











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
El transformador de potencia es el activo más caro de una subestación [1], siempre debe mantenerse en óptimas condiciones para que la red eléctrica sea fiable y eficiente. Las fallas en transformadores de potencia causan daños importantes, provocando paras del servicio eléctrico. El análisis de gases disueltos (AGD) se utiliza para la interpretación de fallas incipientes en aceite dieléctrico [2], además de otra prueba como el análisis físico químico como parte de un mantenimiento preventivo. Si bien es cierto, el método de AGD es utilizado por los expertos para determinar el tipo de falla interna dentro del transformador, a veces se deben valer por más muestras para garantizar un correcto resultado y esto conlleva a tiempo e inversión económica, aun así, sigue la interrogante si los datos recolectados corresponden a la falla exacta del transformador.
El uso del aprendizaje automático para la detección de fallas en transformadores ya se han venido realizado con poco éxito debido a la cantidad reducida de datos analizados por medio de la implementación de redes neuronales artificiales (RNA), máquina de soporte vectorial (SVM), lógica difusa, entre otros [3], [4], [5], [6], [7], los artículos citados fueron tomados para la implementación de clasificadores de bosques aleatorios debido a que la presente metodología funciona de mejor manera clasificando pocos datos.
El presente trabajo muestra una corroboración de diagnóstico a los resultados de pruebas AGD aplicados a diferentes transformadores de potencia sumergidos en aceite mineral, resultados en base a artículos científicos e investigaciones publicadas que sirven de comparación frente a la propuesta de uso de aprendizaje automático con bosques aleatorios para determinar las fallas internas en transformadores de potencia.
El siguiente documento se distribuye de la siguiente manera: La teoría utilizada para esta investigación se contempla en la sección 2, el modelo utilizado para este trabajo en la sección 3, la implementación del algoritmo utilizado para el entrenamiento en la sección 4, el análisis de resultados en la sección 5 y por último las conclusiones previstas en la sección 6.
MÉTODO DE DIAGNÓSTICO
Los gases combustibles relacionados con las fallas en transformadores se deben a la descomposición del aceite mineral, generando moléculas de gas como el hidrógeno (H2), el metano (CH4), el etano (C2H6), el etileno (C2H4) y acetileno (C2H2) [8], el número de concentración de gas se mide en partes por millón (ppm).
Los tres principales tipos de fallas de los transformadores de potencia que pueden identificarse de forma fiable mediante una inspección visual del equipo después de que la falla se haya producido son las descargas parciales, el sobrecalentamiento térmico y el arco eléctrico [9].
Las descargas parciales y los arcos voltaicos se refieren a fallas eléctricas y corresponden al deterioro del aislamiento debido a la alta tensión eléctrica. Las fallas térmicas se refieren al deterioro del sistema de aislamiento como resultado de un aumento de la temperatura anormal. Estas subidas se producen por el sobrecalentamiento de los conductores, los cortocircuitos, el sobrecalentamiento de devanados debido a las corrientes de Foucault, conexiones sueltas y una refrigeración insuficiente [10]. De acuerdo con la norma IEC 60599 y IEEE C57-104, estos principales tipos de fallas pueden clasificarse a su vez en 6 tipos de fallas de transformadores, que se resumen en la Tabla 1.

Métodos de Relación de Gases
Estos métodos son convenientes para la detección de fallas en el transformador y pueden ser analizados por los programas informáticos. Además, la concentración de un gas puede ser muy pequeña. Por lo tanto, se puede utilizar la relación de un gas con otro gas en lugar de la concentración de un gas como la Tabla 2. Las desventajas de estos métodos son que pueden no ser siempre analíticos o, en algunos casos, los resultados son inexactos.
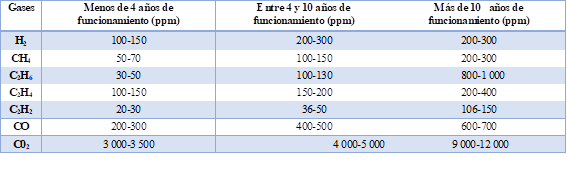
Método Dürrenberg
Este método puede utilizarse para detectar tres tipos principales de fallas, como el calentamiento, la corona de baja intensidad, la descarga parcial y el arco. El método utiliza cuatro relaciones de gas R1 (CH4/H2), R2 (C2H2/ C2H4), R3 (C2H2/CH4) y R4 (C2H6/C2H2). En primer lugar, se determinan las concentraciones de los gases en el aceite para ver si estos valores son superiores a los límites L1 permitidos o no [12], (ver Tabla 3).
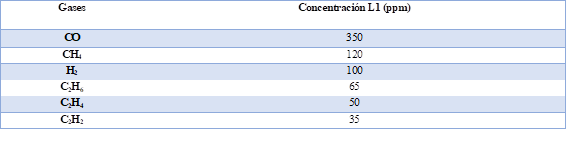
Si la concentración mínima de uno de los gases H2, CH4, C2H4 y C2H2 supera el doble de los valores límite L1 y uno de los otros tres gases supera el L1, se considera que el transformador tiene la avería [12]. Cada una de las cuatro relaciones R1 (CH4/H2), R2 (C2H2/ C2H4), R3 (C2H2/CH4) y R4 (C2H6/C2H2) se comparan con los valores indicados en la Tabla 4.

Relación de Rogers
Este método es en realidad el método mejorado de Dürrenberg. Esta técnica tiene a menudo una precisión de más del 80% en los gases solubles, se utilizan dos relaciones de las cuatro relaciones introducidas por Dürrenberg, incluyendo R1 (CH4/H2) y R2 (C2H2/C2H4) con dos nuevas relaciones (C2H4/C2H6) y (C2H6/CH4). La identificación de los fallas se realiza mediante los códigos mostrados en la Tabla 5 [8].
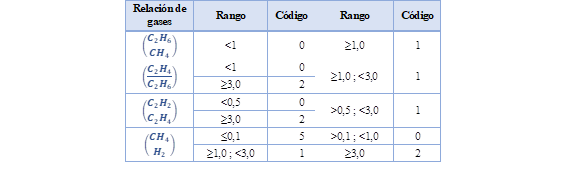
Utilizando los códigos de relación de gases presentados en la Tabla 5, pueden identificarse doce tipos de fallas diferentes de acuerdo con la Tabla 6 [11].

Método de relación IEC
Debido a que la relación (C2H6/ CH4) sólo muestra un rango limitado de degradación del aceite, es limitado [11]. Las tres relaciones de gas restantes tienen diferentes rangos de temperatura en comparación con el método de Rogers [11]. El código de la relación de gases se indica en Tabla 7 y las fallas se dividen en 9 categorías diferentes como se muestra en la Tabla 8.

En [11] s e introducen otras dos relaciones de gas para identificar las fallas específicas, se recomienda que el valor (C2H2/H2) sea superior a 3 para detectar la contaminación debida al funcionamiento del cambiador de tomas. Del mismo modo, que la relación (O2/N2) es inferior a 0,3, el fenómeno de calentamiento inusual u oxidación del aceite es determinado.

Método del triángulo de Duval
La tabla 9 corresponde a las categorías de fallas dictadas por Duval, lo que significa que hay 6 tipos de fallas en el triángulo de Duval y hay 7 tipos de fallas en el triángulo de Duval modificado [13], este último es el utilizado actualmente por las normativas IEC 60599 e IEEE C57-104.

El triángulo de Duval utiliza los gases CH4, C2H4 y C2H2 en los que sus generaciones corresponden a un aumento de los niveles de energía en el transformador. Los tres lados del triángulo se expresan en términos de (x, y, z) que son, respectivamente, las concentraciones relativas de CH4, C2H4 y C2H2 en porcentaje [13]. Suponiendo que A, B y C son las concentraciones relativas de CH4, C2H4 y C2H2 en términos de ppm respectivamente, entonces x, y y z son como se menciona a continuación:
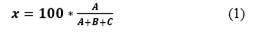


Hay que tener en cuenta que x, y y z están en el rango de 0-100% y las coordenadas con (x0, y0, z0), sólo especifican un punto dentro del triángulo. El tipo de falla también está determinado por la zona en la que se encuentra el punto (x0, y0, z0) [13].
Es importante señalar que la mayor parte del aceite mineral utilizado en los transformadores no produce ninguna cantidad medible de gases a temperaturas inferiores a 300 °C [1], sin embargo, algunos aceites minerales producen H2 y CH4 a una temperatura muy baja (100 °C) al principio de su vida útil, este hecho se produce en el primer año de servicio del transformador y es un proceso irreversible. La concentración de estos dos gases alcanza un nivel constante después de un tiempo de trabajo del transformador. Los valores de estos dos gases para el aceite deben ser considerados con el fin de evitar las interpretaciones erróneas de los resultados.
APRENDIZAJE AUTOMÁTICO
El aprendizaje automático consiste en codificar programas que ajustan automáticamente su rendimiento en función de su exposición a la información de los datos. Este aprendizaje se consigue mediante un modelo parametrizado con parámetros ajustables automáticamente en función de diferentes criterios de rendimiento. Las técnicas de aprendizaje automático pueden dividirse, a grandes rasgos, en dos grandes clases, aunque a menudo se añade una más [14]. Estas son las clases:
Aprendizaje supervisado
Aprendizaje no supervisado
Aprendizaje por refuerzo
Aprendizaje Supervisado
Algoritmos que aprenden a partir de un conjunto de ejemplos etiquetados para generalizar al conjunto de todas las entradas posibles. Ejemplos de técnicas de aprendizaje supervisado: regresión logística, máquinas de vectores de apoyo, árboles de decisión, bosques aleatorios, etc. [15].
Bosques aleatorios
Los bosques aleatorios es un algoritmo de aprendizaje automático muy preciso, mucho más robusto que los árboles de decisión y capaz de modelar enormes espacios de características [16].

Figura 1: Límites de Decisión Encontrados por Cinco Árboles de Decisión Aleatorios y el Límite de Decisión Obtenida al Promediar sus Probabilidades Predichas. Fuente: [17]
En la Fig. 1 se visualiza el proceso de aleatoriedad compuesto por cinco árboles a un conjunto de datos, se puede ver claramente que los límites de decisión aprendidos por los árboles son bastante diferentes, cada uno de ellos comete algunos errores, ya que algunos de los puntos de entrenamiento que aparecen aquí no se incluyeron realmente en los conjuntos de entrenamiento de los árboles, debido al muestreo bootstrap que realiza el algoritmo.
El bosque aleatorio se ajusta menos que cualquiera de los árboles por separado, al encontrar más rápido la clasificación de cada muestra tomada y proporciona un límite de decisión mucho más intuitivo al resultado final.
APLICACIÓN DE BOSQUE ALEATORIO AL AGD
Para la aplicación de algoritmos de bosques aleatorios en el análisis de gases disueltos en aceite dieléctrico se designa 4 estados de diagnóstico como se observa en la Tabla 10.

Trabajar con datos numéricos resulta más fácil para el algoritmo, por tal motivo se designa para este trabajo los estados de la Tabla 10 como números del 1 al 4, que se interpreta como el resultado de diagnóstico de AGD.
Análisis de Datos
Para el entrenamiento del algoritmo se realiza la recolección de datos de pruebas de AGD realizados a varios transformadores mediante bibliografía recolectada para esta investigación, obteniendo 128 datos para el entrenamiento [3], [4], [5], [6], (ver Fig. 2) y 64 datos de prueba [7], [3], (ver Fig. 3) con 5 principales gases a evaluar para garantizar el aprendizaje del algoritmo mediante la aplicación de bosques aleatorios.

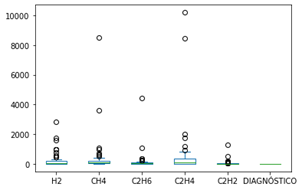
En la Tabla 11 se observa la distribución de datos recolectados para su entrenamiento y prueba, con la cantidad de gases por cada estado de diagnóstico analizado.

La categoría 4 (Sobrecalentamiento) es la mayoritaria, seguida por la categoría 1 (Descarga de alta energía). Las categorías con menos datos (de entrenamiento y prueba) son las categorías 3 y 2 respectivamente.
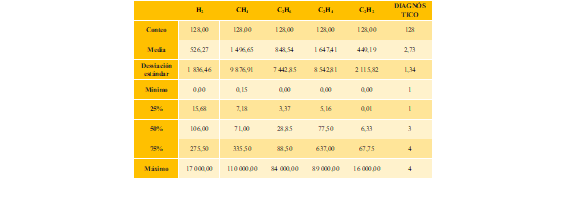
Al analizar los datos de entrenamiento (ver Tabla 12) la desviación estándar para cada una de las características se observan valores altos con respecto a su valor promedio, lo que indica que cada característica no se encuentra concentrada en un rango específico sino más bien distribuida en un amplio rango de valores. De manera que es más viable el uso de modelos tipo bosques aleatorios.
En la Fig. 4 se presenta la matriz de correlación de los 5 tipos de gases analizados.
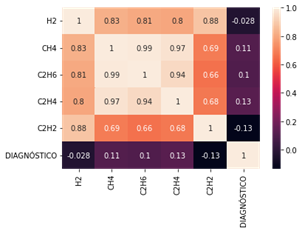
Al realizar un análisis de correlación entre las características se encuentra que hay una alta correlación (cercana a 1) entre los pares de características CH4 - C2H6, CH4 - C2H4 y C2H4 - C2H6. Esto indica que probablemente no todas las características resultarán igualmente relevantes al momento de elegir la categoría a la que pertenece cada dato.
ANÁLISIS DE RESULTADOS
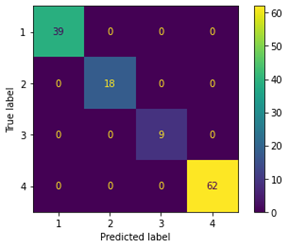
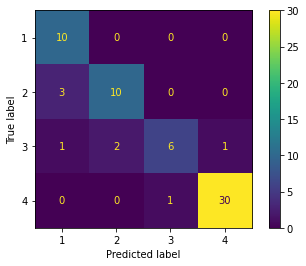
Teniendo en cuenta el tamaño limitado del set de entrenamiento, se optó por usar el enfoque de validación cruzada para la selección del modelo y evaluación. El modelo se realiza mediante un proceso sistemático de selección de hiperparámetros que arrojan el mejor desempeño posible (recall) para cada categoría evaluando el desempeño de clasificación comparando el valor verdadero y el valor predicho. En la Fig. 5 se muestra la matriz de confusión de datos de entrenamiento.
Para el modelo de bosque aleatorio se realizó un análisis de importancia de features que permite determinar aquellas características que resultan más relevantes al momento de la clasificación (ver Fig. 6).
Los resultados de recall alcanzados por el algoritmo de entrenamiento frente a los datos de prueba se obtiene el siguiente desempeño de asertividad (ver Tabla 13).

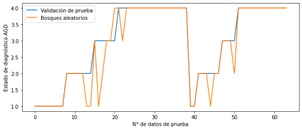
Una vez completado el entrenamiento se realiza la validación de prueba con las 64 muestras de AGD con el respectivo diagnóstico de falla aplicando el algoritmo de bosques aleatorios (ver Fig. 7).
CONCLUSIONES Y RECOMENDACIONES
Se usa el algoritmo de bosques aleatorios debido a que tiene un mayor desempeño al trabajar con pocos datos de entrenamiento 128 datos y 64 datos de prueba, el resultado obtenido de recall en cada categoría es un 100% en entrenamiento para los 4 estados, mediante la validación de prueba se obtiene un 100% para el diagnóstico de descarga de alta energía, 77% para descarga de baja energía, 60% para estado normal y un 97% para el estado de sobrecalentamiento. Obteniendo 78 resultados acertados y 8 datos incorrectos en su validación.
El modelo de bosque aleatorio es el más adecuado para realizar la clasificación con los sets de datos proporcionados, sin embargo, se debe tener en cuenta que el modelo tiene algo de overfitting, debido a que tiene un mejor desempeño con el set de entrenamiento que con el de prueba. Esto es de esperar dado al reducido número de datos de entrenamiento disponibles no permite un mejor desempeño del algoritmo. De igual forma se debe tener en cuenta que por contar con un set desbalanceado, se obtuvieron mejores desempeños para las categorías 1 y 4 y que el desempeño disminuye para las categorías minoritarias (2 y 3).
A futuro se sugiere recolectar más datos de entrenamiento y prueba, lo que redundará probablemente en un mejor desempeño del modelo, el algoritmo permite predecir un diagnóstico de falla mediante las pruebas de análisis de gases disueltos en transformadores de aceite dieléctrico, método diferente a los presentados en la sección 2 que generalmente se utilizan, el objetivo de este trabajo es corroborar los resultados mediante la aplicación de aprendizaje automático con el uso de bosques aleatorios.

