











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Son muy numerosas las experiencias en las que los Sistemas de Información Geográfica (SIG)1 han sido usados por los gobiernos, investigadores y por las empresas como herramienta de decisión en las que alcanza cierta repercusión e influencia la dimensión espacial (Jarupathirun & Zahedi, 2005, p. 151). Los SIG se desarrollaron originalmente a fina les de la década de 1960, incorporados en ese momento en muy pocos departamentos de urbanismo por el elevado coste, siendo en los años ochenta cuando se experimentó un incremento notable en su implantación, tanto en Europa como en EE.UU. (Yeh, 2005). Será a partir de 1990 hasta nuestros días, cuando desarrolle su mayor apogeo y uso por gran número de urbanistas como sistema capaz de integrar datos de diversas fuentes para proporcionar información necesaria para la toma de decisiones en la planificación urbana (Yeh, 2005). Algunos de estos sistemas con los que se integran los SIG son los que se han venido a llamar Sistemas de Ayuda a la Decisión,2 especialmente en aquellos entornos en los que el análisis de las implicaciones espaciales o territoriales es singularmente relevante. Estos sistemas emergen en el ámbito del Urbanismo en la década de 1990, cuando las metodologías de la planificación pasan de dar por hecho el que el urbanista debe realizar los diseños y los planes para la gente, a una situación en las que ambos - ciudadanos y urbanistas-se convierten en actores importantes de la planificación (Ayedi, 1998).
Los Sistemas de Ayuda a la Decisión son instrumentos o “vehículos” que se han verificado eficaces para la incorporación e integración de realidades y problemas complejos así como para el apoyo de determinadas decisiones; se estima, tradicionalmente, crucial una perfecta definición de lo que se desarrolla y el porqué del mismo (Keen, 1987), evitándose en lo posible la improvisación, la indeterminación y sin prestar especial consideración a la flexibilidad y resiliencia del propio sistema.
Sin embargo la realidad informática en la que se apoyan estos sistemas está cambiando muy rápidamente en los últimos años, con una proliferación de datos e información n espacial de acceso libre, intensificándose la idea de campo de investigación propio en torno a los SIG. Este campo ha sido nombrado como GISciencia 3 (Goodchild, 2010), asumiendo un papel principal dentro de las Ciencias Sociales para el análisis y comprensión de la información a distintas escalas, pero con una naturaleza eminentemente espacial (Juanes Notario, 2014). Este campo de investigación se apoya en la idea de una nueva Geografía Cuantitativa (Buzai, 2007) de orden básicamente espacial y tendente hacia la gestión y planificación territorial, enfocada en mejorar la calidad de vida de la población.
Según Gustavo D. Buzai (2015), los SIG han pasado del énfasis en la S (Sig) por los problemas computacionales (décadas 1960-1970), pasando a dedicarse a la I (sIg) por el interés en la información (décadas 1980-1990), para finalmente a partir de 2000 enfocarse en la G
(siG), por una necesidad de interpretación geográfica, materializándose la sociedad de la información geográfica” y abriéndose una nueva etapa para la historia de la Geografía (Buzai, 2015). En este contexto los Sistemas de Ayuda a la Decisión se sitúan en el límite de la nueva Geografía Cuantitativa con la Geografía Humana, en cuanto que opera en el campo de las preguntas de la realidad y próximo al campo de las políticas, de sus lenguajes y de sus decisiones.
En este contexto de la nueva Geografía Cuantitativa, la granularidad de los datos geográficos4 se está elevando al extremo, llegando a una auténtica “n-dimensionalidad” de los datos (André Skupin & Agarwal, 2008)
De este modo Pragya Agarwal y André Skupin han remarcado que el análisis estadístico tradicional se está enfocando en las problemáticas de la autocorrelación espacial, quedando otros múltiples ámbitos totalmente por explorar. Algunos de esos espacios están siendo abordados por enfoques emergentes como son la Inteligencia Artificial o las redes neuronales artificiales, el prendizaje automático (Machine Learning) o de forma specífica por la Geo-computación.
Estas nuevas técnicas y enfoques están propiciando un cambio de paradigma en los Sistemas de Ayuda a la Decisión, considerándose que en la actualidad pueden ser útiles para la comprensión de la realidad, detección de sus problemas y, en definitiva, la formulación de nuevas hipótesis y no solo como instrumento para verificar aquellas previamente establecidas.
Como objetivo principal la investigación se propone evaluar la viabilidad y el interés de la construcción de modelos que usualmente conllevarían un alto coste aparejado, usando en su lugar información menos costosa, interpretándose mediante técnicas de Inteligencia Artificial y Machine Learning apoyados en información SIG. De forma específica para su validación se aplicará en la caracterización poblacional de la región española de Andalucía a partir de información residencial en la que reside la misma.
Para alcanzar tal objetivo la investigación se enmarca en los paradigmas de los Sistemas de Ayuda a la Decisión orientados al conocimiento y orientados a los modelos5 (Power, Sharda, & Burstein, 2015). El primer paradigma se enfoca en la construcción de un sistema de descubrimiento de conocimiento basado en bases de datos institucionales sobre las cualidades demográficas y sociales de Andalucía (Fase de modelado 1 de la metodología); y, en el segundo paradigma, (Fase de modelado 2 de la metodología) se enfatiza el acceso, la manipulación y creación de un modelo cuantitativo de la realidad social orientado a proporcionar apoyo a la decisión, elaborado a partir de la realidad residencial de los territorios en estudio. Tal y como describe (Power et al., 2015) los Sistemas de Ayuda a la Decisión usan datos y parámetros proporcionados por los agentes de decisión para ayudarles a analizar una situación, aunque no tienen por qué ser datos masivos.
En nuestro caso el modelo sí se construye con datos masivos (tanto demográficos como residenciales), pero puede ser usado para la toma de decisiones con una información muy limitada, incluso escasa.
La investigación, tal y como se ha avanzado, consiste en la construcción de dos modelos para el cual se deben seguir dos fases metodológicas fundamentales:
La Fase de modelado 1 consiste en la construcción de un Sistema de Descubrimiento de Conocimiento a partir de Información y Bases de Datos.6 En origen estos sistemas no se pensaron como una disciplina autónoma, sino más bien como un método de inteligencia para decisiones a nivel productivo y medioambiental (Longbing Cao, 2009), para pasar recientemente a conformarse como ciencia con identidad propia (Data Science).
Esta fase de Conocimiento basado en Datos, se materializa en la investigación mediante técnicas de lo que se vienen a conocer como Mapas Auto-organizados,7 en adelante SOM. Fueron propuestos inicialmente por Teuvo Kohonen (Kohonen, 1990, 1998; Ritter & Kohonen, 1989). La metodología SOM es una técnica de descubrimiento de conocimiento o de minería de datos consistente en una red neuronal artificial.8 Procede del campo de conocimiento de la Inteligencia Artificial, habiéndose mostrado muy eficaz y robusta en numerosas disciplinas, presentando diversas capacidades entre las que podemos destacar inicialmente dos: (i) es capaz de mostrar y visualizar la información de partida de forma clara y ordenada; (ii) permite clasificar y, por tanto, etiquetar los sujetos en estudio en clases que no requieren su definición, caracterización o etiquetado nominativo previo (aprendizaje no supervisado).
Frente a otras metodologías de descubrimiento de patrones, como por ejemplo el análisis clúster, la metodología SOM, tiene la ventaja de (i) permitir visualizar un gran conjunto de datos estadísticos (Kaski & Kohonen, 1996), (ii) mostrar las relaciones topológicas de similitud o de diferencia entre los sujetos en estudio, (iii) ser interpretables gráficamente y (iv) constituir por sí mismo un sistema de conocimiento de ayuda a la decisión para el análisis y visualización de indicadores estadísticos (Kaski & Kohonen, 1996).
Como resultado de esta Fase de modelado 1 obtenemos por un lado el etiquetado a modo de clases o perfiles de los diferentes fragmentos de territorio andaluz estudiado, atendiendo al análisis multi-variable de los atributos demográficos y sociales estudiados. Por otro lado, obtenemos un sistema de análisis e interpretación de las clases obtenidas, facilitado por la metodología SOM y materializado en cartografías temáticas de los diferentes atributos incluidos en la red neuronal y en diferentes tablas y datos estadísticos que permiten conocer las características diferenciadoras de cada perfil.
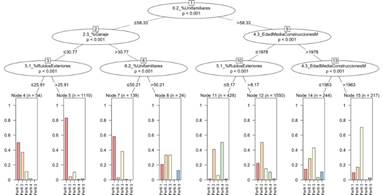
La Fase de modelado 2 trata de materializar, mediante un proceso de Machine Learning, una serie de reglas que permitan predecir las clases o perfiles que se determinaron en la Fase de modelado 1 a partir de atributos sobre la realidad residencial de los territorios en estudio. Estas variables residenciales no se tuvieron en consideración en la creación y constitución de la red neuronal SOM ni, en consecuencia, pudieron afectar o correlacionarse en la definición de los perfiles obtenidos por aquella. Se realiza una aproximación al problema de aprendizaje mediante el paradigma “divide y vencerás” que, al realizarse sobre un conjunto de instancias independientes, conduce naturalmente a un estilo de representación llamado “árbol de decisión” (Witten, Frank, & Hall, 2011, p. 64). En cada nodo del árbol interviene un atributo en particular, comparándose normalmente cada instancia del atributo con el valor de una constante, generándose normalmente dos ramas atendiendo a las instancias que cumplen o no tal regla. El árbol supone una representación asequible para interpretar y usar en la predicción de la realidad demográfica y social de un territorio y, en consecuencia, útil para la toma de decisiones sobre el mismo; usa para ello, una información limitada y generalmente de fácil y económica obtención sobre la realidad residencial del lugar en estudio.
Asimismo al evaluar el “valor” de los perfiles alcanzados en la Fase 1, en su caracterización espacial mediante SIG, se verifica la utilidad de la metodología propuesta.
2. Estado del arte
En este apartado se describirán las principales experiencias y referentes que conforman el estado del arte de los dos ámbitos de conocimiento vinculados con la propuesta metodológica realizada, enfocándose especialmente en las disciplinas vinculadas al urbanismo, la planificación urbana y territorial, así como a la geografía humana y urbana: (i) experiencias de descubrimiento de conocimiento mediante aprendizaje no supervisado con Mapas Auto-organizados y (ii) experiencias de construcción mediante aprendizaje supervisado con árboles de decisión, subrayando singularmente aquellas que se combinan con los resultados obtenidos a partir de metodologías SOM.
2.1 Descubrimiento de conocimiento y clasificación mediante aprendizaje no supervisado. Los Mapas Auto-organizados (SOM)
Las Redes Neuronales Artificiales -a las que pertenecen los Mapas Auto-organizados- son un campo clásicamente integrado en la Neurociencia o Ciencias de la Inteligencia Artificial. Son una categoría de los métodos del Machine Learning que han sido ampliamente usados recientemente en problemas de predicción, clasificación y reconocimiento de patrones (Kauko, 2005). Como principales aplicaciones prácticas de las Redes Neuronales destacan (Kohonen, 1995, p. 219): i) la monitorización y control de la instrumentación industrial, ii) aplicaciones médicas como el diagnóstico, prótesis y modelado y iii) la distribución de recursos de redes de telecomunicaciones.
Nosotros usaremos las Redes Neuronales tipo SOM que permiten a partir de información desordenada, analizar y crear perfiles, proporcionando patrones visuales y formando un paisaje del fenómeno descrito por los datos (Kohonen, 1995). Si bien el algoritmo SOM se creó inicialmente para la visualización de relaciones no lineares de datos multidimensionales, rápidamente se evidenciaron útiles para la visualización de relaciones abstractas, como por ejemplo roles contextuales (Kohonen, 1995, p. 219). Los SOM se mostrarían extremadamente útiles en múltiples campos del conocimiento y las ciencias aplicadas. Según el autor de los SOM, Teuvo Kohonen (1982), como aplicaciones de carácter general se pueden destacar multitud de aplicaciones (Kohonen, 1995).9
Se puede observar que desde el origen de los SOM en 1982 hasta el año 1995, son prácticamente inexistentes las experiencias con la metodología SOM en campos como las Ciencias Sociales, Geografía, Urbanismo y Ordenación del Territorio y, en general, cualquier investigación que precisara SIG, a pesar de que como se describió en la Introducción tales sistemas de información iniciaran su andadura varias décadas antes. Será necesario que el propio Kohonen demuestre las capacidades de los SOM en el campo de la Geografía Humana (Kaski & Kohonen, 1996), para que estas disciplinas se aproximen, lentamente, a esta metodología. En este trabajo seminal, Samuel Kaski y Teuvo Kohonen utilizan el método SOM para representar un conjunto de datos complejos sobre la distribución de la riqueza y la pobreza en el mundo, de una manera en la que pueden ser mostradas y analizadas las similitudes y diferencias entre los diversos países. Será a partir de este trabajo y especialmente en los últimos 10-15 años cuando se experimenta cierta eclosión en el uso de la metodología SOM, todavía muy distante del sobresaliente uso en otros ámbitos.
A continuación se observarán investigaciones con los SOM vinculadas a las disciplinas próximas al SIG como pueden ser la Urbanística, la Geografía, las Ciencias Sociales, etc., anotando si se enfocan en algunas de los principales campos de experiencia y capacidad de los SOM a la hora de manejar la información. Esto es la
Representación, la Clasificación, la Caracterización y la Toma de decisiones:
En el campo de la interpretación de imágenes vinculadas a la geografía o SIG podemos destacar ciertos trabajos con foco en la clasificación, como por ejemplo el uso del SOM para el análisis y clasificación de imágenes de satélite multiespectrales (con más de 200 bandas diferentes) de la superficie de la Tierra y de otros planetas (Villmann, Merényi, & Hammer, 2003), o la aplicación del SOM para la clasificación de suelos y minerales usando imágenes de radio espectral y SIG, permitiendo transformar las cartografías de un volcán (Tayebi, Hashemi Tangestani, & Vincent, 2014).
En el campo del análisis de la movilidad destaca una investigación en la que se usó el SOM para el análisis de interacciones espaciales, singularmente enfocada hacia la comprensión gráfica y obtención de patrones en las estructuras de transporte aéreo de EE.UU. (Yan & Thill, 2009).
Por otro lado podemos destacar en el campo de la gestión de catástrofes el uso del SOM como herramienta para clasificar y reconocer patrones en bases de datos sobre epidemiología vinculadas con información espacial para ser representada en un sistema SIG (Zhang, Shi, & Zhang, 2009), o para la toma de decisiones rápida mediante SIG y SOM a partir de la extracción de información precisa de los deslizamientos tras un terremoto (Lin, 2008).
En el campo del estudio del medioambiente, de la salud y de la calidad de vida podemos encontrar trabajos enfocados en la representación mediante SOM de la distribución del riesgo ecológico por contaminación (Faggiano, de Zwart, García-Berthou, Lek, & Gevrey, 2010); trabajos orientados hacia la clasificación: uso del SOM para la localización de patrones de contaminación por pesticidas en la cuenca del río Asour-Garonne en Francia (Faggiano et al., 2010), para determinar el modelo de localización de plantas para el tratamiento de residuos de la madera (Gomes, Ribeiro, & Lobo, 2007); podemos asimismo observar el uso del SOM y del SIG para la clasificación de la salud comunitaria a partir de variables de las condiciones ambientales (Basara & Yuan, 2008), o la creación de un modelo que evalúa el nivel de calidad ambiental de los suelos, caracterizándolos a partir de concentraciones de elementos mediante SOM y visualizándolo con SIG (C. Yang, Guo, Wu, Zhou, & Yue, 2014). Finalmente podemos encontrar un trabajo enfocado en la toma de decisiones mediante el análisis empírico multidimensional y espacio-temporal de las tendencias de la calidad de vida de los barrios de Charlotte (EE.UU.) mediante la representación gráfica de los SOM (Delmelle, Thill, Furuseth, & Ludden, 2012).
Con vinculación al ámbito de los estudios demográficos, Ciencias Sociales y Geografía describirá Takatsuka (2001, p. 24) que “El Self-Organizing Map es uno de las más modernas herramientas que los investigadores han encontrado útiles en el análisis de bases de datos multivariables tales como los datos atmosféricos y demográficos”. En estos ámbitos del conocimiento, con una vertiente más social y demográfica destacan ciertas investigaciones con un uso del SOM enfocado en la representación de datos, como por ejemplo la visualización conjuntamente con SIG de los cambios demográficos de los condados de Texas (EE.UU.) a lo largo del tiempo mediante SOM (Andre Skupin & Hagelman, 2005) de patrones espacio-temporales de variables geográficas de EE.UU (Guo, Chen, MacEachren, & Liao, 2006), o el uso del SOM para la realización de una representación holística alternativa y complementaria a la representación espacial propia de los SIG, en la que se da simultanea información de 69 atributos censales de EEUU, con información sobre el clima, topografía, suelo, geología, usos de suelo y población (André Skupin & Esperbé, 2011). Con un enfoque hacia el SOM como clasificador podemos encontrar el uso simultaneado con SIG de una variante de los SOM (fuzzy) para creación de regiones demográficas homogéneas a partir de datos del censo del municipio de Atenas (Hatzichristos, 2004), el uso de SOM para caracterizar barrios mediante el etiquetado de secciones censales de Nueva York a partir de 79 atributos geo-demográficos (Spielman & Thill, 2008), o el uso de los SOM como una metodología para el Data-mining urbano en la que se realiza una clasificación no supervisada de datos geoespaciales de comunidades alemanas en cuanto a población, migración, impuestos, residencia, empleo y transporte (Behnisch & Ultsch, 2009).
Por último en el campo más próximo a la investigación que se propone, se pueden encontrar ciertos ejemplos relevantes del uso directo de las metodologías SOM en el ámbito del Urbanismo, la Planificación y Ordenación del Territorio, como por ejemplo: Investigaciones enfocadas en las capacidades de obtener conocimiento mediante la representación de las dinámicas temporales de la ciudad de Harrisburg en EE.UU. (Takatsuka, 2001), o la representación semántica y caracterización de barrios ejemplares de la historia reciente del urbanismo (AUTOR 1 & Osuna Pérez, 2013).
En el marco urbanístico han sido frecuentes los análisis multicriterio a modo de análisis multicapa (Feng & Xu, 1999) con capacidad para la clasificación. Utilizando SOM encontraremos asimismo algunos ejemplos como la identificación y caracterización de urban sprawl de Milán (Diappi, Bolchim, & Buscema, 2004), el análisis mediante SOM del mercado residencial a partir de variables de precios, cualidades y características de las viviendas, densidad, habitantes, etc., de Finlandia, Hungría y de Países Bajos como método inductivo de descubrimiento de similitudes y diferencias entre ellos (Kauko, 2005). También podemos destacar la utilización del SOM como clasificador para la detección de edificios mediante tecnología lídar e imágenes multiespectrales y atributos auxiliares (Salah, Trinder, & Shaker, 2009), la clasificación de los tejidos urbanos a partir de indicadores morfológicos relacionadas con la huella de las edificaciones (Hamaina, Leduc, & Moreau, 2012), o la clasificación taxonométrica de las inmigraciones turísticas de los tejidos urbanos de Andalucía a partir de las cualidades de sus asentamientos AUTOR 1, AUTOR 2, & Osuna-Perez, 2015). Finalmente podemos destacar un enfoque hacia la capacidad de los SOM para facilitar la toma de decisiones en diversos trabajos, como por ejemplo en la integración del SIG y de las técnicas SOM, nombrada específicamente SOFM (Self-organizing Feature Maps) para la creación de un modelo difuso para la clasificación de suelos en la provincia China de Zhejiang, con la intención de ser aplicado como parte de un análisis de apoyo a la decisión (H. Yang, Hu, qi Deng, Tian, & Li, 2004), en la caracterización de tejidos urbanos del centro histórico de Santa Fe (España), para la creación de una ordenanza urbanística (AUTOR 1 & Fernandez-Avidad, 2010), o en la combinación de metodologías de aprendizaje supervisado y no supervisado tipo SOM orientado a la investigación del mercado nocturno callejero de Taiwan, usando para ello información espacial SIG (Wu & Hsiao, 2015).
2.2 Construcción de modelos predictivos mediante aprendizaje supervisado. Árboles de decisión
Los árboles de decisión son técnicas y métodos de aprendizaje de modelos comprensibles y proposicionales, entendiendo que son (i) modelos en cuanto que construyen una hipótesis o representación de la regularidad de los datos; (ii) comprensibles por expresar de manera simbólica, en forma de un conjunto de condiciones; y, (iii) proposicionales al establecerse en su construcción reglas “atributo-valor” en las que las condiciones se expresan sobre el valor de un único atributo (Hernandez Orallo, Ramí rez Quintana, & Ferri ́ Ramirez, 2004, p. 281)́ .
Son muy numerosas las variantes de algoritmos de árboles de decisión. Destacaremos únicamente algunos de ellos. Como antecedentes históricos de los árboles de decisión más usados en la actualidad podemos encontrar los algoritmos CHAID,10 CART,11 ID3 o C4.5.12 Entre los algoritmos que generan árboles de decisión destacaremos por último los métodos de particionado recursivo que se han vuelto en los últimos años muy populares y ampliamente usados para la regresión no paramétrica y para la clasificación en muchos campos científicos (Strobl, Malley, & Tutz, 2010).
A continuación se muestran algunos de los escasos ejemplos de investigaciones que implementan el mismo concepto metodológico que se usa en este artículo: Implementación de un modelo híbrido: sobre el SOM se aplica un árbol de decisión; es decir, el árbol de decisión utiliza la clasificación proporcionada por el SOM como información a predecir.
Como ejemplos de este enfoque de modelo híbrido o dual en los que se combinan técnicas no supervisadas (SOM) y minería de datos supervisada (árboles de decisión) podemos encontrar, algunos trabajos metodológicos como Astudillo & John Oommen (2011); Astudillo & Oommen (2013) o relacionados con la Biología y la Medicina, como por ejemplo un estudio para la reducción del coste del diagnóstico de tiroides (Kinaci & Yucebas, 2015), el análisis de componentes principales para la identificación de bacterias (Simmuteit, Schleif, Villmann, & Kostrzewa, 2009), o un trabajo de minería en datos biológicos (Z. R. Yang & Chou, 2003). En el campo de la Ingeniería podemos encontrar el análisis de la carga eléctrica dinámica (Voumvoulakis, Gavoyiannis, & Hatziargyriou, 2006), o la selección de variables para agrupar muestras de viario (Gómez-Carracedo et al., 2010). Con vinculación a la Economía y empresa hallamos un análisis de la cartera de clientes (Yao, Holmbom, Eklund, & Back, 2010), o el descubrimiento de las preferencias en el comercio de acciones (Tsai, Lin, & Wang, 2009), todos ellos enfocados en este planteamiento de SOM + árboles de decisión. Finalmente con cierta similitud en el enfoque con nuestra investigación podemos encontrar la selección de propiedades en el análisis de datos censales mediante SOM y árboles de decisión (Shanmuganathan & Li, 2016).
3. Materiales y Métodos
3.1. Objetivos de partida
Como objetivo principal de la investigación se propone evaluar la viabilidad y el interés de una alternativa para la construcción de modelos territoriales sobre dimensiones que requieren de datos de alto coste. Para elaborar tal modelo se propone con un menor número de datos, identificar perfiles y conectarlos con información de otras dimensiones que conlleven un menor coste aparejado.
A modo de validación, en nuestro caso concreto, la metodología se va a aplicar para crear un modelo que explique la realidad demográfica de Andalucía, a partir de la realidad residencial, dimensión esta última que está compuesta por datos habitualmente de más fácil acceso y menor coste.
3.2. Metodología de investigación
Para la óptima comprensión y para la obtención de los mejores resultados, se siguen las fases definidas por Mark S. Silver (2008): (i) información y funciones de procesado, (ii) conjuntos de datos, (iii) modelos y (iv) representaciones visuales.
Información y funciones de procesado:
La información utilizada en la investigación procede en su totalidad de la información pública del Censo de Población del año 2001 de Andalucía, obtenidos por el Instituto de Estadística y Cartografía de Andalucía (IECA). Se evitó la utilización de fuentes más actualizadas como es el Censo de 2011, por tratarse éste de datos que en gran medida procede de interpolaciones a partir de una reducida muestra de estudio. En cualquier caso se considera que este periodo a causa de la crisis inmobiliaria, no ha producido grandes transformaciones sobre los datos. Sobre esta información se ha realizado una intensa preparación de datos, consistente fundamentalmente en la integración y limpieza de datos, transformación de atributos mediante la creación de indicadores agregados que tienen la peculiaridad de resumir de forma objetiva y compacta las principales cualidades demográficas de mejor modo que los datos originales. Debido a la robustez de los SOM, no es necesario realizar su tipificación o normalización13 previamente a la agregación e incorporación al modelo.
-Instancias: La unidad de territorio sobre la que se obtienen los datos, es la Sección Censal, alcanzándose la totalidad de las 5381 secciones censales14 de Andalucía, formando parte del estudio la totalidad de la superficie y de población censada en la región andaluza. Por tanto, no se ha realizado ningún muestreo sino que se ha manejado la totalidad de la población en estudio.
-Atributos: Los atributos que se ha usado en la Fase de modelado 1 constan de diversas variables de la dimensión demográfica, social, laboral, de los equipamientos y de los servicios a los que se tienen acceso en cada sección censal (primera columna de la Tabla 1). Los atributos que se han usado en la Fase de modelado 2 están compuestos de variables de la dimensión residencial (primera columna de la Tabla 2). En la Tabla 1 y Tabla 2 se muestran asimismo ciertos datos de la estadística descriptiva de los mismos, como la media y la desviación estándar (columnas 2 y 3 de las Tablas 1 y 2).
Conjuntos de datos:
Se opera inicialmente con dos bases de datos desconectadas: una propia de la Fase de modelado 1, con dimensión principalmente demográfica y otra propia para la Fase de modelado 2, basada en la dimensión residencial. El funcionamiento será fundamentalmente independiente, conectándose únicamente tras el Modelado 1 para evaluar cómo se ajustan los perfiles demográficos obtenidos a los datos residenciales (columnas de perfiles de la Tabla 2. Obsérvese que los perfiles han sido obtenidos únicamente a partir de los atributos de la Tabla 1). Finalmente en la Fase de modelado 2 se integrarán en la construcción del árbol de decisión los perfiles obtenidos en la Fase de modelado 1 con los datos residenciales.
Modelos:
Debemos distinguir entre dos fases de modelado:
Fase de modelado 1: Modelo de clasificación y conocimiento; entre sus objetivos tenemos por un lado, la clasificación y etiquetado de los datos de la dimensión demográfica, social, laboral, de los equipamientos y de los servicios; y, por otro, la generación de conocimiento de la realidad andaluza de tales dimensiones, de los perfiles creados y de los perfiles creados en contraste con la dimensión residencial (que no constituyó parte del modelo creado de clasificación). En esta fase se usará una red neuronal artificial y específicamente un SOM. Esta metodología permite clasificar (propiamente segmentar) sin atribuir a priori una etiqueta con definiciones y significados previamente atribuidos, siendo un modo para reducir la enorme complejidad de los datos (Spielman & Thill, 2008).
El estado del arte demuestra que es muy frecuente el uso de los SOM como metodología de reducción y clasificación (Hamaina et al., 2012) y también para el etiquetado de entidades (Salah et al., 2009). Comparado con otros métodos de reducción de dimensiones como el PCA (análisis de componentes principales) o el MDS (escalado multidimensional), la capacidad de los SOM de preservar la topología de los datos hace que éste tenga un uso más eficiente del espacio disponible en la representación del mapa, con la consecuencia de una mayor distorsión en las distancias relativas (André Skupin & Agarwal, 2008, p. 7). Por otro lado el SOM presenta ventajas muy notables frente a otras técnicas o métodos. Los SOM son relativamente insensibles a los valores perdidos, tolerando a la vez datos con una distribución no normal (Zhang et al., 2009); esto le permite prescindir de verificaciones de difícil cumplimiento, haciéndolo válido para cualquier distribución de datos. Por otro lado como método de clusterización el SOM es más robusto que por ejemplo el K-means, aunque en su contra requiere mayor tiempo de computación (Bação, Lobo, & Painho, 2005; Gomes et al., 2007).
Tabla 1: Variables de dimensión demográfica, social, laboral de los equipamientos y de los servicios. Características estadísticas de la totalidad de los datos y de los Modelo SOM de 5 Perfiles. Se marcan las variables con elevado Tamaño del efecto en la constitución del Perfil
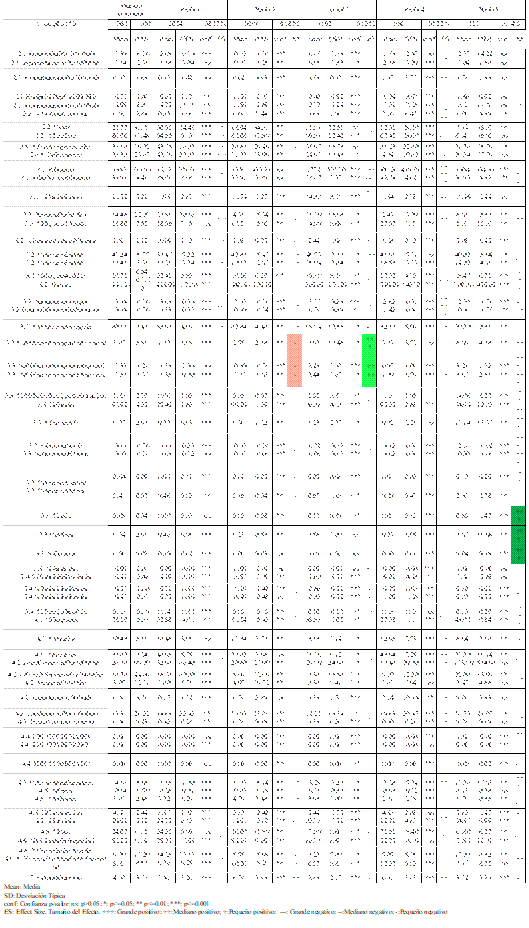
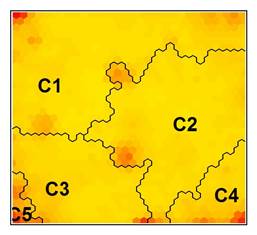
El agrupamiento, clusterización o clasificación de los sujetos se realiza mediante un análisis adicional Wardclúster sobre el mapa (Figuras 1 y 2). Se generan perfiles o prototipos mediante modelado de patrones y tendencias en la información (Weiss & Indurkhya, 1998). La elección del número de perfiles puede ser guiada por diversos métodos o elegida por la capacidad de interpretación que tenga el investigador sobre los mismos.15
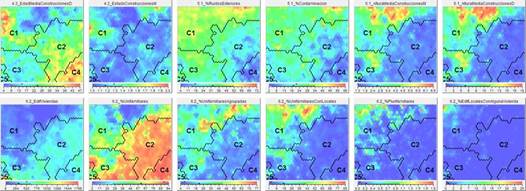
Para facilitar la comprensión de los perfiles obtenidos, se puede caracterizar cada clúster determinado por el análisis SOM con datos estadísticos básicos como son la Media, la Desviación Estándar, el Máximo y el Mínimo (Faggiano et al., 2010), tratando de conseguir principalmente dos resultados adicionales: i) el factor o variable que es más importante para el efecto y ii) el valor de tal factor (Wu & Hsiao, 2015). Para el análisis de los perfiles además de la información estadística que los define, son valiosos los Mapas SOM monovariables (Figuras 3 y 4) porque permiten según la distribución de valores en el mismo, evaluar relaciones y correlaciones entre variables.
Tabla 2: Variables de dimensión residencial. Características estadísticas de la totalidad de los datos y de los Modelo SOM de 5 Perfiles. Se marcan las variables con elevado Tamaño del efecto en la constitución del Perfil
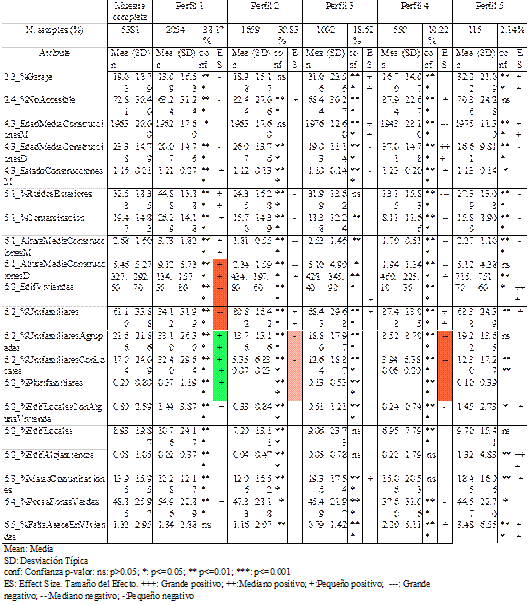

Para cumplir con las recomendaciones de la American Statistical Association (Wasserstein & Lazar, 2016) para cada variable y perfil, además de la significación estadística16 se calcula el tamaño del efecto.17 En las Tablas 1 y 2 se muestran los resultados de la clasificación en 5 perfiles que se describirán en Resultados.
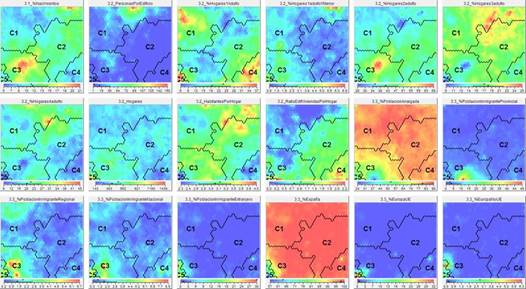
Fuente: Elaboración propia
Figura 3 : Conjunto de Mapas auto-organizados monotemáticos para la clasificación de 5 perfiles; variables demográficas
Fuente: Elaboración propia
Figuras 4: Conjunto de Mapas auto-organizados monotemáticos para la clasificación de 5 perfiles. Variables residenciales
Fase de modelado 2: Modelo de predicción. Como objetivo principal tenemos la construcción de un modelo que permita simultáneamente explicar y predecir la vertiente demográfica, social, laboral y de los equipamientos y servicios que quedó caracterizada y etiquetada en perfiles en la Fase de modelado 1 (variable explicada, dependiente o respuesta), a partir de variables de la dimensión residencial (variables explicativas, independientes o predictoras). En esta fase se usará el modelo árbol de decisión y específicamente el árbol de inferencia condicional.
De este modo una vez etiquetadas las secciones censales mediante el SOM en la Fase de modelado 1, se procede a la construcción del modelo de árbol de decisión que permita la predicción basada en reglas, materializándose mediante la representación de condiciones sucesivas que permitirán identificar, con su grado de probabilidad, a qué categoría o tipología de realidad geo-social de las etiquetadas por el SOM pertenece (perfil), atendiendo a las características residenciales (véanse Figuras 5 y 6); para ello, se han usado los árboles de inferencia condicional.18
iv) Representaciones visuales:
Una de las cualidades que presentan las cartografías SOM es la capacidad de representación de la información resultante de un modo relativamente sencillo de comprender, al mostrar una representación bidimensional de las instancias de partida, con la característica de que cada una de ellas tiene por “vecina” la instancia con cualidades más semejantes. En la misma cartografía se suele representar las agrupaciones de las instancias en los distintos perfiles conformados (Figuras 1 y 2). Esta representación se suele completar con un mapa por cada uno de los atributos o variables que construyeron el mapa SOM (Figuras 3 y 4).

Estos mapas contribuyen a la comprensión de la distribución de los datos en el mapa SOM. Finalmente como las instancias evaluadas tienen su identidad y forma en el espacio, se representarán mediante un SIG la información de los perfiles determinados en la Fase de modelado 1 (Figuras 7, 8 y 9). Esta retorno al SIG de las instancias una vez clasificadas en clases, ha sido frecuente como por ejemplo en investigaciones médicas en análisis no lineales de múltiples variables en ciertas enfermedades (Basara & Yuan, 2008), en la representación de resultados de la clusterización SOM sobre el riesgo ecológico de contaminación (Faggiano et al., 2010) o aplicándolos experimentalmente a datos procedentes de información socio-demográfica oficial del Área Metropolitana de Lisboa (Bação, Lobo, & Painho, 1995).
Fuente: Elaboración propia
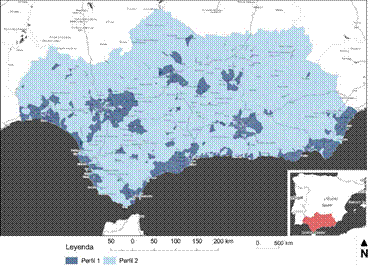
Figura 7: Representación SIG de la clasificación SOM de 2 perfiles para toda Andalucía.
Fuente: Elaboración propia
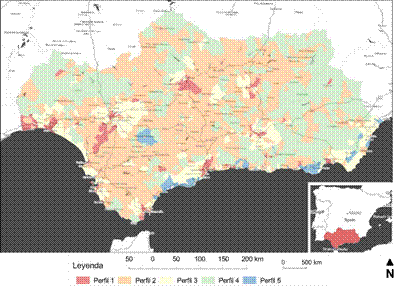
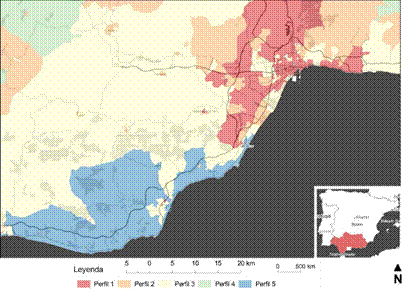
Figuras 8: Representación SIG de la clasificación SOM de 5 perfiles para toda Andalucía Fuente: Elaboración propia
4. Resultados
Según la metodología se realizan las tareas propias de los apartados (i) y (ii), obteniéndose dos bases de datos independientes. Se puede observar una síntesis descriptiva de tales variables de partida en las 3 primeras columnas de la Tabla 1 para los datos principalmente demográficos y de la Tabla 2 para la dimensión residencial. Siguiendo con el apartado (iii) de la metodología, se lleva a cabo la Fase de modelado 1 usando para ello 63 variables de la dimensión demográfica, social, laboral, de los equipamientos y de los servicios, obteniéndose los perfiles que caracterizan la realidad demográfica. A continuación en la Fase de modelado 2 se obtiene el árbol que permite “predecir” a qué perfil (demográfico) corresponde cada sección censal a partir exclusivamente de datos de la dimensión residencial.
A continuación se describirán los resultados obtenidos siguiendo las distintas fases de la metodología, realizándose en primer lugar una evaluación previa con el estudio de la estructura demográfica basada en dos únicos perfiles y a continuación la evaluación definitiva mediante la clasificación en cinco perfiles.
4.1. Resultados y evaluación previa (2 perfiles demográficos)
En un primer análisis SOM se determinan un número de perfiles mínimo -concretamente dos- con la intención de realizar una primera evaluación de los resultados. Al trasladarlas dos categorías demográficas al espacio mediante SIG (Figura 7) se observa que los resultados son básicamente los esperados, se identifican espacialmente claramente las “dos Andalucías”, una nítidamente rural (Perfil 2) y otra con un protagonismo principal de lo urbano (Perfil 1).
A continuación se pudo evaluar el resultado obtenido con el árbol de decisión de la Figura 5, en el que se observa perfectamente qué variables de la dimensión residencial definen las distintas ramas del modelo de perfiles demográficos. Tal y como podríamos prever las variables que principalmente construyen el modelo demográfico son: la proporción de viviendas unifamiliares, la cantidad de viviendas unifamiliares con locales, la cantidad de quejas por ruidos exteriores y la edad media de las construcciones. Se puede observar cómo todas y cada una de estas variables aportan información relevante y definen lo rural frente a lo urbano en el modelo y en la realidad.
4.2. Resultados y evaluación de 5 perfiles demográficos
Si analizamos los 5 perfiles obtenidos del análisis SOM final, comparando por un lado la información estadística que caracteriza a cada uno de ellos (Tabla 1), con la espacialización de los propios perfiles en la región andaluza (Figuras 8 y 9), alcanzamos los siguientes resultados y conclusiones:
-Perfil 1: Estadísticamente se comprueba que las secciones censales contenidas en este perfil presentan, comparados con el resto de perfiles: mayor presencia de delincuencia, mayor número de personas por edificio, mayor dedicación en empleos de servicios y un menor número de viviendas por cada hogar ocupado. Al representar los perfiles espacialmente, mediante SIG, se observa que son coincidentes con las principales áreas urbanas y sus inmediatas conurbaciones a lo largo de toda la región. Tenemos pues un perfil con unas connotaciones urbanas claramente de ciudad consolidada.
-Perfil 2: En el análisis estadístico de este perfil poblacional se observa cierta diversificación laboral, aunque con poca presencia del sector servicios, una población eminentemente española, escasos inmigrantes y un elevado número de analfabetos, no siendo frecuentes los hogares con un único adulto y menores. Espacialmente podríamos decir que este perfil se trata de una población emplazada en un entorno rural, diferenciándose con respecto al otro perfil rural (perfil 4) en que su población es más joven que en aquel, con mayor población activa, con más actividades propias de esa realidad, como por ejemplo mayor dedicación a la construcción o la industria, y con unos hogares con mayor número de habitantes.
-Perfil 3: Estadísticamente destaca por un mayor número de nacimientos, mayor número de inmigrantes de origen provincial y, en menor, regional o nacional que a su vez trabaja en la provincia, con un elevado porcentaje de ocupados laboralmente y menor tasa de paro. Asimismo presenta una edad inferior a la media, con pocos hogares unipersonales y con bajo nivel de arraigo. Espacialmente se localizan como zonas periféricas de las principales ciudades.
-Perfil 4: El análisis estadístico desvela que este perfil poblacional presenta una elevada edad media, gran cantidad de hogares con un único ocupante, abundancia de viviendas vacías y con ciertos problemas como carencia de agua corriente en proporción mayor que el resto. Curiosamente la estadística delata que habitan en asentamientos con buenos ratios de equipamientos culturales y de bienestar por población, probablemente derivado del bajo número de habitantes de tales poblaciones y una aceptable distribución de tales funciones. Espacialmente se observa que corresponden con los emplazamientos rurales más aislados y a mayor distancia de las principales ciudades. Comparando este perfil con el perfil 2, se observa que coincide con una población rural más envejecida que en muchas ocasiones vive sola, en entornos urbanos con poca población, con poca ocupación de las viviendas y con altos índices de analfabetismo, paro e inactividad. Podemos localizar este perfil entre otros ámbitos como en la Hoya de Baza (Granada), en los Campos de Tabernas (Almería), altos de la Sierra de Gádor (Almería) o Sierra de Aracena (Huelva).
-Perfil 5: Destaca por un elevado número de viviendas ocupadas por una persona, en bastantes ocasiones con algún menor a su cargo, alta presencia de inmigrantes procedentes del resto de Andalucía, del resto de España y especialmente extranjeros con el consiguiente bajo arraigo de su población. Presentan una alta tasa de ocupación, bajo paro y baja inactividad, trabajando primordialmente en el sector servicios o en la agricultura. Espacialmente se reconocen y se identifican como áreas urbanizadas bien conocidas por su fuerte y singular presencia de residentes extranjeros, ya sean en enclaves turísticos como Marbella (Málaga), o Almuñécar-Cerro Gordo (Granada) o de fuerte producción agraria intensiva, como la zona de invernaderos del Campo de Dalías (Almería).
A modo de resumen de los perfiles demográficos podemos distinguir la presencia de un perfil eminentemente urbano (perfil 1); dos perfiles suburbanos, entre los que podemos diferenciar un perfil (3) en el que abunda una población joven y activa, con familia, inmigrante de corta distancia (provincial), con vivienda en propiedad y trabajo en la provincia, frente a otro perfil (5) caracterizado fundamentalmente por la abundancia de inmigrantes de larga distancia (regionales, nacionales o extranjeros), muy activos en trabajos vinculados con la agricultura o los servicios y con vivienda sobre todo en alquiler. Finalmente destacan dos perfiles eminentemente rurales, uno en el que se observa cierta vitalidad, juventud y actividad económica (perfil 2) y otro en clara depresión, envejecimiento de su población y recesión (perfil 4).
Los perfiles pueden ser analizados estadísticamente tal y como hemos hecho anteriormente, o de un modo gráfico mediante los Mapas auto-organizados monotemáticos (Figuras 3 y 4). En ellos podemos observar una distribución “semántica” de todas las secciones censales estudiadas, situándose cada una de ellas junto a una semejante, atendiendo a la globalidad de las variables incorporadas al SOM. Asimismo las secciones censales semejantes se agrupan en los distintos perfiles o clusters (etiquetados en los gráficos como C1, C2, C5). El interés de esta representación consiste en su capacidad de proporcionar conocimiento de forma heurística, permitiendo descubrir cualidades y relaciones entre las distintas partes del mapa y, en consecuencia, entre los distintos perfiles. Por ejemplo, podemos observar cómo los índices más altos (rojo) de nacimientos, variable 3.1_%Nacimientos, salvo alguna excepción se sitúan en el Perfil 3 (C3), coincidiendo en gran medida, como era de esperarse, con los hogares que tienen dos adultos, tal y como se puede observar con las zonas marcadas igualmente en rojo en el mapa 3.2_%Hogares2adulto. Son numerosas las relaciones que se pueden encontrar entre los mapas auto-organizados monotemáticos, dependiendo del interés o enfoque particular del investigador.
Tras la Fase de modelado 1 y su interpretación, en la Fase de modelado 2 se obtendrá la identificación, o más bien la probabilidad de realizar correctamente la identificación de los perfiles demográficos, a partir de variables exclusivamente de la dimensión residencial. Es decir, es posible -para una sección censal- inferir o predecir la probabilidad de pertenencia a un perfil demográfico a partir de determinadas variables residenciales, como son el porcentaje de viviendas unifamiliares, el porcentaje de viviendas que tienen garaje, la edad media de construcción o el porcentaje de usuarios que se quejan por ruidos (Figura 6).
Se observa de este modo que hay determinadas variables que participan más que otras en la construcción del modelo; y, en el caso de que alguna de ellas no tenga relevancia para el mismo o incluso únicamente aporte ruido, el análisis estadístico tras la red neuronal o el árbol de decisión mostrará tal falta de significación y ausencia de valor, sin influir en ningún momento en la construcción del modelo basado en la red neuronal artificial.
5. Discusión y conclusiones
A partir del análisis de las experiencias bibliográficas de aplicación del modelo de clasificación y conocimiento mediante la metodología SOM y corroborado mediante la propia experiencia llevada a cabo, se puede concluir que la metodología SOM es útil para:
Realizar un análisis exploratorio (Spielman & Thill, 2008).
Hacer más potentes, robustas y más completas las clasificaciones descriptivas tradicionales (Hamaina et al., 2012).
Comprender los patrones de distribución espacial que se dan en un territorio atendiendo a las variables en estudio (Faggiano et al., 2010).
Explorar visualmente, validar y evaluar eficazmente gracias a las consistentes propiedades geométricas de los resultados de los SOM (AUTOR 1 & Osuna Pérez, 2013; Yan &
Thill, 2009).
Analizar eficazmente complejos conjuntos de datos geográficos, específicamente, demográficos (Takatsuka, 2001).
Inferir consideraciones espaciales a partir de los grupos taxonométricos hallados (AUTOR 1 et al., 2015; Faggiano et al., 2010).
Codificar las clasificaciones resultantes en un SIG consiguiéndose hacerlos más accesibles y comprensibles a una audiencia no familiar con los SOM (Kauko, 2005).
Etiquetar la realidad geográfica sin tener que nombrar tales categorías, evitando así las problemáticas inherentes del análisis de factores y de las técnicas geodemográficas (Spielman & Thill, 2008).
Superar los retos tradicionales asociados con el estudio de la complejidad de las comunidades ambientales, evidenciándose un gran potencial de la combinación del SOM y del SIG (Basara & Yuan, 2008).
Evaluar los efectos de la concurrencia de ciertas variables en estudio (Faggiano et al., 2010).
Constituir una potente solución alternativa, en un tiempo caracterizado por las tecnologías de la información y por la proliferación de datos (Hatzichristos, 2004).
Ser usado como un sistema de apoyo a la decisión para analizar y visualizar conjuntos de indicadores estadísticos para diversas aplicaciones (Kaski & Kohonen, 1996).
Por su lado la metodología basada en árboles de decisión a partir de una clasificación SOM se considera útil para:
Atribuir de forma muy sencilla patrones de comportamiento que pueden ser muy complejos.
Predecir de forma eficaz comportamientos de variables que presentan cierto coste o dificultad de evaluación, como son las variables demográficas o sociales, a partir de otras variables con menor complejidad y coste de evaluación, como las variables residenciales.
Generar y verificar hipótesis sobre realidades y comportamientos complejos, sin que sea necesaria la participación del usuario para su formulación.
Hacer accesible los sistemas de apoyo a la decisión a un público no experto.
Identificar variables que se relacionan de forma significativa y su peso o tamaño del efecto en la realidad estudiada.
Como oposición a las anteriores, es necesario tener presente ciertas precauciones y limitaciones en el uso de estas metodologías:
Un análisis de la población de una sección censal no es propiamente un análisis de la población y debe extremarse la precaución y limitar la inferencia a la escala de la observación, sin alcanzar directamente a los individuos (Spielman & Thill, 2008); es decir, no se debe extrapolar a individuos las conclusiones obtenidas del estudio de grupos de individuos.
La integración completa entre SOM y SIG es compleja (André Skupin & Hagelman, 2003), quedando limitada a una conexión más o menos manual. Salvo algunos intentos de conexión, aún no se ha implementado una conexión directa “amigable” entre ninguno de los principales softwares SIG y SOM (Takatsuka, 2001).
Las metodologías apoyadas en los sistemas basados en el conocimiento no se encuentran desarrolladas para la integración directa en los procesos de desarrollo y planificación urbana y territorial (Behnisch & Ultsch, 2009; Streich, 2005); situación que sugiere, en conjunción con la anterior, que existe una importante brecha tecnológica que puede convertirse en un espacio de desarrollo técnico, tecnológico y de oportunidad de investigación y/o de negocio.
La combinación del conocimiento experto con los resultados SOM requieren cierta creatividad (Kauko, 2005), sin ser en absoluto inmediatos ni obvios.
Mediante la investigación aplicada al caso de estudio de la región de Andalucía, se han obtenido unos árboles de decisión basados en una metodología de clasificación no supervisada basada en Mapas auto-organizados que han demostrado ser sencillos de usar, a la vez que útiles y capaces de predecir -con un relativo bajo error- fenómenos demográficos complejos y de relevancia a partir de la realidad residencial. Se puede, por tanto, concluir que existe una conexión y relación entre los fenómenos demográficos y la configuración residencial en Andalucía; por ello, se debe ser cauto y evitar a priori un establecimiento causa-efecto entre tales fenómenos, pues requerirían otras pruebas alejadas de los objetivos de esta investigación.

