











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
En la actualidad, gracias a internet la comunicación en tiempo real con personas no identificadas resulta posible. El desarrollo de identidades ocultas (Bauman, 2000) detrás de cada intercambio comunicativo es posible a través de redes sociales; no obstante, tiene importantes consecuencias debido a que -en ocasiones- puede llegar a facilitar conductas criminales (Perverted-Justice, 2008/2019). El presente estudio se ubicó en los delitos cibernéticos de carácter sexual que, pese a que continúan en un largo proceso de legislación, se comportan como frecuentes.
Por otro lado, la infancia con acceso a las redes sociales en línea (online) se conforma como uno de los sectores más vulnerables a delitos como abuso/explotación sexual, trata, trabajos forzosos y rapto (Interpol, 2023), debido a la facilidad de prestadores para ocultar sus identidades y al uso descuidado del internet por parte de la comunidad infantil, lo que propicia una situación de constante riesgo.
Dentro de este contexto, el ambiente tecnológico crea un marco de convivencia, un ambiente para los usuarios online que atienden a características textuales específicas -que comparten como comunidad- pero distintivas -de otras comunidades-, por esto, se considera plausible la creación de posibles y futuras taxonomías textuales que compongan un perfil -donde las piezas léxicas funcionen como señales que den pie a la configuración de módulos temáticos para el posterior armado de un perfil lingüístico- cada vez más acotado, que represente una identidad grupal online sistemática.
El presente trabajo busca construir un acercamiento a un perfil lingüístico -mediante un corpus- donde se reconozcan patrones lingüísticos (Sacks, 2010; Schegloff, 2012; Sacks et al., 2015), recurrentes (MacMartin & Wood, 2007) y detectables (Rashid et al., 2013). Este objetivo se integra a la construcción de una posible identidad lingüística online (Chiang & Grant, 2019); en este caso, describe a una comunidad lingüística.
En otras palabras, el presente análisis ejecuta un primer acercamiento -en el idioma español- a la frecuencia de piezas léxicas; en este caso particular, se refiere a la identificación gramatical de nominales, verbos y adjetivos, de carácter sexual o sexualizado (en el documento se entiende por sexualización todo uso del lenguaje con connotación, significado y sentido sexual, a toda construcción sintáctica o pieza léxica que sea propia del campo de la sexualidad (órganos sexuales) y sus alcances (relaciones o contactos sexuales)).
Asimismo, se consideran los cambios de significado o doble sentido que se apoyen de símiles, atenuaciones o ejemplificaciones, que respondan o referencien al carácter sexual, teniendo como meta su reconocimiento a nivel léxico, y de agrupación a nivel pragmático por medio de las intervenciones y la clasificación en módulos por temas que, de acuerdo con la función comunicativa comprendida, arrojen como resultado la generación de un perfil lingüístico.
METODOLOGÍA
El presente artículo de investigación utilizó métodos empíricos que parten esencialmente de la lingüística forense y de corpus que plantea la evaluación de un perfil lingüístico que implica distintos niveles. La lingüística forense, define Esteva (2016), se erige como un tema amplio que requiere mucho por granjear en la lengua española para generar un estudio puntual:
. (p. 15)En último término, cabría incluir (…) los estudios sobre dialectología, sociolingüística, semántica, pragmática y psicolingüística forenses enfocados a la elaboración de perfiles lingüísticos, los cuales servirán de ayuda en la investigación policial previa y en la posterior judicial para la preparación de la vista oral, puesto que podrían identificar a los posibles autores de textos orales y escritos
Debido a que se busca “
” (Esteva, 2016, p. 15) estriba en distintos niveles y precisiones de la lengua y, a su vez, en los hablantes específicos. Este primer acercamiento busca encontrar ejes temáticos en el modus operandi de lengua escrita online de los posibles agresores como comunidad lingüística.lograr una identificación de hablantes; el análisis o la atribución de autoría de textos escritos
IDENTIDAD ONLINE Y PERFIL LINGÜÍSTICO
La representación de un perfil lingüístico, sus ejes y posibilidades como estudio interdisciplinario requieren fundamentos que lo soporten y que planteen la identidad lingüística y la identidad online o performance (Bauman, 2000) como un concepto básico .
Así, para el asentamiento de esta base, la psicolingüística y la lingüística aplicada forense suelen colaborar, aunque también se utiliza la sociolingüística (condicionamientos por edad, género, lugar de origen, entre otros) y la pragmática (acotamientos de circunstancias específicas del momento del habla), especialmente mediante el uso de investigaciones de género, edad (Argamon et al., 2007) y de jerarquía de los hablantes aunada a su proyección en los diferentes tipos de discursos (Ehrlich, 2007). Cada disciplina delimita y matiza la acotación en la expresión textual.
Para este propósito, deviene necesario partir de un amplio espectro de estudios: el análisis del discurso por Rojas & Suárez (2008), la lingüística forense por Turell (2010) y de corpus de Rayson (2015), Stefanowitsch (2020), Cheng (2009) como ramas generales por medio de una indagación especializada.
En primer lugar, desde el análisis del discurso existe una serie de estructuras sintácticas e interpretaciones dentro de un marco de alternativas y ambigüedades recurrentes en contextos específicos (Sacks et al., 2015).
Las técnicas lingüísticas utilizadas pueden ser descritas o identificadas mediante la ocurrencia de unidades -sintácticas, léxicas o de estrategias discursivas- en la interacción -sin hablar de estilística- regidas por motivaciones.
Asimismo, la conversación contiene reglas generales de intercambio comunicativo (saludo, invitaciones, proposiciones, despedida, entre otros; expresado como turnos bajo sistemas operantes con distribuciones, secuencias y transferencias evidentes), con unidades como las secuencias lingüísticas que pueden describirse, organizarse y clasificarse para dar pie a modelos que permiten adecuaciones para afiliaciones de comunidades (Tannen et al., 2015). De esta manera se construye secuencias desde los turnos con una guía elegida (Sacks, 2010), en este caso, léxica.
Es preciso exponer un marco del estudio pragmático para la creación del perfil de frecuencia de módulos, en virtud de que se extraen los turnos de habla del posible agresor y, posteriormente, solo las intervenciones explícitamente sexuales que conduzcan a identificar un perfil lingüístico específico.
De este modo, resulta imprescindible reconocer las guías esenciales del análisis del discurso (Calsamiglia & Tusón, 2001; Jaworski & Coupland, 2014; Schiffrin, 2003; Van Dijk, 1997). El intercambio comunicativo, investigado por Sacks et al. (2015) en la interacción de turnos; en la conducta comunicativa (Goffman, 1955); en contextos específicos y generales (Sacks, 2010); y en la organización de las secuencias en la interacción comunicativa (Schegloff, 2012).
Por otro lado, ciertas investigaciones muestran ejes de análisis para la identificación de personas e identidades digitales en crímenes cibernéticos (Rashid et al., 2013), donde se realizan comparación de estilos, análisis categorial y de discurso, focalización en los patrones de interacción en tiempo real con categorizaciones de campos semánticos, la huella del estilo de lenguaje (emojis, puntuación y vocabulario), análisis del lenguaje natural y estructural de las identidades engañosas, además de las diferentes estrategias lingüísticas en las formas de control de los tópicos (Chiang, 2019; Chiang & Grant, 2019; Tannen, 2016; Tusón, 2016; Brookes & McEnery, 2020).
Estos elementos contribuyen a la construcción de mecanismos que concretan la atribución de una identidad textual o lingüística que, inicialmente, suele generarse con base en descripciones de un estilo lingüístico con frecuencia de patrones en distintos niveles.
El gran abanico de posibilidades del lenguaje hace difícil comprometerse con patrones rígidos de expresión textual; sin embargo, pese a ser conscientes de la libertad infinita de expresión que se tiene, es un hecho que los humanos tienden a un comportamiento repetitivo (Grant & MacLeod, 2016).
Por su parte, la lingüística computacional trabaja con piezas léxicas, estructuras recurrentes, detecciones de perfiles o de atribuciones de autoría (Sierra et al., 2020) proyectados en la sistematización mediante técnicas y métodos computacionales, huellas dirigidas a una atribución/identificación de autoría.
A su vez, la lingüística de corpus realiza análisis masivos -perfil de frecuencia, concordancia, colocación, grupos o paquetes léxicos en distintos niveles de la lengua- (Rayson et al., 2016), señala frecuencias; además, describe el comportamiento de las piezas léxicas en diferentes niveles lingüísticos en función de encontrar patrones y repeticiones de datos.
Finalmente, desde la lingüística forense se plantean varios métodos: la acústica forense; la comparación forense de textos escritos e informe pericial; la elaboración de una identidad que atiende estudios de conducta con atención en las recurrencias; la manipulación del lenguaje (MacMartin & Wood, 2007; O’Keeffe & Breen, 2007); de interpretación (Greenlee, 2012); la polisemia y ambigüedad (Ng, 2013); la velocidad de las respuestas (Jenkins & Dando, 2012); comparación de similitudes, de patrones de preferencia desde el lexicón de referencia, enfocando el género, edad, la longitud de los textos, los tiempos de respuestas o los temas de la conversación (Tomblin, 2012); hasta las frecuencias de las distintas funciones, distribuciones o colocaciones de las palabras; el léxico, la puntuación, análisis de contenido, y de niveles de sofisticación sintáctica (Grant & MacLeod, 2016).
Se proyecta así un tema amplio que requiere una delimitación de diversas disciplinas que susciten la elaboración de perfiles lingüísticos orales o escritos. Debido a lo complejo del asunto, este acercamiento se centra en encontrar ejes temáticos en el modus operandi de la lengua escrita online de los posibles agresores que forman una comunidad lingüística.
EL CORPUS Y EL CONTEXTO OPERACIONAL
El corpus corresponde a conversaciones escritas que, en este caso, se encuentran en el ciberespacio, mediadas por un mecanismo tecnológico, por lo que no existe muestra de vocalizaciones, tonos ni acentos; sin embargo, posee otros aspectos externos a la lengua como emojis, stickers y gifts, pertenecientes a la plataforma cibernética, que de igual manera matizan los sentidos en la comunicación.
Se entiende que no se trata de una comunicación real (se refiere a que no existe contacto directo, por lo que ciertos componentes pueden ser ocultos o fingidos como la edad, el carácter e incluso el género), sino de una vía online -mayormente- textual; esto brinda la oportunidad de apuntar al desarrollo y automatización de técnicas y métodos para la detección de una conducta particular (Grant & MacLeod, 2012; Jenkins & Dando, 2012; Egbert et al., 2022; MacLeod & Wright, 2020).
Las estudiantes de Criminología que trabajaron en el proyecto: “Creación de una metodología para el análisis forense, utilizando el texto digital”, colaboraron en el laboratorio de análisis forense, realizando la recolección del corpus durante un periodo de seis meses. Los aspectos metodológicos y teóricos específicos corresponden a una investigación puntual (Colmenares-Guillén et al., 2020) constituida por cinco conversaciones en español obtenidas del perfil de una red social Facebook, elaborado a partir de la identidad fingida de una niña aproximadamente de 14 años de edad.
Para la obtención del corpus se realizó previamente una revisión teórica documental desde la perspectiva socio/jurídica y criminológica. Sin embargo, también requirió un estudio experimental auxiliar con bases de la ciencia computacional y de la lingüística, con el objetivo de comprender la diferencia de los soportes empleados para la comunicación y sus matices que caracterizan la obtención de los datos.
Debido a que son conversaciones online, se debe precisar: 1. Las características del corpus y 2. Los roles de los usuarios: aquel que recabó información y quien la proporcionó.
Las investigadoras son acreedoras de una identidad falsa con objetivos de investigación (Criminal Justice Impectorates, 2014); por ello, el rol que personifican requiere preparación, tales como, nociones de identidades criminales y de identidades vulnerables, entre otros aspectos.
Sin embargo, referimos a esta identidad de infante fingido/identidad fingida (Bauman, 2000), desde la idea de un perfil falso construido en una red social virtual para la específica adquisición del corpus -suponiendo la caracterización de una niña- que ayudó a recabar la presente información a partir de su constitución artificial o fingida.
Se aclara que este modelo surge bajo una noción de mecanismo formal computacional que responde a posibilidades, probabilidades, convenciones y estrategias lingüísticas desde tendencias léxicas (Kaplan, 2004).
Por otro lado, la justificación para considerar a los usuarios -de quienes se extrajo la información- como posibles agresores sexuales se basa en:
Las peticiones de fotografías a la menor de edad, lo cual corresponde a una conducta delictiva (Artículo 202, 2018) en México y,
El acuerdo al que llegaban los usuarios respecto a las actividades sexuales que planeaban llevar a cabo, antes de solicitar la cita presencial.
Ahora, para los datos lingüísticos obtenidos y la cuantificación de frecuencias de las clases gramaticales -se recuperan los nominales, verbos y adjetivos que dirigen el primer acercamiento a los turnos de habla-, se retomó la metodología -empírica, basada en datos que explotan muestras de lenguaje natural- de la lingüística de corpus de Rayson (2015), que a su vez adapta la de Rayson (2008):
Pregunta: idear una pregunta de investigación.
Construcción: diseño y compilación del corpus.
Anotación: análisis manual o automático del corpus.
Recuperación: análisis cuantitativos y cualitativos del corpus.
Interpretación: interpretación manual de resultados.
El corpus presentó irregularidades ortográficas; debido a esto, se hizo un pre-procesamiento que consistió en la extracción de las intervenciones de habla del potencial agresor y de su limpieza -hora, fecha, username, de la corrección ortográfica, la eliminación de recursos externos a la lengua como fueron los emojis, además de las contracciones-. De este modo, fue posible contar y etiquetar las piezas léxicas.
BASES LINGÜÍSTICAS: PIEZAS LÉXICAS, INTERVENCIONES Y AGRUPACIÓN
Se reconoce la intervención de habla como la parte del turno de conversación en que el victimario escribe una línea de texto. Asimismo, se reconoce al turno conversacional o de habla como la unidad básica de la conversación. Desde un punto de vista formal, la conversación se caracteriza precisamente por la alternancia de varios turnos, es decir, por la sucesión de intervenciones a cargo de diferentes interlocutores (Centro Virtual Cervantes, 2008).
A partir de los criterios de turnos e intercambios, este perfil lingüístico tiene como base las intervenciones construidas con piezas léxicas sexuales o sexualizadas que dan pie a una intervención destacada. Aquellas que sean recurrentes, constituyen un módulo comunicativo que se clasificó de manera temática.
Además, se entiende aquí como un módulo temático a una intervención de carácter sexual o sexualizada que tenga una frecuencia y contenga características propias como piezas léxicas que la definan, desde la perspectiva de los usos marcados -o no comunes- de ciertas piezas léxicas, también pueden tener significados especiales en una comunidad lingüística propia que permitan realizar análisis acerca de usos y distinciones en contextos específicos (en lingüística forense refieren a las características analizables del lenguaje en contextos específicos como juicios legales; no obstante, los tintes marcados de manipulación y significados múltiples pueden analizarse en diferentes contextos), para la evaluación de un perfil lingüístico.
RESULTADOS Y DISCUSIÓN
Para la creación del perfil lingüístico, se identificaron y extrajeron las intervenciones del posible agresor, distinguiéndolas de la infanta fingida. A partir de estas se precisaron las piezas léxicas: nominales, verbos y adjetivos sexuales o sexualizados. Después se analizó la estructura sintáctica general de las intervenciones para agruparlas en módulos temáticos que se ordenaron al distinguir su frecuencia y con base en ella, se organizó un patrón lingüístico (May-Chahal et al., 2014) de intervenciones, del cual resulta un primer piloto experimental, empírico y descriptivo. El análisis constó de cinco pasos:
1. Pregunta o planteamiento: se refiere a la construcción de un perfil lingüístico de potenciales agresores sexuales de infantes en línea.
2. Construcción: consta de cinco conversaciones desde el perfil ficticio de una menor de edad.
3. Anotación: apunta al análisis manual del corpus. La contabilización de las piezas léxicas, comprendidas como palabras de cualquier categoría gramatical, presentó el siguiente número de intervenciones y de piezas léxicas como se muestra en la Tabla 1.

4. Recuperación. Análisis cuantitativos y cualitativos del corpus: léxico, clases de palabras; en este apartado se muestran los resultados de las tres clases de palabras seleccionadas -nominales, verbos y adjetivos- y su frecuencia en el corpus. En las Tablas 2, 3 y 4 de frecuencia léxica los números arábigos remiten al número de veces que las piezas aparecieron en las conversaciones.
NOMINALES
Los nominales más frecuentes en las intervenciones que se identificaron con significado contextual distintivo se muestran en la Tabla 2.

La tabla muestra que el nominal con mayor constancia en las conversaciones fue bebé (conversaciones II-III-IV-V).
VERBOS
Los verbos se muestran en infinitivo, considerando dentro de ellos las diferentes conjugaciones que tuvieron en las conversaciones. Es importante señalar que, aislados como aparecerán pueden no evidenciar las cargas sexuales; esto se debe a que algunos actúan como cópulas verbales. Por lo que resulta provechoso estudiar los casos de los modificadores, pues crean los contextos y demuestran las cargas semánticas que guían la conversación y su tema.
No obstante, en este acercamiento han sido identificados y se evalúa su importancia. Los verbos más frecuentes en las intervenciones que se identificaron con connotaciones con significado contextual distintivo se muestran en la Tabla 3:
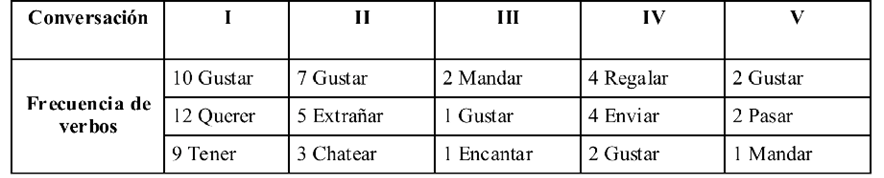
Un aspecto a resaltar es la utilización de tres elecciones léxicas verbales -verbos directivos o de petición- para solicitar una fotografía: mandar, enviar, regalar; lo que apunta a la evidencia de la variación léxica en las peticiones. Asimismo, el verbo con mayor constancia en las conversaciones fue gustar (presente en todas), un verbo psicológico o de estado mental.
ADJETIVOS
Los adjetivos más frecuentes en las intervenciones que se identificaron con connotaciones con significado contextual distintivo se muestran en la Tabla 4.
Los adjetivos que tienen solo un número de aparición se muestran en el orden en que se presentaron en la conversación, o debido a que dentro de la misma se encuentra la raíz de la palabra con modificadores. El adjetivo con mayor constancia en las conversaciones fue hermosa (conversaciones I-II-IV-V).

5. Interpretación de los módulos: Se identificaron 17 módulos temáticos por medio de su función comunicativa, en la Tabla 5 se enumeran y muestran ejemplos para comprender mejor la referencia de la categorización.
El número romano de la columna ejemplo da la referencia al número de la conversación; mientras que los números arábigos de la misma columna aluden al número de turno enlazado al corpus del que se extrajeron y conciernen a la organización específica del análisis generado a partir de la clasificación de turnos.
De este modo, de acuerdo con el patrón de intervenciones, el resultado más representativo consistió en la frecuencia de las primeras siete intervenciones de las conversaciones, con respecto a la reiteración de los módulos:
En la primera intervención existe la regularidad del módulo I. Saludo adjetivado.
En la segunda intervención es constante una petición de información (conversación I-IV-V), específicamente de la localización de la infanta.
En la tercera intervención, como petición de información, se localizan preguntas acerca de la edad (conversación III-V) o el reconocimiento de la brecha de edades (conversación III).
La cuarta intervención presenta dos módulos temáticos en el mismo porcentaje: el reconocimiento de la brecha de edad (conversación I-V) y halagos físicos de la infanta (conversación III-IV).
En la quinta intervención hay mayor aparición del módulo de petición de información, específicamente de fotografías (conversación III-IV-V).
En la sexta intervención se presentan dos módulos temáticos: 1. petición de información (conversación I-II-IV) donde se solicita vestimenta, si tiene alguna pareja, vida cotidiana, y 2. halagos físicos (conversación III-V).
En la séptima intervención también hay mayor aparición del módulo temático de petición de información (conversación I-II-III-V): insistencia de información, compañía, vida cotidiana y fotografías.
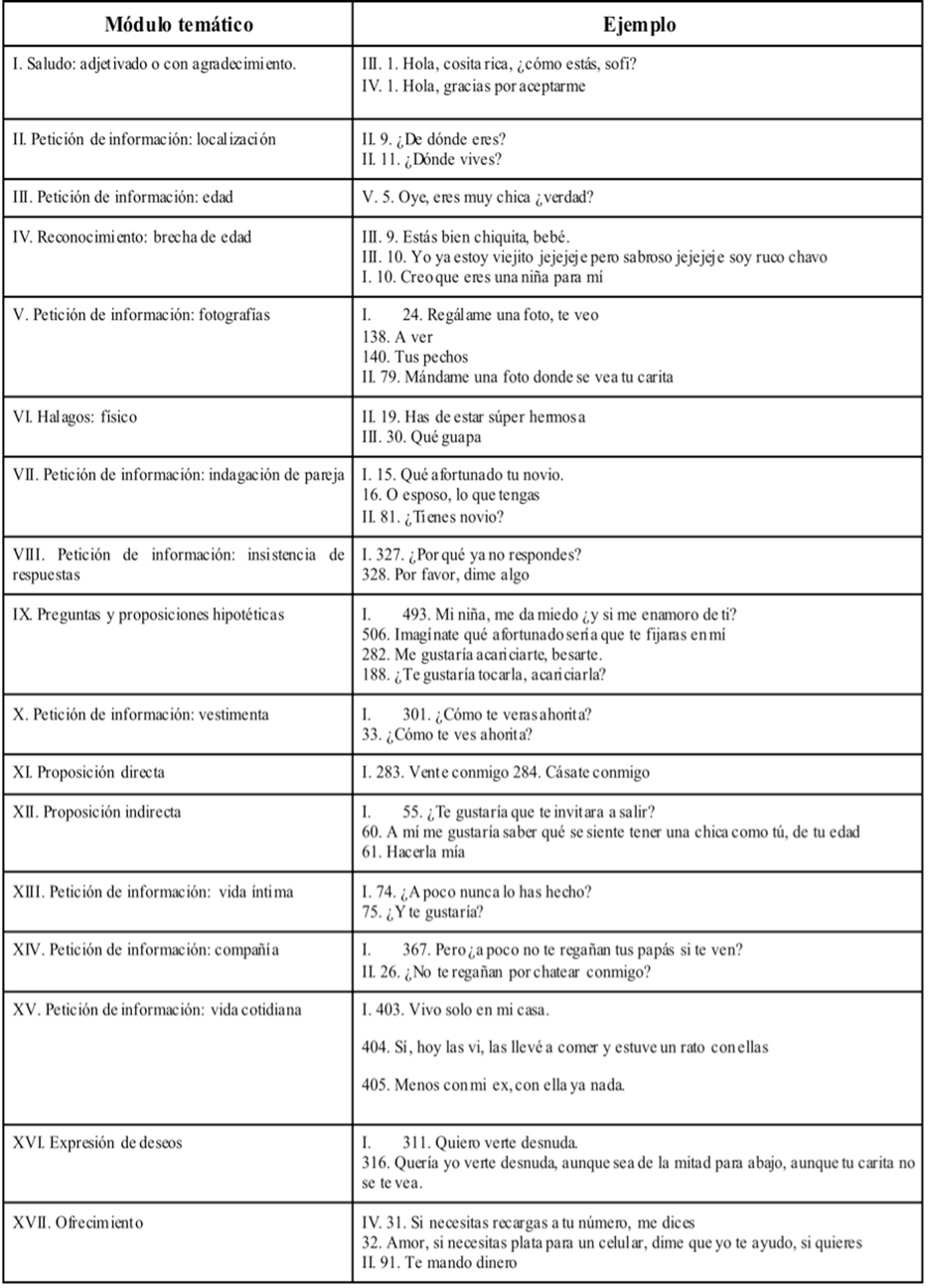
El orden de las intervenciones agrupadas en módulos temáticos se presenta en la siguiente Tabla 6.
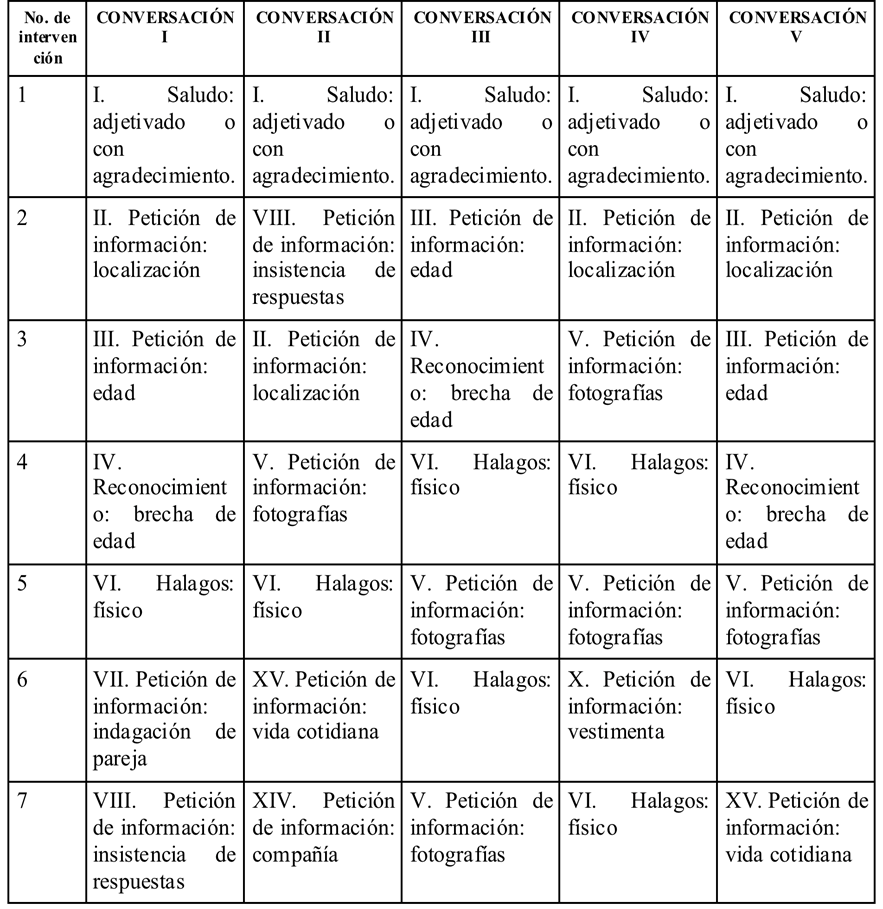
Con base en ello, el resultado del patrón de intervenciones por módulos temáticos es el siguiente modus operandi: I. Saludo: adjetivado o con agradecimiento; II. Petición de información: localización; III. Petición de información: edad; IV. Halagos: físico; V. Petición de información: fotografías; VI y VII también petición de información: indagación de pareja, vestimenta, insistencia de respuestas y vida cotidiana.
CONCLUSIONES
El presente artículo generó un acercamiento a un perfil lingüístico de posibles agresores online como comunidad lingüística, mediante la creación de un corpus en español resultado de los módulos temáticos por su intención comunicativa en las cinco conversaciones analizadas. Este perfil lingüístico precisa información léxica en tres categorías gramaticales extraídas de las intervenciones textuales online entre una infante ficticia/fingida y un agresor sexual. Lo anterior permitió observar un patrón en las piezas léxicas, dirigiendo a un armado de módulos temáticos, lo que posibilita identificar posibles agresores sexuales en otros escenarios reales.
Asimismo, de acuerdo con el reconocimiento de los módulos con cargas sexuales se identificó una frecuencia de las piezas léxicas que genera un habla específica de los victimarios hacia las víctimas: el nominal más frecuente fue bebé, el verbo con mayor aparición fue gustar y la recurrente aparición del adjetivo hermosa.
Ahora bien, en cuanto a los módulos temáticos, se identificó que el modus operandi se genera por una secuencia de intervenciones en un orden particular: un saludo específico, dos peticiones de información, la primera de localización y una posterior de edad; de manera consecutiva se presentan halagos físicos, que a su vez anteceden a la petición de fotografías.
Con ello, se logra construir un perfil frecuente en la dinámica de comunicación -se reconoce una conducta lingüística- de agresores sexuales con sus posibles víctimas. En vista de lo abordado, se permite una posible intervención por medio de aspectos lingüísticos y alienta a considerar nuevas formas preventivas y de acción que versen propiamente en ellos.
Los hallazgos laterales al propósito regente del estudio, pero innegablemente evidentes, parten del notable cambio de la interacción, de acuerdo al uso de los tiempos verbales -el destacable uso del subjuntivo y las estructuras copulativas, que a su vez abordan la semántica de las piezas léxicas en contexto y sus interacciones-.
Finalmente, a nivel sintáctico, existe la posibilidad de que las palabras se sexualicen dentro del contexto de contacto léxico; su recurrencia en el corpus denota aspectos sintácticos marcados en el modus operandi, y esto abre la posibilidad a futuras investigaciones en otros niveles de la lengua que sumen al trabajo de la lingüística aplicada, a fin de consolidar herramientas que sean de utilidad para la sociedad

