ruido a 0,0013, se multiplicó la entrada por 1,03, con lo que la ganancia aumentó de 53,98 a 55,6 aproximadamente y se agregó un offset de 23 Pa.
El tercero se obtuvo a partir de combinar los polinomios B y F del modelo PMfw_nm0251260 con el polinomio C del modelo PMfw_nm0111420 y el D del modelo PMmn0151250. Se ajustó la varianza de la componente de ruido a 0,0045 y se añadió un offset de 22 Pa.
Como resultado de la primera combinación, puede apreciarse como a partir del modelo con mejor Fit en la Tabla 1 y el más
consistente en la prueba de validez interna, ambos con residuos no correlacionados, se obtiene un modelo con un Fit, aún superior al del modelo de mayor Fit a partir del cual se obtuvo, una buena consistencia, similar a la del modelo PMfw_nm0111420, y sus residuos se mantiene no correlacionados. O sea, se han combinado en este nuevo modelo las mejores características de los modelos a partir de los cuales se construye.
La segunda combinación también resulta en un modelo con un Fit superior a los de los modelos de los cuales se obtiene. Con los ajustes hechos se mejora la consistencia del modelo PMfblp_nm035860, que, en cuanto al comportamiento de la media ya era muy buena. Por otra parte, los residuos, con evidencias claras de autocorrelación en los modelos originales, mejoran este comportamiento en el nuevo modelo.
La tercera combinación toma polinomios del modelo de mejor Fit y de los dos con peor Fit de la Tabla 1. El resultado es un modelo con un Fit bajo, pero aún mayor al del modelo de menor Fit del cual se obtuvo. Dos de los modelos que lo originan tiene residuos no correlacionados y esto se mantiene, la consistencia en la prueba de validez interna supera a la de cada uno de los modelos que lo originan.
Al disponerse de datos resultantes de un experimento en el cual se estimuló el sistema con señales tipo escalón, datos del sistema operando bajo control en lazo cerrado y datos del sistema en lazo abierto con la entrada forzada a un valor constante durante un período de tiempo, se propone en este trabajo hacer uso de estos tres juegos de datos en dos pruebas más de validación: las conocidas como Face validity y prueba de Turing. La primera, consiste en preguntar a individuos con conocimiento sobre el sistema si el modelo y/o su comportamiento son razonables. La segunda, en preguntar a individuos conocedores del proceso si pueden diferenciar entre la salida de los modelos y la del sistema real ante cada estímulo aplicado (Sargent, 2013). Ambas pruebas se aplicaron a los cuatro modelos analizados en la Figura 7. Los resultados de su aplicación se observan en las Figuras 8 y 9.
Estas pruebas complementan los resultados de la prueba de comparación de datos anteriormente hecha con los datos resultantes del experimento en el cual se estimula al sistema con una PRBS. ¿Por qué no aplicar a estos tres juegos de datos la validación tal cual se hizo con los datos resultantes del experimento con PRBS, en la cual el cálculo del Fit daba una idea de la calidad de los modelos? Porque en este caso, en el cual la entrada permanece constante, o varía poco, ya sea por la frecuencia con que lo hace o por la amplitud de las variaciones, predomina el carácter aleatorio de las variaciones en la salida debido a la turbulencia del aire. Por esta razón, pierde sentido la clásica comparación de datos, que busca que las salidas de los modelos y la del proceso sean lo más parecidas posible, entendiendo por parecidas que el error entre la salida del modelo y la del proceso sea lo menor posible.
Luego, la primera conclusión a la que se puede arribar a partir de las gráficas de las Figuras 8 y 9, es que los modelos se comportan de manera razonable ante los estímulos aplicados. Esto se evidencia, en el caso de la respuesta al paso, en que las salidas de los modelos ante este estímulo varían en el sentido, la magnitud y con la rapidez esperada, al comparar con datos del proceso. Las gráficas de comparación de la respuesta al paso son útiles, al poner de manifiesto las características dinámicas de cada modelo en comparación con las del proceso, como pueden ser picos en la respuesta y el tiempo de subida.
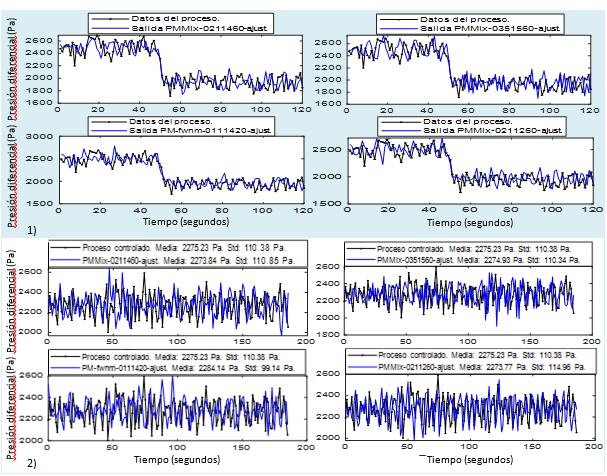
Figura 8 Comparación de las respuestas de los modelos y la del sistema ante: 1) entrada tipo escalón, 2) señal de control
En los casos de las respuestas de los modelos ante los otros dos estímulos (señal de control y entrada constante), aunque puede ser más difícil para quien no esté especializado en proceso sacar conclusiones de cuan razonable es la respuesta a partir de la observación de las gráficas, en las que predomina el carácter aleatorio del comportamiento de la salida, la información que acompaña a estas en la leyenda (media y desviación estándar) da una medida de la similitud del comportamiento de los modelos en comparación con el sistema real, permitiendo corroborar los resultados obtenidos en las pruebas de validez interna. Adicionalmente a esto, al someter dichas gráficas al juicio de especialistas en el proceso, para que distinguieran entre la salida del sistema real y las salidas de los modelos, sin saber cuál era cada una, no pudieron distinguirlas. Con ello se concluyó que fue exitosamente aplicada la prueba de Turing para los cuatro modelos.
En el caso particular de la comparación de la salida de los modelos y la del sistema ante una entrada constante, aunque no se trate de las condiciones normales de operación del sistema, es útil para evaluar cómo los modelos describen el comportamiento aleatorio de la variable, ya que en este caso las variaciones en la salida no se deben a variaciones en la entrada, sino, fundamentalmente, a la turbulencia del aire. Los modelos a utilizar en la simulación deben reproducir bien la relación entrada-salida y también estas variaciones de carácter aleatorio en la salida, pues, como se vio antes, durante la operación normal del sistema controlado, no se distingue entre las variaciones en la presión diferencial debidas a variaciones en la señal de control y aquellas debidas a la turbulencia del aire.
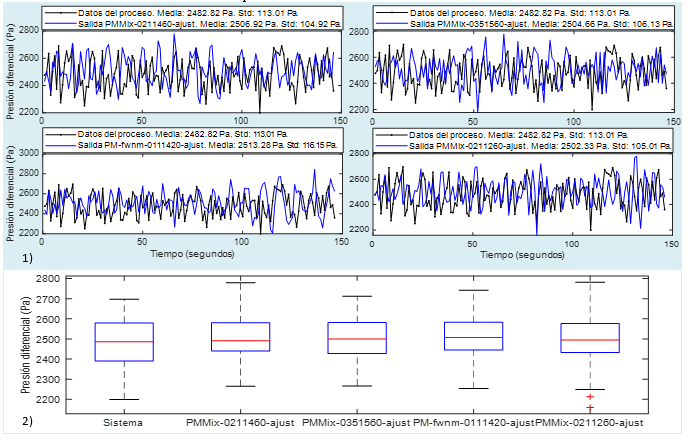
Figura 9 Análisis de la parte estocástica de los modelos: 1) comparación de la salida de cada modelo y la del sistema ante una entrada constante, 2) diagrama de cajas y bigotes de la salida del sistema y de los modelos ante una entrada constante
El diagrama de cajas y bigotes de la Figura 9 en su sección viene a complementar la información que brindan las gráficas en la sección 1. Este diagrama permite visualizar una distribución de datos, aportando una visión general de la simetría de los datos de salida del sistema y de los modelos. Se pueden apreciar en él la dispersión de dichos datos con respecto a la mediana, percentiles 25 y 75 y los valores máximos y mínimos.
De manera general, se puede concluir que, luego de realizar estas dos pruebas de validación sobre la base de la información mostrada en las Figuras 8 y 9, las respuestas de los modelos en comparación con la del sistema fue muy similar. En las comparaciones con la señal de control como entrada, se aprecia una gran similitud entre las medias, salvo la del modelo PMfw_nm0111420 ajustado, que es un poco superior. En las comparaciones con una señal constante como entrada, los modelos la tienen la media un poco superior. Las diferencias en cuanto a la desviación estándar en ambas comparaciones son pequeñas. Respecto al diagrama de cajas y bigotes, las medianas de los modelos, así como los terceros cuartiles, son muy similares a los del sistema. Las diferencias más notables en este diagrama están en los valores máximos y mínimos, el primer cuartil y la simetría, pero, aun así, puede decirse que, para los propósitos de los modelos, estos presentan un comportamiento aceptable en estas pruebas.
3. AJUSTE DEL CONTROLADOR. VALIDACIÓN DE ACUERDO AL PROPÓSITO DEL MODELO
Dado que ninguno de los modelos anteriores es ganador absoluto en todas las pruebas de validación realizadas, teniendo en cuenta el resultado de cada uno en las mismas, pueden considerarse aceptables los resultados del modelo PMfw_nm0111420 ajustado y los modelos mixtos. A los mismos se les aplicó una última prueba de validación: probar (mediante simulación) si estos son aptos para el fin que se persigue con ellos. La prueba realizada consistió en el ajuste de controladores PID a partir de cada modelo y la comparación de la salida del sistema controlado con la estrategia actual (On-Off) y la salida de cada modelo con los ajustes propuestos a los controladores mencionados. También se compararon las señales de control.
Para las simulaciones se utilizó como modelo del controlador el dado en (8), donde T i es el tiempo de acción integral, T d es el tiempo de acción derivativa, T s es el período de muestreo y N es el coeficiente del filtro de la acción derivativa. Esta función de transferencia se corresponde con un PID discreto, obtenido a partir de un PID continuo en su forma estándar con filtro en la acción derivativa, el cual se ha discretizado aproximando las derivadas por diferencias hacia atrás. Esta aproximación da buenos resultados para cualquier valor de T d , lo cual es útil en la práctica, donde puede ser deseable que se desconecte la acción derivativa haciendo T d = 0 (Åström & Hägglund, 2009).
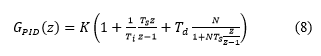
Para la simulación se tuvo en cuenta que el objetivo del lazo de control de presión no es seguir una referencia, sino tratar de mantener el valor de la presión diferencial constante e igual a la referencia (2280 Pa), y que, además, se cuenta con datos del comportamiento de dicho lazo. Luego, la simulación diseñada consistió en, partiendo del valor medio de la presión diferencial y de la señal de control con la estrategia de control actual, calculadas para 186 muestras de la operación normal del sistema, dejar que los controladores ajustados para cada modelo trataran de mantener la referencia, agregando a la salida de los modelos el efecto típico de la turbulencia, en forma de ruido.
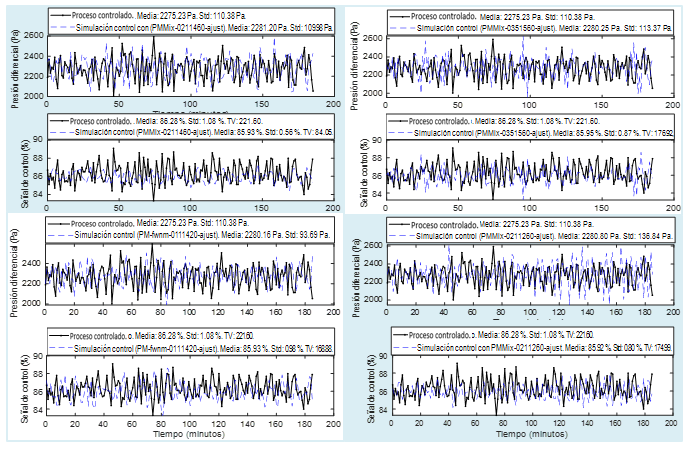
Figura 10 Resultados de simulación de la sintonía de controladores PID sobre la base de los modelos obtenidos
Para evaluar el desempeño de los controladores PID en comparación con la estrategia actual, se compararon la media de la presión diferencial a la salida del sistema y la media de la salida de cada modelo con el valor de la referencia. También se comparó la desviación estándar de los valores que toma dicha variable, para evaluar su dispersión respecto a su valor medio, tanto en la salida del sistema como en las salidas de los modelos. En cuanto a las señales de control, se compararon también medias y desviaciones estándar, así como la variación total (TV), definida en (9) (González et al, 2017), con lo que se persigue evaluar y comparar el esfuerzo de control.
Los resultados de las simulaciones que muestran el desempeño del sistema controlado a partir de los modelos en comparación con los datos reales del sistema de control actual se muestran en la Figura 10. Para las sintonías propuestas, que se muestran en la Tabla 2, se hizo uso de las opciones de sintonía que ofrece Simulink® a través de la interfaz de sintonía de PID.
Puede apreciarse en las gráficas de la Figura 10 que, como resultado del control PID, cuya sintonía se basó en los modelos, a nivel de simulación se logra que la media de la presión diferencial esté más cercana a la referencia que la media de la salida del sistema real controlado. En el caso de la desviación estándar, dos de los modelos muestran valores de salida menos dispersos que los del sistema real. En otro, la dispersión es ligeramente superior y en otro es evidente la mayor dispersión de los valores de la variable controlada.
Con respecto a la señal de control, la media con todos los modelos fue inferior a la media de la señal de control real, aun cuando se logró que la media de la variable controlada en las simulaciones estuviera más cercana a la referencia. Este comportamiento de la señal de control implica un menor suministro de energía al ventilador. En todos los casos la desviación estándar de la señal de control en la simulación del control PID fue inferior a la desviación estándar de la señal de control real. De la misma forma ocurre con los valores de TV, lo que indica un menor esfuerzo de control.
Teniendo en cuenta los resultados mostrados, vale la pena probar las sintonías propuestas, que, además, son bastantes parecidas entre sí, en la práctica. De funcionar de una manera similar a la exhibida por las simulaciones, no solo permitirían un menor consumo de energía, sino que reforzarían la validez de los modelos para el diseño y prueba de estrategias de control más avanzadas que permitan un ahorro de energía mayor aún.
4. CONCLUSIONES
La realización de este trabajo puso de manifiesto algunos de los desafíos que puede involucrar la identificación de la presión diferencial en una UMA: 1) no siempre es posible realizar los experimentos tal cual se diseñan o utilizar el diseño más apropiado, evidente en la imposibilidad de aplicar una señal de estímulo idéntica a la diseñada, así como en las limitaciones para seleccionar el tiempo de muestreo más adecuado; 2) la turbulencia del aire, conjuntamente con la no linealidad del proceso, constituyen un reto a la hora de seleccionar la magnitud de las variaciones en la señal de entrada, pues cuanto más grande es, mejor permite apreciar el impacto de la entrada sobre la salida, pero a la vez, se aleja más del rango en el cual la operación del sistema se puede considerar lineal, lo que obliga a buscar un compromiso amplitud del estímulo Vs rango de operación lineal, que puede conducir a 3) pueden ser necesarios varios modelos para representar al sistema, ya que la turbulencia del aire le da un gran peso a la parte estocástica del modelo en las pruebas de validación, quedando una incertidumbre en cuanto a cuales de los modelos representan mejor la relación entrada-salida, en la cual se basará el posterior diseño de algoritmos de control, como, por ejemplo, el PID.
Se evidenció la necesidad de hacer la mayor cantidad de pruebas de validación posibles. Para el proceso estudiado, se mostró la importancia de la prueba de validez interna a la hora de seleccionar modelos aptos para la simulación. También el preprocesamiento realizado a los datos y los ajustes hechos a los mejores modelos obtenidos, en especial, la combinación de modelos, tal cual se expuso, fueron factores claves para arribar a modelos con resultados satisfactorios en todas las pruebas hechas. No obstante, debe decirse que solo cuando los valores de los parámetros de los PID ajustados sobre la base de cada uno de los modelos sean probados en la práctica, y los resultados sean similares a los obtenidos con ese modelo en la simulación del lazo de control, podrá afirmase que el modelo ha cumplido su propósito y es realmente apto para su uso en el diseño de estrategias de control para esta variable.

