











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
1. INTRODUCCIÓN
En la actualidad los sistemas industriales se encuentran en constante proceso evolutivo, y ya es cotidiano el uso de términos como industria inteligente y cuarta revolución industrial o industria 4.0 (Ustundag & Cevikcan , 2017). Estos términos hacen referencia a la interconexión de todos los componentes de una industria para conseguir un funcionamiento automatizado efectivo que logre elevados rendimientos económicos con un aumento continuo de la calidad de los productos finales, tener elevados niveles de seguridad industrial y reducir al mínimo las posibles afectaciones al medio ambiente (Zabinski et al. , 2019). Para lograr la anterior se necesita la detección y localización temprana de los fallos que comúnmente aparecen en los sistemas industriales en sensores, actuadores y/o en los procesos ya que los mismos se traducen directamente en problemas de seguridad para los operadores, posibles afectaciones al medio ambiente y pérdidas económicas. Estas razones han motivado el desarrollo de un gran número de investigaciones en el campo del diagnóstico de fallos en procesos industriales en las últimas décadas. (Chen & Li , 2018; Rodríguez et. al. , 2019; Ahmed et al. , 2021).
Los sistemas mecánicos son parte fundamental de cualquier industria y sobre todo de la industria moderna de manufactura y es precisamente en estos sistemas mecánicos, donde se presenta una gran parte de los fallos que ocurren en los sistemas industriales (Rodríguez et. al. , 2019; Aydin et al. , 2014).
En general, las metodologías propuestas en la literatura científica para el diagnóstico de fallos pueden agruparse en dos grandes grupos: los métodos basados en modelos (Camps-Echevarría et al. , 2010; Rivera et al. , 2018) y los métodos basados en datos históricos (Rodríguez Ramos et. al. , 2019; Llanes-Santiago et. al. , 2018). En el primer grupo, es necesario el uso de modelos que representen los diferentes modos de operación de los procesos. Las herramientas establecidas en este enfoque se basan en la generación de residuos que se generan de la diferencia entre las mediciones que se obtienen directamente del proceso real y los valores obtenidos del modelo de dicho proceso. La gran dificultad en la aplicación de las metodologías basadas en modelos es que se necesita un elevado conocimiento de las características del proceso, sus parámetros y zonas de operación y en la actualidad eso es difícil lograrlo por la elevada complejidad de las plantas industriales modernas. Por otra parte, los métodos basados en datos no necesitan de un modelo matemático preciso y no requieren de un elevado conocimiento inicial de los parámetros del proceso (Prieto-Moreno et al. , 2015; Cerrada et al. , 2018). En ese sentido, existen múltiples propuestas que utilizan herramientas computacionales y matemáticas como: lógica difusa (Rodríguez Ramos et. al. , 2019), agrupamiento (Cerrada et al. , 2016; Rodríguez et. al. , 2019), herramientas estadísticas (Rezamand et. al. , 2020; Prieto-Moreno et al. , 2015) y redes neuronales (Saufi et. al. , 2020) por solo mencionar algunas.
Entre los principales factores que afectan seriamente a las metodologías de diagnóstico de fallos basados en datos históricos se encuentran los datos fuera de rango, los ruidos en las mediciones y la pérdida de información todo lo cual es muy común en los ambientes industriales. De lo anterior surge la necesidad de atender esta problemática para que el diagnóstico de fallos sea robusto, evitándose falsas alarmas y la pérdida de confiabilidad del sistema (Askarian et al. , 2016).
Las observaciones con valores incompletos pueden deberse a diversas fuentes como fallos en los sensores, problemas de funcionamiento ocasionales de los sistemas de adquisición de datos, posibles errores en las redes de trasmisión de datos y en los protocolos de comunicación por solo mencionar los más comunes. Varios métodos para el tratamiento de los datos perdidos se han propuesto en la literatura científica (Askarian et al. , 2016; Laencina et al. , 2010; Sovilj et al. , 2016). Los principales son (Laencina et al. , 2010):
Ignorar y eliminar los datos incompletos: se usan solo los datos que estén completos.
Imputar o estimar los datos perdidos mediante herramientas estadísticas o de inteligencia computacional.
Modelo basado en la distribución de los datos.
Máquinas de Aprendizaje: procedimientos donde los valores perdidos se incorporan al clasificador.
Cuando se realiza una revisión de las técnicas más utilizadas para tratar los datos perdidos se llega a la conclusión que son los dos primeros métodos mencionados anteriormente los más usados. Sin embargo la información perdida puede ser importante para descubrir posibles relaciones entre las variables y condiciones anormales de operación (Askarian et al. , 2016). Es por esta razón que lo más recomendado para el tratamiento de los datos perdidos en el caso del diagnóstico de fallos es el de imputar. Con este proceso se estiman los valores perdidos usando toda la información disponible y no se eliminan observaciones que pueden contener información importante para la labor de diagnóstico (Askarian et al. , 2016; Llanes-Santiago et. al. , 2018).
Son múltiples los trabajos encontrados que abordan las técnicas basadas en imputación o estimación de parámetros (Askarian et al. , 2016; Laencina et al. , 2010; Sovilj et al. , 2016). Sin embargo, todos los métodos realizan la imputación utilizando el conjunto de datos completo o parte del mismo y no se establecen requerimientos estrictos de tiempo.
En el caso de los sistemas industriales, las exigencias son muy elevadas. La imputación de las variables perdidas de una observación obtenida hay que hacerla en línea y con requerimientos de tiempo estrictos determinados por el período de muestreo que se ha establecido en el sistema de adquisición de datos. Además, hay que tener en cuenta que todas estas mediciones están afectadas por el ruido que es característico en los procesos industriales.
En los últimos años las redes neuronales de aprendizaje profundo han ido incrementando su popularidad por su capacidad de aprender características no lineales complejas que permiten mejorar significativamente el poder discriminativo en los procesos de clasificación. En Eren & Kiranyaz (2019), y Lee et. al. (2019) se propone el uso de redes neuronales convolucionales (CNN) que aprenden características altamente discriminantes directamente de los datos del sensor de entrada sin procesar, logrando un rendimiento competitivo con una configuración CNN simple y compacta. En Medina et. al. (2019), Chen et al. (2021) y Xiao et. al. (2019) se propone el uso de redes neuronales de aprendizaje profundo por su facilidad para aprender características importantes de señales sin un procesamiento previo. En Rezamand et. al. (2020) se propone el uso de la transformada wavelet para la detección de fallos en señales de vibración con un sistema híbrido de detección de fallos basado en una combinación de una red neuronal de regresión generalizada para imputación única (GRNN-ESI), análisis de componentes principales (PCA) y función de densidad de probabilidad basada en wavelets (PDF). Existen otras propuestas de combinación de diferentes herramientas para el análisis de señales para mejorar el rendimiento de los sistemas de detección de fallos, como el caso de Li et. al. (2021) donde se propone un método para crear modelos de detección de fallos solo a partir de datos normales para la detección de fallos en impresoras 3D.
El objetivo principal de este trabajo es proponer una metodología de diagnóstico de fallos para sistemas mecánicos presentes en la industria basada en un esquema híbrido que combina algoritmos de imputación de fácil implementación con herramientas de aprendizaje profundo. La metodología que se propone realiza la imputación en línea de los datos perdidos logrando elevados niveles de desempeño en la clasificación de los fallos a partir de utilizar una red neuronal de aprendizaje profundo de tipo LSTM (por sus siglas en inglés Long Short Term Memory). La propuesta presenta un comportamiento muy robusto ante la presencia de ruido y las posibles desviaciones que puede introducir el proceso de imputación de los datos perdidos. Lo anterior también constituye la principal contribución de este trabajo.
La organización del artículo es la siguiente: en la sección 2 se presentan: la metodología propuesta, las características generales de las herramientas utilizadas en la misma , el caso de estudio y el diseño de los experimentos. En la sección 3 se realiza el análisis y discusión de los resultados obtenidos. Además, se realiza una comparación de los resultados obtenidos por la propuesta con los obtenidos por otros esquemas de diagnósticos presentados recientemente en la literatura científica. Finalmente, se presentan las conclusiones.
2. MATERIALES Y MÉTODOS
2.1 Mecanismos de pérdida de información
En Little & Rubin (2014) se exponen los tres tipos de mecanismos de pérdida de información que se pueden presentar. Los mismos son:
Pérdida de información completamente aleatoria (MCAR): La probabilidad de que se pierda información de una variable X en una observación no está relacionada con las otras variables medidas ni con los valores de la propia variable X. Lo anterior indica que la pérdida de información no depende de los valores de entrada.
Pérdida de información aleatoria (MAR): La pérdida de información es independiente de las variables perdidas pero el patrón de pérdida de datos se puede predecir a partir del conjunto de las variables.
Pérdida de información no aleatoria (NMAR): El patrón de datos perdidos no es aleatorio y depende de las variables perdidas.
En los sistemas industriales el mecanismo de pérdida de información que mayoritariamente se presenta es el MCAR y es el que utilizaremos en este trabajo.
2.2 Metodología propuesta para el sistema de diagnóstico
Es conocido de la literatura científica que para la utilización de herramientas de diagnóstico de tipo supervisadas se requiere disponer de una base de datos que contenga la cantidad de observaciones necesarias del estado de funcionamiento normal y de cada uno de los estados de fallo de manera tal que se pueda realizar el entrenamiento de la herramienta a utilizar para lograr los mejores resultados en el proceso de clasificación (Watanabe et al. , 1989). Por lo anterior se dispondrá de un matriz de entrenamiento
En la Figura 1 se presenta la metodología propuesta para el diagnóstico de fallos en este trabajo. La misma está compuesta de dos etapas: fuera de línea y en línea.
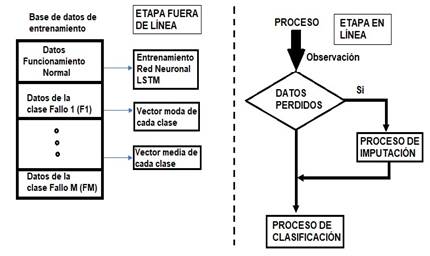
Figura 1 Metodología propuesta para el diagnóstico de fallos con mediciones ruidosas y datos perdidos
En la etapa fuera de línea, se realiza el entrenamiento de la red neuronal LSTM. Además, se obtienen los vectores con las medias aritméticas (
En la etapa en línea, cada vez que se recibe una observación se analiza si tiene datos perdidos o no. En caso de no tener datos perdidos se realiza el proceso de clasificación de la observación. En caso de que se detecten variables perdidas se realizará la imputación.
2.1.1 Proceso de imputación
Al recibirse una nueva observación con variables perdidas se realiza el siguiente procedimiento para imputar en línea:
Se recibe una observación en línea
Se realiza el proceso de imputación con el método que se haya decidido utilizar.
Una vez estimados todos los valores perdidos se clasifica la observación usando la herramienta de clasificación del sistema de diagnóstico.
Observación: Es posible que la herramienta de diagnóstico clasifique a la observación con los datos estimados en una clase diferente a la que fue asignada para realizar el proceso de imputación. La razón de esto se explica en el grado de solapamiento que pueden tener algunas clases en el espacio de las observaciones.
2.2 Herramientas para la imputación de los datos perdidos
En este trabajo, se utilizarán dos métodos de imputación: la media aritmética y la moda. Estos métodos fueron escogidos por su demostrada efectividad y la sencillez de su implementación.
Para la imputación de datos perdidos usando la media aritmética se utilizan los valores medios de las variables en cada clase calculados en el proceso fuera de línea (
Una manera de evitar los efectos que producen los datos fuera de rango es usando el valor de la moda de un conjunto de datos la cual representa el valor de información que más se repite en el conjunto. Usar el valor de la moda permite no tener que hacer un tratamiento de los datos de entrenamiento para eliminar los datos fuera de rango.
Al determinarse en la observación las variables perdidas y una vez clasificada la observación en una clase, se accede al vector de valores medios (
2.3 Red Neuronal LSTM
La red neuronal LSTM pertenece a la familia de las redes neuronales recurrentes (RNN). Son ideales en el aprendizaje, procesamiento y clasificación de datos secuenciales. Ella fue propuesta por Hochreiter y Schmidhuber en Hochreiter & Schmidhuber (1997) y posteriormente Gers (Ger et. al. , 2000) propuso una variación que mejoró su funcionamiento. Las redes LSTM tienen como objetivo superar el tema de la desaparición exponencial de los gradientes de error presentes en el entrenamiento por backpropagation de las RNN, utilizando compuertas para retener selectivamente la información que es relevante y olvidando la información que no es relevante. La sensibilidad más baja a la brecha de tiempo hace que las redes LSTM sean mejores para el análisis de datos secuenciales que las RNN.
En las unidades LSTM, cuando los valores de error son propagados de nuevo desde la capa de salida, el error permanece en la celda de la unidad LSTM. Este retorno del error alimenta continuamente el error a cada una de las puertas de la unidad LSTM, hasta que aprenden a eliminar el valor que no es relevante.
Una de las características principales de este tipo de arquitectura de aprendizaje profundo es que puede recordar estados previos, por lo que es un tipo de red muy utilizada en datos de series cronológicas. Las redes LSTM son capaces de aprender dependencias a largo plazo. El modelo almacena la información de la serie de tiempo en la memoria, basada en la importancia expresada por pesos que son aprendidos por el algoritmo. Una diferencia con respecto a las redes neurnales recurrentes (RNN), es el estado de la celda donde se puede agregar o eliminar información a través de estructuras reguladas conocidas como puertas. La arquitectura de la celda LSTM básica se muestra en la Figura 2. Normalmente, un bloque de LSTM tiene una celda de memoria, puerta de entrada, puerta de salida y una puerta de olvido.
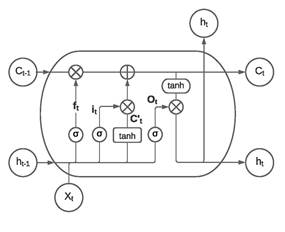
La primera etapa conocida como puerta de olvido, decide qué información se desechará. La función f t viene dada por la Ecuación (1), donde σ denota la función sigmoidea. La puerta lee h t−1 y x t y genera un valor de salida entre 0 y 1; donde 0 significa ”completamente descartado". y 1 ”completamente reservado".
El siguiente paso consiste en decidir qué nueva información se almacenará en la celda de estado indicado como C t . Esta tarea es realizada usando dos funciones. La puerta de entrada que es una función sigmoidea que decide qué valores se actualizarán y una función adicional tanh que crea un nuevo vector de valores candi datos, de acuerdo con las Ecuaciones (2) y (3). En estas ecuaciones, W representa los pesos y b la desviación o bias:
La combinación de ambas funciones permite actualizar el estado de la celda según lo propuesto por la Ecuación (4):
Finalmente, la salida de la celda está definida por la puerta de salida de acuerdo con la Ecuación (5) y (6):
La red LSTM propuesta utiliza el algoritmo de optimización ADAM (Adaptive Moment Estimation) (Kingma & Lei Ba , 2017), que es una extensión del algoritmo SGD (Stochastic Gradient Descent) y permite actualizar los pesos de la red de forma iterativa en función de los datos de entrenamiento.
2.4 Caso de estudio: DAMADICS
Para validar la propuesta de metodología que se presenta en este trabajo se va a utilizar el problema de prueba DAMADICS que representa un actuador electro-neumático inteligente de muy amplio uso en las industrias y representativo de un sistema mecánico (Bartys et al. , 2006). Toda la información relacionada con este proceso de prueba y los datos utilizados puede ser encontrado en http://diag.mchtr.pw.edu.pl/damadics/. Este actuador consta de las siguientes partes:
La estructura general de este actuador se muestra en la Figura 3.
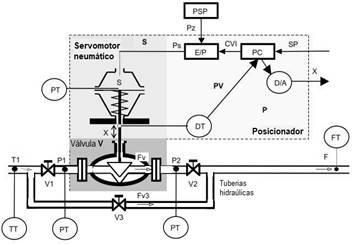
De manera general, el funcionamiento del actuador es el siguiente: la válvula de control actúa sobre el flujo del fluido que pasa a través de la instalación de la tubería. El servomotor realiza un cambio en la posición del obturador de la válvula de control, actuando sobre el caudal de fluido. El servomotor neumático de resorte y diafragma es un dispositivo accionado por fluido compresible en el que el fluido actúa sobre el diafragma flexible, para proporcionar movimiento lineal del vástago del servomotor. El posicionador ayuda a eliminar las posiciones incorrectas del vástago de la válvula de control producidas por las fuentes externas o internas tales como: fricción, holgura en montajes mecánicos, variaciones de presión de suministro, fuerzas hidrodinámicas, entre otros. En este actuador se diagnosticarán 5 fallos los cuales se muestran en la Tabla 1.
Tabla 1 Fallos simulados en DAMADICS
| Fallo | Descripción |
| 1 | Obstrucción de la válvula |
| 7 | Flujo crítico |
| 12 | Fallo del transductor electroneumático |
| 15 | Fallo del resorte del posicionador |
| 19 | Fallo del sensor de caudal |
Estos fallos fueron escogidos por ser representativos de diferentes partes del actuador y en el caso de los fallos F15 y F19 son fallos que sus patrones se superponen dificultando la clasificación correcta.
Las variables medidas se presentan en la Tabla 2
Índices para medir el desempeño 2.5
En este trabajo la robustez de la metodología propuesta se considera a partir de lograr un desempeño elevado de clasificación correcta con un bajo porciento de falsas alarmas tal y como se define en Patan (2008). Por lo tanto, para medir el desempeño y la robustez del sistema propuesto a partir de los resultados de la matriz de confusión, se utilizarán los siguientes índices:
Exactitud (Acc): Este indicador evalúa el desempeño general del clasificador. Se define como:
donde VP (Verdaderos Positivos) representa la cantidad de observaciones pertenecientes a una clase clasificadas correctamente, FP (Falsos Positivos) representa la cantidad de observaciones clasificadas erróneamente como correctas, VN (Verdaderos Negativos) representa la cantidad de observaciones no pertenecientes a una clase clasificadas correctamente como negativas y FN (Falsos Negativos) representa la cantidad de observaciones clasificadas como que no pertenecen a una clase y sin embargo si pertenecen a la misma.
Razón de Falsas Alarmas (FAR): Es un indicador importante porque indica la razón de observaciones correspondientes al funcionamiento normal que son clasificadas erróneamente como si fueran algún tipo de fallo y se define como:
2.6 Diseño de los experimentos
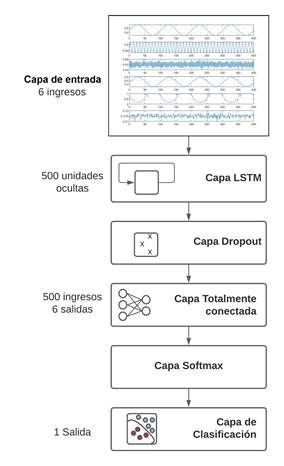
2.6.1 Arquitectura de la red LSTM
Para la aplicación en la propuesta realizada en este trabajo, la red LSTM se forma mediante la conexión en cascada entre varias capas como se muestra en la Figura 4. Primeramente se encuentra una capara de entrada que recibe las 6 variables que se miden en el proceso; una capa LSTM con 500 unidades ocultas con el formato de salida configurado en modo secuencia completa; una capa de tipo dropout para reducir el sobre-entrenamiento y mejorar la capacidad de generalización de la red; una capa totalmente conectada de 6 clases (correspondientes a los 6 estados de funcionamiento del sistema); seguida de una capa con la función exponencial normalizada o función softmax (Bishop , 2006) y una capa de clasificación a la salida.
2.6.2 Entrenamiento de la red
Una red LSTM se entrena de manera supervisada utilizando un conjunto de secuencias de entrenamiento. Para el entrenamiento se utilizó una combinación entre el algoritmo de optimización ADAM con parámetros β 1 = 0.9 y β 2 = 0.999 como fue propuesto en Kingma & Lei Ba (2017), combinado con el algoritmo BPTT (backpropagation through time) para calcular los gradientes necesarios durante el proceso de optimización, con el fin de cambiar cada peso de la red de LSTM en proporción a la derivada del error en la capa de salida, respecto al peso correspondiente. Como función de activación para actualizar la celda y el estado oculto se usó la función de activación tangente hiperbólica (tanh). El número máximo de épocas utilizadas para el entrenamiento fue de 500 y un umbral de gradiente igual a 2. Para prevenir un sobre entrenamiento de la red se incluyó la capa dropout con una probabilidad de descartar elementos de entrada, especificada como un escalar numérico igual a 0,1.
La tasa de aprendizaje (LR) es un parámetro importante que influye en el ajuste de pesos y la convergencia de errores. Al elegir una tasa de aprendizaje adecuada, podemos acelerar la convergencia de la red LSTM y mejorar su precisión. En este experimento, la tasa de aprendizaje empleada fue de LR = 0,001.
Para conformar la matriz de datos para el entrenamiento de la red neuroanl LSTM en la etapa fuera de línea se utilizaron k = 1000 observaciones de cada una de las nc = 6 clases (FN: Funcionamiento Normal, F1: Fallo 1, F7: Fallo 7, F12: Fallo 12, F15: Fallo 15, F19: Fallo 19) almacenadas con un período de muestreo de 1 segundo. En cada observación se leen los valores de las p = 6 variables descritas anteriormente en la Tabla 2. Lo anterior indica que la base de datos de entrenamiento está conformada por n = 6000 observaciones las cuales no tienen ruido asociado ni variables perdidas.
Para el entrenamiento y validación de la red neuronal LSTM propuesta en la etapa fuera de línea se utilizó el proceso de K-validación cruzada (Devijver & Kittler , 1982). En este caso se seleccionó K = 5.
Los resultados obtenidos en el proceso de entrenamiento se muestran en la Tabla 3.
Experimentos a realizar 2.6.3
Para realizar los experimentos relacionados con la etapa en línea, se utilizó una base de datos con 400 observaciones distintas a las usadas en el entrenamiento por cada estado de funcionamiento del sistema por lo que la base de datos para los experimentos estuvo formada por 2400 observaciones. Para garantizar la repetitividad de los resultados cada experimento fue repetido 100 veces y como resultado final se obtuvo el promedio de los resultados obtenidos en esas 100 repeticiones.
Se realizaron los siguientes experimentos para evaluar el desempeño del sistema de diagnóstico con las siguientes características en los datos:
Para cada experimento, la base de datos con las 2400 observaciones se preparó adecuadamente de acuerdo al tipo de experimento. Para los experimentos con ruido se adicionó a las observaciones un ruido blanco de media cero y con valor del 2% y del 5% del valor nominal de cada variable. Para esto se utilizó la relación señal/ruido (SNR) que se define de la siguiente manera:
donde P senal y P ruido son la potencia de la señal (variable medida) y del ruido adicionado respectivamente (Russ (2007)).
Para ejemplificar como varía la información de las variables con las variantes previstas en los experimentos y por lo tanto dar una idea de las exigencias a las que se somete la metodología propuesta , la Figura 5 muestra la variable que representa el desplazamiento del vástago en funcionamiento normal, en funcionamiento normal con pérdida de una variable en forma aleatoria e imputación con el valor medio de la misma en el funcionamiento normal y con las mismas condiciones anteriores añadiéndole 2% y 5% de ruido. La Figura 6 presenta la misma señal pero ahora con pérdida de información de 0 a 2 variables por observación de forma aleatoria y con 2% y 5% de ruido.
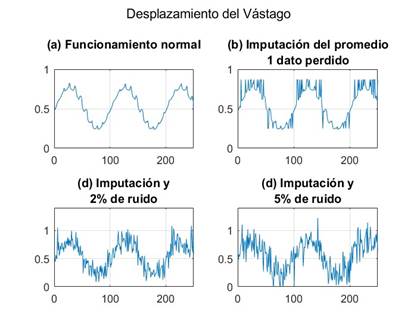
Figura 5 Señal del desplazamiento del vástago utilizada en los experimentos: a)Funcionamiento normal, b)Funcionamiento normal con pérdida e imputación de información, c)Funcionamiento normal con pérdida e imputación de información más 2% de ruido y d) Funcionamiento normal con pérdida e imputación de información más 5% de ruido

Figura 6 Señal del desplazamiento del vástago utilizada en los experimentos: a)Funcionamiento normal, b)Funcionamiento normal con pérdida de 0 a 2 variables e imputación de información, c) Funcionamiento normal con pérdida de 0 a 2 variables e imputación de información más 2% de ruido y d) Funcionamiento normal con pérdida de 0 a 2 variables e imputación de información más 5% de ruido
3. RESULTADOS Y DISCUSIÓN
3.1 Resultados del primer experimento
La Tabla 4 presenta los resultados del primer experimento.
Tabla 4 Matriz de Confusión para la clasificación de observaciones sin información perdida (a) Sin ruido (b) Con 2% de ruido. (c) Con 5% de ruido
| (a) | F1 | F12 | F15 | F19 | F7 | Normal | Acc(%) | FAR(%) |
| F1 | 393 | 0 | 0 | 0 | 0 | 7 | ||
| F12 | 0 | 398 | 0 | 0 | 2 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 22 | 378 | 0 | 0 | ||
| F7 | 4 | 0 | 0 | 0 | 396 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,167 | 0 | ||||||
| (b) | ||||||||
| F1 | 396 | 0 | 0 | 0 | 0 | 4 | ||
| F12 | 0 | 399 | 0 | 0 | 1 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 20 | 380 | 0 | 0 | ||
| F7 | 4 | 0 | 0 | 0 | 396 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,417 | 0 | ||||||
| (c) | ||||||||
| F1 | 397 | 0 | 0 | 0 | 0 | 3 | ||
| F12 | 0 | 398 | 0 | 0 | 2 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 18 | 382 | 0 | 0 | ||
| F7 | 3 | 0 | 0 | 0 | 397 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,542 | 0 |
Como se aprecia el sistema de diagnóstico alcanza un elevado desempeño. Los mayores niveles de confusión se producen entre el Fallo 15 y el 19 lo cual se debe a una cierta superposición que existe entre las dos clases. Además el sistema no genera ninguna falsa alarma (FAR=0%). Estos resultados indican un elevado nivel de robustez ante el ruido de la metodología propuesta.
3.2 Resultados del segundo experimento imputando con el valor medio
En el segundo experimento se eliminó una variable de forma aleatoria a cada observación de la base de datos. El sistema de diagnóstico al recibir cada observación primeramente realiza la clasificación de la observación según el procedimiento presentado en la sección anterior y posteriormente realiza el proceso de imputación con el valor medio de la variable perdida en esa clase.
La Tabla 5 muestra los resultados del segundo experimento.
Tabla 5 Matriz de Confusión para la clasificación de las observaciones con una variable perdida que es imputada con el valor medio (a) Sin ruido, (b) Con 2% de ruido, (c) Con 5% de ruido
| (a) | F1 | F12 | F15 | F19 | F7 | Normal | Acc(%) | FAR(%) |
| F1 | 393 | 0 | 0 | 0 | 0 | 7 | ||
| F12 | 0 | 400 | 0 | 0 | 0 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 23 | 377 | 0 | 0 | ||
| F7 | 4 | 1 | 0 | 0 | 395 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,167 | 0 | ||||||
| (b) | ||||||||
| F1 | 395 | 0 | 0 | 0 | 0 | 5 | ||
| F12 | 0 | 400 | 0 | 0 | 0 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 18 | 382 | 0 | 0 | ||
| F7 | 3 | 0 | 0 | 0 | 397 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,542 | 0 | ||||||
| (c) | ||||||||
| F1 | 395 | 0 | 0 | 0 | 0 | 5 | ||
| F12 | 0 | 400 | 0 | 0 | 0 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 20 | 380 | 0 | 0 | ||
| F7 | 3 | 0 | 0 | 0 | 397 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,458 | 0 |
Los resultados mostrados por la Tabla 5 vuelven a mostrar elevados niveles de desempeño y 0% de falsas alarmas que indican la satisfactoria robustez de la metodología propuesta ante la imputación por perdida de información y el ruido. Nuevamente el mayor error se produce en la clasificación del fallo 19.
3.3 Resultados del tercer experimento imputando con el valor medio
Para el experimento 3 se eliminaron de forma aleatoria entre 0 y 2 variables por observación. Cuando el sistema de diagnóstico recibe una observación, primero realiza la clasificación de la observación según el procedimiento presentado en la sección anterior y luego realiza el proceso de imputación con el valor medio de las variables perdidas en esa clase. Posteriormente se realiza la clasificación de la observación. Como en los experimentos anteriores se realizó la imputación y la posterior clasificación para las observaciones sin ruido, con ruido añadido del 2% y del 5%.
En la Tabla 6 se presentan los resultados obtenidos en el referido experimento.
Tabla 6 Matriz de Confusión para la clasificación de las observaciones con una cantidad aleatoria entre 0 y 2 variables perdidas (a) Sin ruido (b) Con 2% de ruido (c) Con 5% de ruido
| (a) | F1 | F12 | F15 | F19 | F7 | Normal | Acc(%) | FAR(%) |
| F1 | 393 | 0 | 0 | 0 | 0 | 7 | ||
| F12 | 0 | 398 | 0 | 0 | 2 | 0 | ||
| F15 | 0 | 10 | 390 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 11 | 389 | 0 | 0 | ||
| F7 | 4 | 0 | 0 | 0 | 396 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,583 | 0 | ||||||
| (b) | ||||||||
| F1 | 392 | 0 | 0 | 0 | 0 | 8 | ||
| F12 | 0 | 399 | 0 | 0 | 1 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 18 | 382 | 0 | 0 | ||
| F7 | 3 | 0 | 0 | 0 | 397 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,375 | 0 | ||||||
| (c) | ||||||||
| F1 | 392 | 0 | 0 | 0 | 0 | 8 | ||
| F12 | 0 | 398 | 0 | 0 | 2 | 0 | ||
| F15 | 0 | 9 | 391 | 0 | 0 | 0 | ||
| F19 | 0 | 0 | 15 | 385 | 0 | 0 | ||
| F7 | 3 | 0 | 0 | 0 | 397 | 0 | ||
| Normal | 0 | 0 | 0 | 0 | 0 | 400 | ||
| GEN | 98,458 | 0 |
En este experimento, se ratifica la elevada robustez de la metodología propuesta ante la presencia de variables perdidas y ruido y eso indica la excelente capacidad de generalización que logra la red neuronal LSTM.
3.4 Resultados de los experimentos 2 y 3 imputando con el valor moda
Experimentos similares a los experimentos 2 y 3 fueron desarrollados pero utilizando como método de imputación el de asignar el valor moda correspondiente a la variable que se va imputar en la clase a la que fue asignada la observación analizada. La Tabla 7 muestra los resultados obtenidos.
Tabla 7 Resultados de% de desempeño y% de falsas alarmas utilizando como método de imputación el valor moda
| Experimento | Exactitud (Acc)% | % FAR |
| Imputación con la moda | ||
| Datos con 1 variable perdida | 97,15% | 0% |
| Datos con 1 variable perdida y 2% de ruido | 97,78% | 0% |
| Datos con 1 variable perdida y 5% de ruido | 97,59% | 0% |
| Datos con 0 a 2 variables perdidas | 97,60% | 0% |
| Datos con 0 a 2 variables perdidas y 2% de ruido | 98,24% | 0% |
| Datos con 0 a 2 variables perdidas y 5% de ruido | 98,17% | 0% |
Los resultados alcanzados ratifican la robustez del sistema de diagnóstico propuesto.
Para saber si el método utilizado para imputar influye en los resultados que se alcanzaron, se aplicó el test estadístico no paramétrico de Wilcoxon con un nivel de significación α = 95% para comparar los experimentos similares (Luengo , 2009). Los resultados obtenidos indican que no hay diferencias significativas entre los resultados lo cual indica que cualquiera de los dos métodos se puede utilizar para imputar. Solo debe tenerse en cuenta que en caso de usar el valor medio debe lograrse eliminar previamente en la base de datos de entrenamiento los datos fuera de rango.
3.5 Comparación con otros resultados presentados en la literatura científica
Para comparar con otros algoritmos presentes en la literatura científica es necesario desarrollar experimentos con características similares. En toda la literatura científica revisada son pocos los trabajos que abordan el diagnóstico de fallos en presencia de ruido e información perdida y en los encontrados los experimentos fueron desarrollados para otros tipos de sistemas que no son sistemas mecánicos.
En la Tabla 8, se presentan los resultados de técnicas de diagnóstico en sistemas mecánicos publicadas en los últimos 5 años con excelentes desempeños y en ninguno de ellos fue considerado la pérdida de información en las observaciones y solo en algunos casos fue considerado el ruido en las mediciones. Cuando se comparan esos resultados con los obtenidos en este trabajo donde además del ruido hay perdida de información se puede comprobar que los resultados no tienen diferencias significativas lo cual indica la robustez de la metodología que aquí se ha presentado.
Tabla 8 Resultados de la comparación entre algoritmos de la literatura
| Referencia | Ruido | Datos perdidos | Precisión |
| Li et. al. (2016) | 97,68% | ||
| Saufi et. al. (2020) | X | 99,00% | |
| Medina et. al. (2019) | 96,60% | ||
| Lee et. al. (2019) | 98,66% | ||
| Chen et al. (2021) | X | 98,46% |
4. CONCLUSIONES
Los resultados económicos, la seguridad de los operarios y el cuidado del medio ambiente son elementos de gran importancia que hay que tener en cuenta en los requisitos que debe satisfacer la industria moderna. En este trabajo, se propuso una metodología para el diagnóstico de fallos en sistemas mecánicos que consta de una etapa fuera de línea y de otra etapa en línea, que logra elevados niveles de desempeño y robustez en presencia de datos perdidos y ruido en las mediciones. La metodología propuesta realiza la imputación en línea observación a observación en caso de que haya pérdida de información en las observaciones que obtiene el sistema de adquisición de datos, supervisión y control del proceso. Esto es una ventaja con respecto a muchas de las propuestas presentes en la literatura científica donde se necesita acumular un grupo de observaciones antes de realizar la imputación. El proceso de imputación se realiza utilizando el vector de valores medios y el vector de las modas de cada variable en cada clase. Estos métodos de imputación son muy sencillos de implementar y por su baja complejidad computacional permiten su aplicación en procesos con frecuencias de muestreo elevadas, lo cual representa otra ventaja. Para el proceso de clasificación se utilizó una red neuronal de aprendizaje profundo LSTM la cual es entrenada en la etapa fuera de línea logrando una elevada capacidad de generalización, demostrado en los experimentos realizados donde se obtienen altos índices de clasificación satisfactoria y muy bajos porcentajes de falsas alarmas en presencia de variables perdidas y ruido.
Los resultados de la metodología propuesta fueron comparados con otras metodologías presentadas en la literatura científica actual que muestran muy altos porcentajes de desempeño satisfactorio pero que sus resultados no tienen en cuenta la pérdida de información en las observaciones. Los resultados de la comparación demostraron que no existieron diferencias significativas en los altos niveles de clasificación satisfactoria y bajos porcentajes de falsas alarmas logrados. Lo anterior indica el elevado nivel de robustez de la propuesta realizada en este trabajo y por lo tanto las ventajas que ofrece con respecto a otros métodos presentes en la literatura científica.



