











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkLa climatología es el estudio del clima que busca analizar el comportamiento e interrelación entre las variables que dan lugar a las perturbaciones climáticas, considerando la variabilidad de las observaciones de acuerdo a la ubicación y escala temporal de los datos (Mills, 2006; Le Gal La Salle et al., 2021). Para lo cual se requiere realizar mediciones a diferentes escalas temporales utilizando estaciones meteorológicas automáticas o manuales que permitan recolectar esta información, en algunas ocasiones estas no funcionan correctamente. Para esto se requiere rellenar datos faltantes (Hernández-García et al., 2012), dentro de estas variables la precipitación juega un papel importante para los sistemas hídricos y los relacionados (Asurza et al., 2018). De esta manera se logra una gestión adecuada del recurso hídrico. Sin embargo, los datos de pluviómetros que existen generalmente son escasos y están mal distribuidos, especialmente en los países en desarrollo (Chen & Li, 2016) a todo esto se suma la falta de datos por fallas humanas o tecnológicas, lo que causa una limitada comprensión de los procesos físicos que definen el clima (Condom et al., 2020). Esto hace que se tengan que desestimar series temporales que podrían ser de gran utilidad para estudios posteriores, para solventar este problema se trabaja con diferentes técnicas de imputación de datos (Ng et al., 2009; Kim et al., 2015; Mwale et al., 2012) en las que la mayoría utiliza herramientas computacionales que desarrollan técnicas estadísticas.
Para este estudio se utiliza el software Climatol, que es un programa que se aplica para realizar el control de calidad, homogeneización y completado de datos faltantes de series climatológicas, ya que en varias ocasiones eventos poco frecuentes alteran los datos recolectados y las metodologías de homogenización y completado permiten eliminar o reducir al máximo estas alteraciones no deseadas, al comparar todas las series disponibles en pares, de modo que la detección repetida de una falta de homogeneidad permite identificar cuál es la serie errónea (Guijarro, 2018).
Los eventos climáticos afectan la producción y abastecimiento de recursos por lo que cada país está en la obligación de monitorear el clima y sus variaciones, esto se consigue mediante el uso de estaciones meteorológicas que permite recopilar información que se utiliza para el estudio del clima, su comportamiento y predicción a corto, mediano y largo plazo (Toro et al., 2017). En Ecuador, el INAMHI (Instituto Nacional de Meteorología e Hidrología) es la organización que tiene a su cargo el monitoreo y recolección de información de las estaciones meteorológicas, que, a pesar de su importancia, varias de estas estaciones se encuentran en abandono o no están completamente operativas lo que genera datos erróneos e incompletos. Estos datos deberán ser verificados y rellenados para fines académicos con el mínimo error posible (Carrera et al., 2016). Las series que se busca completar son las de temperatura, precipitación a diferentes escalas, pudiendo ser diaria o mensual, etc., esto dependerá del tipo de análisis, los resultados y objetivos que se persigan durante la investigación (Pezoa, 2003).
Para ello, existen varios métodos que permiten el rellenado de datos meteorológicos entre ellos se puede mencionar el método de regresión-correlación, que depende del supuesto de linealidad entre los datos de las estaciones que se encuentren dentro de un área de influencia cercana y establece el nivel de relación mediante un análisis de dispersión utilizando un coeficiente de correlación, posterior a esto se obtiene una ecuación que se usa para calcular el valor faltante en función de los datos de las estaciones de referencia (Herrera et al., 2017).
Otro método es el denominado promedio aritmético simple (SAA), se utiliza cuando el valor anual en cada uno de los datos a promediar difiere por lo menos de 10% y llega a presentar estimaciones confiables si el dato analizado no tiene variabilidad espacial y si existe correlación entre las estaciones utilizadas para el análisis.
El método de ponderación de distancia inversa IDW se utiliza cuando se dispone de registros en la misma escala temporal de tres estaciones cercanas a la estación en estudio. El IDW se utiliza en cualquier delta de tiempo y para su utilización se requiere una cantidad suficiente de datos para producir un semivariograma fiable (Toro et al., 2017).
Todos los modelos aplican estadística para el relleno de datos, actualmente existen herramientas como Climatol que facilita el relleno y control de calidad para series climatológicas, siendo parte del software estadístico R, está basada en la interpolación espacial de los datos de precipitación que permite el relleno de datos faltantes (Guijarro, 2004).
Para la presente investigación se requiere contar con una base de datos homogénea y de calidad, que sustente los resultados y que pueda ser utilizado como base para futuras investigaciones, por lo cual, se aplica una herramienta que está en capacidad de brindar los resultados esperados, Climatol realiza la imputación o completado de datos en estaciones meteorológicas a partir de datos temporalmente representativos dentro de un periodo de tiempo determinado con respecto a la cuenca de Río Jubones. La rutina Climatol de R Studio ha dado resultados en estudios de imputación de datos y de análisis de tendencia de precipitaciones, resultando ser una herramienta validada en estudios previos (Nery & Carfan, 2014; Caloiero et al., 2016).
2. METODOLOGÍA
Para el presente análisis se utiliza la cuenca del río Jubones, de la cual se seleccionaron a las estaciones meteorológicas que se muestran en la Figura 1:
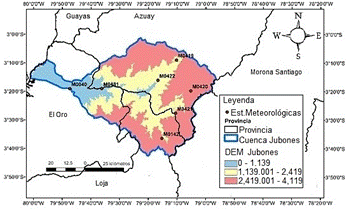
Se verificó que en los registros de datos de las estaciones existían datos faltantes en un porcentaje que no excedió un 18% aproximadamente, y en virtud de ello se justificó el realizar un proceso de verificación del control de calidad de los registros mediante un proceso inicial de análisis exploratorio de datos y luego la aplicación un proceso adecuado de imputación para los datos ausentes de las series a escala diaria.
Para realizar este proceso, se optó por la utilización de Climatol en su versión 3.1.1, el cual es una paquetería del software RStudio, el cual ha sido utilizado en diferentes estudios, obteniendo buenos resultados (De Luque Söllheim, 2011; Guijarro, 2016; Hernández-García et al., 2012).
2.1 Principio de funcionamiento de Climatol
La metodología descrita a continuación necesita que por lo menos exista un valor de cualquiera de las estaciones de las series de datos, por lo que, primero se revisó las bases de datos disponibles y se verificó que cumpla con esta condición. En la Figura 2 se puede comprobar que al menos si existe un dato a lo largo de la serie temporal.
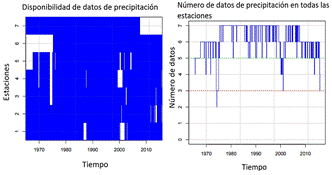
Luego de comprobar que al menos existe un registro en algunas de las estaciones meteorológicas, se procede a realizar la normalización de los datos, Climatol permite ejecutar este proceso con la serie de datos analizados dentro de su propio algoritmo dependiendo de las características de las series (Guijarro, 2018).
Luego de realizar estos procesos, Climatol básicamente construye una serie artificial en la ubicación de cada estación, para lo cual, toma los datos de las estaciones de influencia en relación con la distancia (Guijarro, 2018). Luego, evalúa con la estación de referencia obteniendo una serie de atípicos que son las diferencias entre la serie original y la serie artificial reconstruida (De Luque Söllheim, 2011), esta es la base para obtener los datos que luego serán rellenados.
Para calcular el coeficiente de disimilitud climática, se aplica la metodología propuesta por De Luque Söllheim (2011), este índice es de gran importancia porque permite diferenciar agrupaciones de estaciones climáticas según la tendencia de las variables de precipitación.
3. RESULTADOS Y DISCUSIÓN
Una vez aplicado el proceso mediante la herramienta Climatol, se procede a comparar la calidad de los datos rellenados en las series. Esto se logra al eliminar datos observados aleatorios de una estación de precipitación, y someter estos datos a un nuevo proceso de homogeneización, control de calidad y relleno de datos ausentes de series a escala diaria. Una vez completado el proceso, se realizó una comparación entre los datos observados y los estimados con Climatol. Para la verificación de la variable de precipitación, se eligió a la estación de código M0142, la comparación entre datos observados y rellenados se puede observar en la Figura 3.
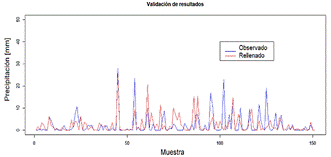
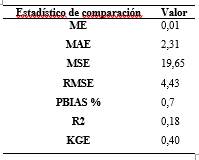
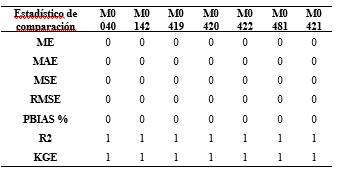
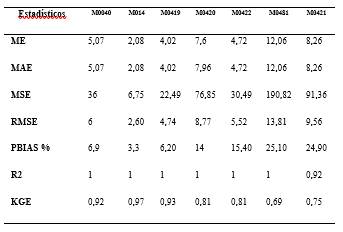
Para analizar la comparación objetiva de estos datos observados y rellenados, se eligieron a las estadísticas de comparación de: error medio (ME), error absoluto medio (MAE), error cuadrático medio (RMS), porcentaje de sesgo (PBIAS %), coeficiente de determinación (R2) y el índice de eficiencia de Kling-Gupta (KGE). Al evaluar todos estos datos estadísticos presentes en la Tabla 1, podemos concluir que el proceso de homogeneización, control de calidad y relleno de datos ausentes de series a escala diaria para precipitación en las estaciones dentro de la cuenca del Jubones proporcionado por Climatol tiene una eficiencia poco satisfactoria, al menos al emplear índices de bondad de ajuste como indicadores de eficiencia.
Tabla 1 Estadísticos de comparación entre datos observados y simulados de precipitación. Escala diaria para el período 1965 - 2015
Sin embargo, se realiza un análisis gráfico de manera rápida del comportamiento de los datos rellenados frente a los datos observados a escala diaria, esto debido a que la verificación se la realizó tomando muestras aleatorias, sin embargo, este breve análisis se lo realiza tomando las series completas, resultado de este análisis a escala diaria se obtienen los resultados mostrados en la Figura 4:
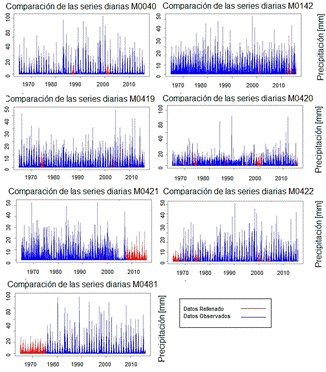
Figura 4: Galería de comparación de series diarias de datos observados y rellenados en las diferentes estaciones
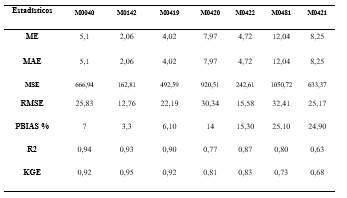
Empleando las mismas métricas de comparación o métricas de ajuste de bondad que las utilizadas en el proceso de validación de Climatol, se obtienen los resultados listados en la Tabla 2, y podemos concluir que hay similitud entre las series diarias comparadas.
Tabla 2 Estadísticos de comparación en la serie completa diaria en las estaciones meteorológicas de precipitación. Período 1965 - 2015
Así mismo, se realiza una comparación entre series observadas y rellenadas a escala mensual, obteniendo los resultados mostrados en la Figura 5.
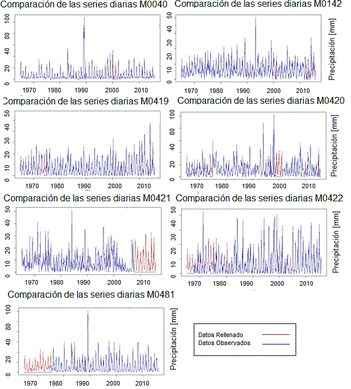
Figura 5 Galería de comparación de series mensuales de datos observados y rellenados en las diferentes estaciones
Se obtiene los resultados listados en la Tabla 3, donde se muestran los estadísticos que evidencian las similitudes entre las series mensuales, considerando el hecho de que se han rellenado datos faltantes de hasta el 18%.
Tabla 3 Estadísticos de comparación en la serie completa mensual en las estaciones meteorológicas de precipitación
Finalmente, se realiza una comparación entre series observadas y rellenadas a escala mensual en su media multianual, obteniendo los resultados mostrados en la Figura 6. En esta figura, se observa el comportamiento de las precipitaciones medias mensuales acumuladas para los años de análisis que van desde 1965 al 2015. De este comportamiento se pueden resaltar dos aspectos importantes, el primero es que el resultado de las series temporales de precipitación completadas por los métodos computacionales analizados presenta una tendencia monótona a los datos observados, como lo evidencian los índices de la Tabla 2. El segundo aspecto importante tiene que ver con el comportamiento propio de las precipitaciones en los meses de marzo y abril en donde se registran los niveles más altos de lluvia, y por otra parte, en los meses de julio y agosto se observan los niveles más bajos.
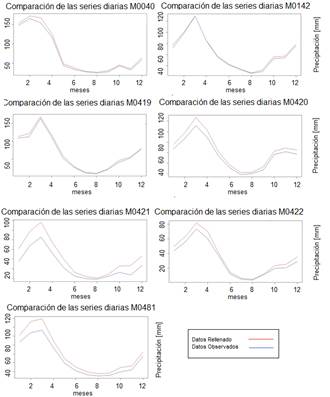
Figura 6 Galería de comparación de series mensuales interanuales de datos observados y rellenados en las diferentes estaciones
Para este análisis los resultados de las métricas estadísticas se presentan en la Tabla 4, con ajustes satisfactorios.
Tabla 4 Estadísticos de comparación en la serie completa mensual en las estaciones meteorológicas de precipitación
Los datos faltantes pueden representar grandes anomalías en los modelos que se planteen en el futuro como lo demostró el estudio realizado por Afghari et al. (2019) para la aplicación en modelos regresivos y Shahbazi et al. (2018) para el monitoreo de datos de contaminación de aire.
Las técnicas usadas para la investigación propuesta han dado resultados satisfactorios para los datos de precipitación en una cuenca de la vertiente del pacífico en Ecuador. Las técnicas usadas en este estudio se pueden comparar con métodos simples computacionalmente como los presentados por Yaseen et al. (2019) en donde aplica una técnica novedosa computacional para la imputación de datos de caudales.
Dentro de la análisis de datos de precipitaciones el estudio presentado por Mwale et al. (2012) presenta la importancia que tienen estos métodos y genera mapas con indicaciones de los lugares en donde es necesario imputar datos. Para Ecuador se puede mencionar la investigación de Campozano et al. (2014) que probaron técnicas para una cuenca andina en el sur del Ecuador y el estudio de Heras & Matovelle (2021) en el que se utilizan técnicas de máquinas de aprendizaje por computadora para la imputación de datos en cuencas vertientes del Pacífico del Ecuador.
El impacto que generan diferentes técnicas para la imputación de datos faltantes queda demostrado en estudios como los de Chen et al. (2019) en donde se evaluaron varios métodos estadísticos para completar series temporales con datos escasos, luego, se aplicaron los métodos mencionados en estudios de recursos hídricos, dando resultados confiables en la aplicación de los modelos hidrológicos.
El uso de algoritmos y metodologías combinadas para validar la imputación de datos hidrometeorológicos tiene un espectro grande de caminos a seguir hasta encontrar el proceso que mejores resultados entregue, desde el tipo de data que se tenga hasta las características propias del área de estudio. De acuerdo con Venema et al. (2012), debido a la importancia de los datos para estudios climáticos es fundamental manejar series temporales que sean correctas y representativas para garantizar los insumos mínimos necesarios para fundamentar la investigación referente al recurso hídrico.
4. CONCLUSIONES
Disponer de metodologías y técnicas computacionales, como las usadas en Climatol para la imputación de datos faltantes en series temporales cuya efectividad se ha puesto a prueba en las áreas específicas como las de gestión del recurso hídrico, hidráulicos, agrícolas, obra civil, entre otros; permite mejorar la estimación de resultados de predicción en el modelamiento de diferentes escenarios. Estas simulaciones tienen menor incertidumbre por lo que se convierten en una herramienta que permite tomar decisiones adecuadas en diferentes aplicaciones.
Los estadísticos de comparación utilizados como ME, MAE, MSE, RMSE, PBIAS, R2, KGE, para la comparación de series temporales diarias entre los datos observados y los datos rellenados resultaron satisfactorios, garantizando que el proceso brinda una imputación de datos de precipitación adecuada.
Se pudo concluir que los datos rellenados en el proceso de imputación fueron aptos para realizar inferencias estadísticas en los análisis de precipitación, gracias al respaldo de los resultados obtenidos en los indicadores comparativos que fueron satisfactorios como se aprecia en la Tabla 4, entre los datos rellenados y los datos observados.
En general, al disponer de conjuntos de datos completos se pueden realizar análisis de precipitaciones y posterior evaluación de recursos hídricos con mayor certeza de que los resultados finales indicarán procesos reales. De esta manera, la planificación y gestión del recurso parte desde un conjunto de datos válidos y confiables. Los procesos de verificación garantizan el manejo correcto de los datos.

