









 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
1. INTRODUCCIÓN
Uno de los objetivos principales del Centro de Modelización Matemática (MODEMAT), en el contexto de la pandemia del coronavirus, consiste en monitorear, a través del uso de modelos matemáticos, la expansión del virus SARS-CoV-2, y los casos de la enfermedad COVID-19 provocada por este patógeno en Ecuador. Para esto, utilizamos un modelo epidemiológico compartimental que incluye en su dinámica a los individuos infecciosos asintomáticos (ver detalles en Li et al (2020); Wu et al (2020); Verity et al (2020)), y estimamos periódicamente los diferentes parámetros del mismo, así como el número de reproducción efectivo de la epidemia.
La principal fuente de información para realizar dichas estimaciones son las estadísticas oficiales de casos confirmados reportados por el Ministerio de Salud Pública de Ecuador, las mismas que presentan un alto grado de incertidumbre, no sólo por el margen de error de las pruebas de laboratorio o la limitación de la cantidad de tests que se realizan, sino principalmente por los constantes cambios metodológicos (no siempre coordinados) que han implementado los diversos organismos oficiales para la recolección y el reporte de los casos.
En un escenario simplificado, el proceso de estimación de parámetros se realiza mediante técnicas de ajuste, las cuales consisten en construir una función matemática que se ajusta mejor a una serie particular de datos. En este contexto, el mejor ajuste implica que la distancia entre la curva y los datos, ubicados como puntos en un espacio predeterminado, debe ser minimizada, alcanzando un óptimo aproximado.
De manera general, la técnica de mínimos cuadrados no lineales consiste en identificar los parámetros que minimizan la suma de las diferencias al cuadrado entre los datos observados y el modelo no lineal utilizado. Así, supongamos que los parámetros identificados están dados por
donde
Sin embargo, una característica central en la modelización de epidemias y transmisión de enfermedades es que éstos son procesos que obedecen a una cierta dinámica epidemiológica de propagación. El contagio de una persona susceptible se entiende como un encuentro aleatorio con una persona infecciosa, sujeto a varias contingencias, como por ejemplo, la duración o la intensidad de dicho encuentro. De igual manera, las personas ya contagiadas pasan por un periodo de incubación del virus, para luego formar parte de los compartimentos de individuos infecciosos. Todo esto se modeliza a través de un sistema de ecuaciones diferenciales, que debe ser tomado en cuenta a la hora de ajustar datos observados. Así, la principal debilidad del esquema de ajuste de curvas descrito anteriormente es que no necesariamente toma en cuenta dicha dinámica de manera explícita.
Más aún, un proceso de ajuste de mínimos cuadrados de los datos observados puede resultar inadecuado en presencia de incertidumbre en las observaciones. Como se mencionó previamente, en el caso ecuatoriano dicha incertidumbre es sumamente alta en comparación con las estadísticas recogidas por agencias gubernamentales de otros países. Consecuentemente, un proceso de ajuste y estimación de parámetros en el caso ecuatoriano debe tomar en cuenta la incertidumbre como un elemento constitutivo del problema a resolverse.
En ese sentido, la propuesta que presentamos en este artículo consiste en considerar a los parámetros y la solución del modelo epidemiológico del SARS-CoV-2 como variables aleatorias con una cierta distribución de probabilidad y no como valores constantes. Con este cambio en la hipótesis de trabajo, podemos adoptar el paradigma Bayesiano para problemas inversos y estimar los parámetros de manera robusta, buscando minimizar la probabilidad condicional a-posteriori de los parámetros, dadas las observaciones.
2. ESTIMACIÓN DE PARÁMETROS EN PRESENCIA DE INCERTIDUMBRE
Como mencionamos previamente, una de las principales limitantes de los métodos de ajuste es que no consideran en su construcción la incertidumbre en los datos a ser ajustados, lo cual puede tener efectos importantes en situaciones como la que se presenta actualmente en Ecuador, en relación a la evolución de la COVID-19. Para abordar tal dificultad, optamos por el paradigma bayesiano, con el cual podemos estudiar el problema de estimación de parámetros considerando su carácter intrínsecamente aleatorio.
2.1 Estimador de probabilidad máxima a posteriori
En la inferencia bayesiana, a diferencia de la estimación de máxima verosimilitud, se supone que los parámetros (coeficientes, condición inicial, etc.) son una variable aleatoria
La idea básica de este enfoque consiste en combinar la información de las dos funciones de densidad de probabilidad descritas, utilizando la fórmula de Bayes, con el objetivo de obtener una probabilidad a posteriori de los eventos. En este caso, se supone que tanto las observaciones, como la información de fondo (estimaciones previas de los parámetros), tienen errores distribuidos normalmente con matrices de covarianza
y la función de densidad de probabilidad de los parámetros por
donde
Usando el Teorema de Bayes se obtiene que la distribución de probabilidad a posteriori de un evento
Ahora, dado que nuestro objetivo es hallar el mejor “estimador Bayesiano” utilizando la aproximación del máximo a posteriori, se busca maximizar la distribución de probabilidad a posteriori dada por (3). Puesto que
Aprovechando el hecho de que la función logarítmica
Finalmente, utilizando las funciones de densidad de probabilidad (1) y (2), obtenemos el problema de minimización equivalente
el cual constituye un balance robusto entre la información de fondo y los datos observados.
Las matrices
El problema de optimización (5) guarda estrecha relación con la estimación de máxima verosimilitud de los parámetros del sistema, obtenida a través de filtros de Kalman clásicos. En ambos casos, las observaciones son consideradas en un solo instante de tiempo, las cuales son corregidas a través de lo que se conoce como interpolación óptima o, equivalentemente, la resolución del problema variacional (5).
2.2 Esquema variacional en el tiempo
En los casos en que las observaciones son tomadas en distintos instantes del tiempo, el esquema bayesiano descrito anteriormente necesita ser adaptado para dar cuenta de la evolución de un sistema, así como de la variación de la incertidumbre. Este tipo de problemas ha sido abordado desde los dos enfoques comentados previamente: filtros de Kalman y métodos variacionales (ver, por ejemplo, Asch et al (2016)). En el primero de ellos, se adapta la construcción del filtro a un problema que varía en el tiempo, obteniéndose los denominados filtros de Kalman extendidos, los cuales requieren la solución de las ecuaciones diferenciales de Riccati. En el caso variacional, en cambio, el problema es formulado como uno de control óptimo y su solución requiere generalmente del método adjunto.
En nuestro caso, el problema de propagación del SARS-CoV-2 está asociado a la solución del sistema de ecuaciones diferenciales que determinan la evolución de los compartimentos poblacionales utilizados en el modelo. En tal razón, consideramos, de manera general, un sistema de ecuaciones diferenciales del tipo
donde
donde
La idea central detrás del proceso de estimación de parámetros dinámico es buscar un balance entre el conocimiento a priori que se tiene del fenómeno, lo que se conoce como el estado histórico o background, y el estado que ha sido observado o medido en el terreno. En el caso de los parámetros en la predicción de la evolución de la COVID-19 en el Ecuador, el estado histórico queda determinado por el conocimiento que se tiene del virus y su comportamiento, algo que ha sido bien establecido en estudios desarrollados, por ejemplo, en Li et al (2020). Por otro lado, el estado medido estaría dado por los resultados arrojados por la cifras nacionales que se obtienen por la toma de muestras, cifras de defunción, etc.
Extendiendo el problema (5), se busca entonces resolver el problema variacional
 (6)
(6)
donde
 (7)
(7)
en el cual la matriz
Dado que los operadores
donde suponemos que no hay errores en el modelo. De la misma forma, consideramos que las observaciones están dadas por
Suponemos que en el instante inicial
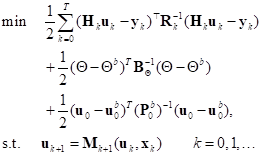 (10)
(10)
La solución de este problema consiste en el conjunto de parámetros del modelo que maximizan la probabilidad a posteriori, a partir de lo cual es posible hacer una estimación robusta de la evolución del fenómeno. En este problema, nótese que se consideran las observaciones en todo el período temporal para la correcta estimación de los parámetros.
Un elemento esencial en (10) son las matrices de covarianza de errores. Mientras que
Una de las técnicas más utilizadas para actualizar la matriz
3. PROBLEMA INVERSO PARA EL SARS-CoV-2
Uno de los mayores retos en el caso del SARS-CoV-2 es que muchas de las personas infectadas no presentan ningún síntoma, o desarrollan síntomas leves que pueden pasar desapercibidos. Esto hace que exista una importante fracción de la población infectada que no aparece en los registros y que son responsables de una gran cantidad de contagios, lo cual provoca a su vez que la modelización matemática de la propagación del virus y de la COVID-19 sea más compleja. Además, plantea retos a las autoridades sanitarias sobre el diseño eficiente y efectivo de cercos epidemiológicos y, sobre todo, diseño de campañas para la realización de pruebas tempranas a casos sospechosos, para su oportuno aislamiento.
La Organización Mundial de la Salud (OMS) sostiene que la mayoría de las personas (alrededor del 80%) se recupera de la enfermedad sin necesidad de realizar ningún tratamiento especial; alrededor de 1 de cada 6 personas que contraen la COVID-19 desarrolla una enfermedad grave; y, las personas mayores o las que padecen afecciones médicas subyacentes tienen más probabilidades de desarrollar una enfermedad grave. En torno al 2% de las personas que han contraído la enfermedad han muerto.
La familia de modelos matemáticos más usada para estudiar la proliferación de enfermedades virales son los modelos SEIR (por las siglas de Susceptibles, Expuestos, Infectados y Removidos). En estos modelos se crean compartimentos y se analizan las transiciones desde población susceptible a expuesta, la cual luego de un tiempo pasa a infecciosa, y de ésta, a removida. La remoción de los individuos se lleva a cabo mediante el aislamiento del resto de la población (cuarentena), la inmunización contra la infección (vacunación), la recuperación de la enfermedad con inmunidad total contra la reinfección o la muerte causada por la enfermedad (ver Brauer & Castillo-Chávez (2001)).
Para estudiar matemáticamente las particularidades del SARS-CoV-2, la variable personas infecciosas, en el modelo descrito anteriormente, se debe subdividir en dos compartimentos: personas infecciosas documentadas y no-documentadas. Así, los compartimentos poblacionales resultantes son: población susceptible, expuesta, infecciosa documentada, infecciosa no-documentada y removida. Estos compartimentos se acoplan entre sí mediante un sistema de ecuaciones diferenciales, que describe los flujos entre uno y otro, y que depende fuertemente de dos coeficientes dominantes: el índice de contagio (asociado al distanciamiento social) y la diseminación del virus por parte de los infecciosos no-documentados. Además, se incorpora información de movilidad humana entre ciudades o provincias, obteniéndose el siguiente sistema:
Aquí,
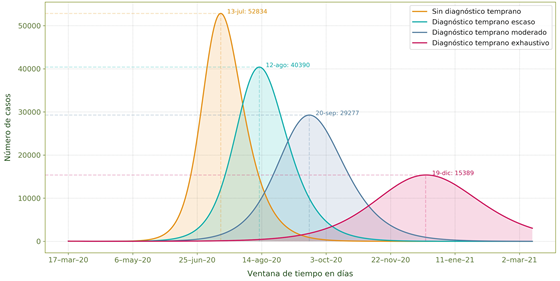
Figura 1 Escenarios de propagación del virus en pacientes con sintomatología fuerte en la provincia de Pichincha al 17 de marzo del 2020
Se considera que los pacientes con síntomas lo suficientemente fuertes como para ser documentados son los que representan
Un parámetro fundamental de la epidemia es el número efectivo de reproducción
Si este número se sostiene por encima de 1, la enfermedad seguirá expandiéndose (Ridenhour et al (2015)). Así, la meta es bajar este número por debajo de 1.
Finalmente,
Para la estimación de los diferentes parámetros en el modelo (11) usamos el esquema variacional presentado previamente (ver la subsección 2.2). Para la información de fondo de los parámetros, utilizamos los intervalos de confianza calculados en Li et al (2020) que, aunque obtenidos en un contexto socio-cultural distinto, proveen una primera estimación, así como una medida de la incertidumbre. Estos intervalos son los siguientes:
Tasa de transmisión de la población infectada reportada:
Factor de reducción de la tasa de transmisión de población infectada no reportada:
Factor multiplicativo de corrección de los datos de movilidad de la población:
Tiempo promedio de días de latencia:
Fracción de pacientes que desarrollaron síntomas fuertes:
Tiempo promedio de días de duración de la infección:
Asumiendo una sola provincia aislada e introduciendo el vector de parámetros
donde
donde
Al tener como restricción un sistema de ecuaciones diferenciales, el problema (12) debe ser tratado como un problema de control óptimo, en el cual la variable de estado es elemento de las funciones absolutamente continuas,
Sean
donde
con
Como primer paso para obtener el sistema adjunto, debemos calcular la derivada direccional del Lagrangeano respecto a la variable de estado,
Luego,
Finalmente, ya que la dirección fue tomada de manera arbitraria, de lo anterior, se sigue que el sistema adjunto está dado por:
El gradiente de la función objetivo se obtiene al derivar el Lagrangeano con respecto a la variable de control. Se procede de esta manera y obtenemos las siguientes ecuaciones:
Ya que los parámetros del problema pertenecen a un conjunto de controles admisibles
De manera adicional, ya que
4. RESULTADOS
En esta sección presentamos, a manera de ejemplo, los resultados de la estimación de parámetros del modelo (11) para la semana del 26 de junio al 2 de julio de 2020, así como las respectivas proyecciones quincenales de casos reportados de infectados con el coronavirus en diferentes provincias del país. Cabe indicar que este tipo de estadísticas son calculadas por el Centro de Modelización Matemática con una periodicidad semanal y puestas a disposición de los tomadores de decisión en materia de políticas de salud.
Para la estimación de parámetros, de lo expuesto en secciones anteriores, consideramos el vector de parámetros a estimar,
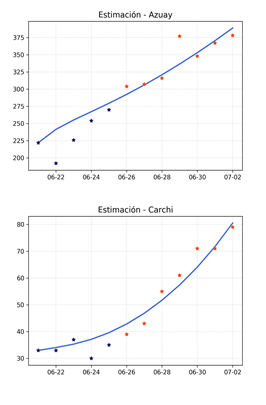
Figura 2 Estimación de parámetros en la semana del 26 de junio al 2 de julio de 2020, para las provincias de Azuay (arriba.) y Carchi (abajo.).
En la Figura 2, los puntos representan la información oficial del número de infectados reportados para cada provincia, siendo los de color naranja los correspondientes al periodo de estimación, es decir del 26 de junio al 2 de julio de 2020. Se presenta, además, en color azul, la información del número de personas infectadas en los 5 días anteriores al periodo de estudio, ya que debido al tiempo que transcurre entre la realización y la obtención de los resultados de las pruebas serológicas PCR, la condición inicial del problema se considera con 5 días de retraso.
Como resultado de la estimación se obtienen parámetros óptimos para el período de estudio considerado. La curva azul de la Figura 2 corresponde a la solución del modelo (11) para la variable
Con los parámetros obtenidos, calculamos adicionalmente el número de reproducción efectivo
En la Figura 3 se presenta la evolución del número de reproducción efectivo
Figura 3 Evolución del número de reproducción efectivo, para la provincia de Pichincha (arriba) y la provincia de Guayas (abajo).
La segunda parte de los resultados corresponde al pronóstico del número de personas infectadas oficialmente registradas. Estos pronósticos se los realiza de manera semanal para todas las provincias del país y para una ventana de tiempo de 15 días. Los parámetros que se utilizan son los calculados con la metodología descrita en este reporte. Adicionalmente, para resolver el sistema de ecuaciones consideramos aleatoriedad en los parámetros, las condiciones iniciales y los términos en el sistema de ecuaciones (Li et al (2020)). Para los parámetros y las condiciones iniciales consideramos perturbaciones normales, mientras que la estocasticidad de las ecuaciones se refleja a través de distribuciones de probabilidad de Poisson.
Para cada provincia la simulación se ejecuta con un ensamble de tamaño 80. Los resultados de estas simulaciones se presentan en la Figura 4 con líneas de color azul; para cada una de estas corridas la condición inicial es perturbada. En anaranjado se presenta la media de todas las simulaciones realizadas, mientras que el área gris representa el intervalo de confianza al 95% para el valor medio calculado. Como resultado, de entre todas las simulaciones realizadas presentamos las tres más significativas: escenario optimista (menor número de infectados reportados), escenario pesimista (mayor número de infectados reportados) y el pronóstico promedio.
En la Figura 4 se muestran las proyecciones de los casos reportados de COVID-19 (número de personas infectadas reportadas por las autoridades) de 8 de las 24 provincias del país, para el periodo del 3 al 18 de julio. La condición inicial fue tomada el día 2 de julio de 2020.
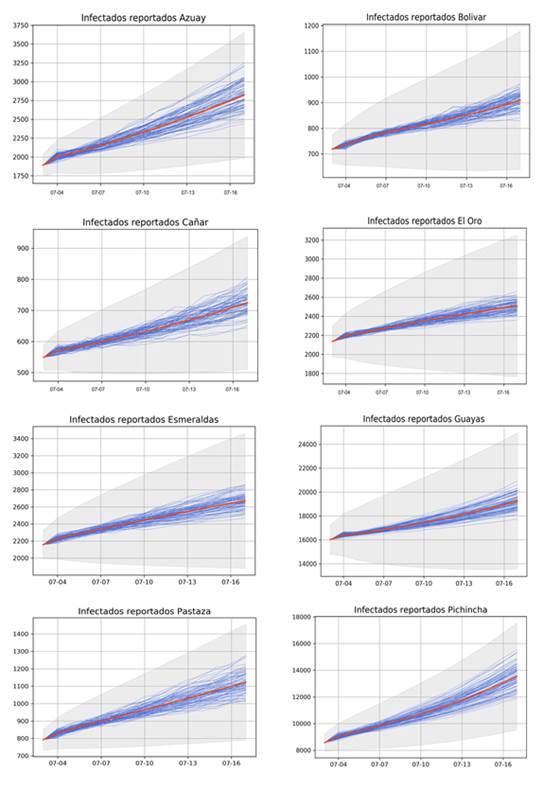
Figura 4 Pronóstico de infectados reportados acumulados para el periodo del 3 al 18 de julio del 2020. 1ra fila: Azuay(izq.), Bolivar(der.). 2da fila: Cañar(izq.), El Oro(der.). 3ra fila: Esmeraldas(izq.), Guayas(der.). 4ta fila: Pastaza(izq.), Pichincha(der.).
Además de los reportes gráficos, para cada provincia se obtienen tablas con los valores numéricos de los escenarios pesimista, optimista y promedio. En la Figura 5 observamos las tablas con los valores de los pronósticos para el periodo del 3 al 18 de julio del 2020 para las provincias de Esmeraldas y Santa Elena.

5. CONCLUSIONES
El monitoreo de la pandemia del SARS-CoV-2 en Ecuador requiere de la estimación rigurosa de diferentes indicadores de interés bajo condiciones de incertidumbre. Uno de las cantidades más importantes en este sentido es el número de reproducción efectivo de la pandemia, el cual requiere de la estimación robusta de los parámetros de un modelo matemático que recoja adecuadamente la dinámica viral. En este artículo presentamos el esquema desarrollado para llevar a cabo dicha tarea de manera periódica en cada región de estudio, proveyendo una herramienta importante de monitoreo y toma de decisiones.
La estimación de parámetros mediante técnicas variacionales, que utilizan un enfoque bayesiano brinda ventajas sobre otros métodos de estimación. Particularmente, en el caso ecuatoriano, esto resulta importante debido al alto nivel de incertidumbre proveniente de la data oficial; un factor determinante que no es considerado en otros enfoques.
La metodología para la construcción de las matrices de covarianza, presentes en el funcional de costo, permite incorporar la mencionada incertidumbre. En efecto, la construcción de
Las soluciones del sistema de ecuaciones que modelan la propagación del virus, dependen fuertemente de los parámetros del modelo, siendo los dos coeficientes dominantes: el índice de contagio y la diseminación del virus por parte de los infecciosos no-documentados. En este sentido, las soluciones que más se aproximen a la realidad en el caso ecuatoriano serán aquellas cuyos parámetros hayan sido estimados utilizando una metodología que considere las particularidades de la región de estudio, como las descritas en este artículo.
Las proyecciones de propagación del virus consideran aleatoriedad en los parámetros, las condiciones iniciales y los diferentes términos en el sistema de ecuaciones diferenciales del modelo. Gracias a la aleatoriedad podemos realizar varias simulaciones y presentar distintos escenarios para cada región de estudio.