











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
Según la Federación Internacional de Robótica (IFR) [1], un robot de servicio es un sistema robótico que opera total o parcialmente de forma autónoma para realizar servicios valiosos para el bienestar de los humanos y el equipo, excluyendo las operaciones de manufactura. Los robots de servicio están diseñados específicamente para entornos humanos, como hogares, hospitales y restaurantes, lo que les exige tomar decisiones complejas. Esto incluye identificar, detectar, reconocer y manipular diversos objetos dentro de su entorno.
Para que un robot de servicio opere de manera autónoma, debe estar equipado con un sistema de control que le permita interactuar con su entorno para tomar las decisiones correctas y lograr objetivos específicos. Un componente crítico de este sistema de control para los robots de servicio implica aprender sobre el entorno en el que operarán. Inicialmente, el robot debe familiarizarse con la ubicación y los elementos no dinámicos con los que interactuará. Por ejemplo, en algunas competiciones, se da a los participantes un período para familiarizarse con las interacciones del escenario y realizar las calibraciones necesarias para completar las tareas.
La capacidad de ver mejora su interacción con las personas y el entorno; por ejemplo, se utilizan sensores de visión para la localización y el mapeo [2]. Se desarrolla un sistema de estereovisión para detectar objetivos a partir del mapa de profundidad generado [3]. Además, Scona et al. [4] utilizaron un sensor de estereovisión para explorar desafíos como el desenfoque por movimiento, la falta de características visuales, los cambios de iluminación y el movimiento rápido.
En la localización ambiental por robots móviles, se implementó un sistema de visión para desarrollar algoritmos de localización y mapeo simultáneos (SLAM) [5]. En [6] se desarrolló una aplicación para mapeo topológico y navegación utilizando SLAM visual. Ovalle-Magallanes et al. [7] utilizaron información visual para crear un sistema de localización basado en la apariencia para un robot humanoide. Lasguignes et al. [8] implementaron un sistema de localización apoyado en ICP, utilizando información visual en el robot humanoide TALOS. Por el contrario, Wozniak et al. [9] propusieron un algoritmo para el reconocimiento visual de lugares utilizando imágenes adquiridas por un robot humanoide, con una red neuronal como reconocedor. También se desarrolló un SLAM elipsoidal basado en visión de hitos aumentados en un robot humanoide NAO para escenarios interiores [10]. Además, se implementó un método para SLAM eficiente utilizando un sensor de visión monocular con vista frontal [11].
Además de las cámaras RGB, se emplean otros sensores; en [12], se utilizó un sensor IMU para localizar un robot humanoide en el entorno. En [13] se implementó una combinación de LiDAR 2D y odometría para permitir que un robot navegue y se localice. Wen et al. [14] presentaron un EKF-SLAM, utilizando sensores de cámara y láser para la localización y el mapeo en interiores. Un SLAM, basado en visión, permite a un robot móvil navegar en entornos desconocidos [15]. En [16] se propone un sistema SLAM para estimar las poses del robot y construir un mapa tridimensional del entorno. Además, se combinó el seguimiento basado en características de un sensor de visión estereoscópica para obtener un SLAM híbrido [17].
Mientras tanto, Cheng et al. [18] utilizaron puntos característicos para desarrollar un método que integra el flujo óptico con ORB-SLAM para diferenciar entre elementos dinámicos y estáticos. Ganesan et al. [19] propusieron un método para reducir el espacio de búsqueda para el algoritmo RRT* en tareas de planificación de rutas. La coincidencia de características para algoritmos de construcción de mapas se exploró utilizando la distancia de una nube de puntos obtenida de un sensor de alcance [20]. Se construye un mapa del entorno utilizando una fusión de sensores de odometría, láser 2D y RGB-D [21]. Una propuesta donde el entorno se representa mediante polígonos 3D que permiten a un robot localizarse se presenta en [22]. En contraste, se propuso un sistema de navegación topológica basado en representación simbólica en [23] para un robot humanoide.
Todos los trabajos mencionados anteriormente emplean técnicas para mejorar la localización, el mapeo o la búsqueda de objetos dentro de un entorno humano, llevadas a cabo por un robot móvil. Por esta razón, se utiliza el robot humanoide NAO [24] como plataforma para implementar la localización y el mapeo en este estudio.
En la sección 2 se describe los diversos métodos y materiales utilizados en este estudio. Posteriormente, en la sección 2.5 se presenta la implementación del sistema propuesto. Los resultados obtenidos con ambas plataformas se detallan en la sección 3. Finalmente, la sección 4 se discute las conclusiones y las direcciones para futuras investigaciones.
Materiales y métodos
Robot NAO
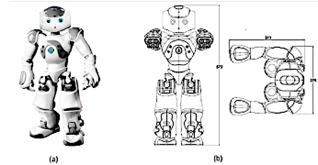
El robot NAO, como se muestra en la Figura 1(a), es la plataforma robótica principal elegida para implementar el sistema desarrollado. NAO, un robot autónomo y programable de altura media [24], es ampliamente reconocido como uno de los robots más sofisticados y completos del mercado. A lo largo de los años, se han introducido cinco versiones, cada una incorporando mejoras específicas, mientras que el concepto fundamental permanece inalterado.
La Figura 1(b) presenta un esquema del robot, indicando sus dimensiones, incluyendo altura, ancho y longitud de los brazos. El robot NAO está equipado con el software integrado NAOqi, que le proporciona autonomía. NAOqi está integrado en el sistema operativo del robot, OpenNAO, una distribución GNU/Linux embebida basada en Gentoo. Este sistema incluye numerosas bibliotecas y programas esenciales para NAOqi. Una característica notable es la capacidad de ejecutar copias de NAOqi en una computadora, lo que facilita el uso de robots virtuales.
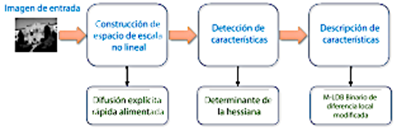
A-KAZE descriptor
El método A-KAZE [26], representado en la Figura 2, se divide en tres tareas principales: (1) construcción de un espacio de escala no lineal, (2) detección de características y (3) descripción de características. La construcción del espacio de escala no lineal implica procesar una imagen de entrada utilizando el método numérico de difusión rápida explícita (FED) [25], aplicado con un enfoque piramidal.
Inicialmente, el espacio de escala se discretiza en una serie de O octavas y S subniveles, identificados por índices discretos (o y s, respectivamente). Posteriormente, se mapean a su escala correspondiente, σ, utilizando la Ecuación (1).
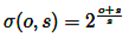 (1)
(1)La imagen de entrada se convoluciona con una desviación estándar gaussiana σ0 para reducir el ruido y los posibles artefactos, considerando tanto la imagen de entrada como un factor de contraste λ, que es calculado automáticamente por el algoritmo. Posteriormente, se detectan características 2D de interés que exhiben un determinante de escala normalizada de la respuesta hessiana a través del espacio de escala no lineal para cada imagen filtrada. La normalización se realiza utilizando un factor que tiene en cuenta la escala de cada imagen en el espacio de escala no lineal, como se ilustra en la ecuación (2).
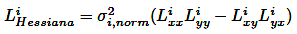 (2)
(2)El filtro concatenado de Scharr [27] calcula derivadas de segundo orden para aproximar la invariancia rotacional. Inicialmente, se obtiene la respuesta máxima del detector en una ubicación espacial específica para estimar la posición 2D del punto clave. Esto se logra ajustando una función cuadrática a la respuesta máxima del determinante de Hessian dentro de un vecindario de 3×3.
Finalmente, la orientación principal del punto clave se calcula utilizando el descriptor modificado-binario de diferencia local (M-LDB) [28]. Este método utiliza información sobre gradientes e intensidad del espacio de escala no lineal para generar un vector descriptor de longitud 64.
En el caso del descriptor utilizado, su principal ventaja es su rendimiento superior en la obtención de información visual al implementar el sistema de mapeo, debido a su invariancia a los cambios de escala y rotación. Además, opera más rápido que otros descriptores y el autor del algoritmo proporciona el código. Entre las desventajas, es necesario mencionar que se requiere una afinación precisa del umbral utilizado para identificar los puntos característicos, junto con el ajuste del número de niveles y subniveles dentro del espacio de escala no lineal.
Estructura de células en crecimiento
Las estructuras de células en crecimiento (GCS) [29] están disponibles en variantes supervisadas y no supervisadas. La variante de interés en este contexto es el modelo no supervisado, que ofrece la ventaja significativa de determinar automáticamente una estructura y tamaño de red adecuados. Esta capacidad se facilita mediante un crecimiento controlado, que incluye la eliminación periódica de unidades. Este modelo se basa en el trabajo de Kohonen [30] sobre mapas autoorganizativos. El pseudocódigo para GCS se presenta en el algoritmo 1, (ver figura 3).
El algoritmo de estructura de células en crecimiento (GCS) ofrece varias ventajas clave. Puede ajustar autónomamente el número de neuronas, añadiéndolas o eliminándolas según sea necesario. Funciona como una red no supervisada, lo que le permite formar asociaciones de vectores de entrada de manera independiente de la entrada externa. Su simplicidad de implementación es también una característica destacable. Sin embargo, una desventaja notable es que la red puede fallar si los vectores a asociar están muy cerca unos de otros.

Simulador robótico WEBOTS
Webots [31] es una aplicación de escritorio de código abierto y multiplataforma para la simulación de robots. Por esta razón, se utilizará Webots para simular el sistema y facilitar su respectiva validación.
Este simulador de software permite probar aplicaciones y algoritmos para el robot NAO dentro de un entorno virtual. La Figura 4 ilustra el entorno del software, un mundo virtual que simula los movimientos de NAO mientras se adhiere a las leyes físicas. Este entorno ofrece un entorno seguro para probar comportamientos antes de que se implementen en un robot real.
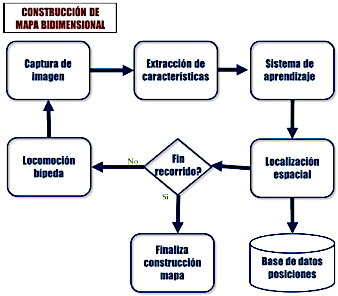
Construcción de mapas bidimensionales
Como se mencionó en la Introducción, la autonomía se logra a través de un sistema de planificación y control de actividades, diseñado para asegurar el cumplimiento de sus objetivos. Una característica clave de estos sistemas es la navegación espacial, que permite el cálculo de la pose del robot (posición y orientación) basada en mediciones incrementales, inerciales y visuales. Esta sección presenta los conceptos de odometría y características visuales empleados en el módulo de navegación espacial. Estas herramientas permiten al robot construir un mapa bidimensional y localizarse mientras navega.
Odometría
La odometría facilita la estimación de la posición relativa de un robot móvil dentro de un entorno durante la navegación, partiendo de su ubicación inicial. Además, registra y rastrea el movimiento del robot dentro de un espacio para construir un mapa bidimensional. El robot NAO tiene funciones que abordan varios desafíos, incluida la odometría. El algoritmo 2 (ver figura 5) muestra el pseudocódigo donde se utilizan funciones de la odometría inercial de Aldebaran [24].

En esta implementación, la posición bidimensional del robot se inicializa con valores explícitos obtenidos de los valores de pose inicializados, que se recuperan de los encoders rotatorios magnéticos (MRE) de las articulaciones. Cada vez que el robot se activa, registra una posición absoluta dentro del mundo del escenario.
Al construir el mapa bidimensional, el robot primero guarda su posición inicial. Luego, se le instruye para que siga una trayectoria de circuito cerrado predeterminada dentro de la habitación, avanzando una distancia especificada mientras camina. A medida que se mueve, la posición bidimensional del robot se registra periódicamente. Posteriormente, se calculan el desplazamiento y el ángulo recorridos por el robot. La posición bidimensional entre puntos consecutivos se calcula entonces para reflejar con precisión el movimiento del robot.
Así, la implementación general de la odometría puede establecerse de la siguiente manera:
Capturar la posición del robot relativa al entorno antes de caminar.
Detectar cuando el robot comienza a caminar.
Simultáneamente, comenzar a recopilar datos Odométricos.
Procesar y acumular los datos odométricos.
Detectar la finalización del recorrido del robot. Si el recorrido no está completado, repetir los pasos 3 y 4.
Calcular la distancia recorrida por el robot.
Almacenar los datos de distancia y posición del robot para construir el mapa bidimensional.
La Figura 6 presenta el diagrama de flujo general para generar el mapa bidimensional. En este diagrama, el algoritmo comienza con la captura de una imagen. Posteriormente, se extraen características visuales de esta imagen; estas características sirven como entradas para el sistema de aprendizaje, es decir, la red neuronal. A continuación, el robot aprende y registra la localización espacial correspondiente a su posición. Si el recorrido designado se completa, el algoritmo concluye. Si no, el robot se mueve a la siguiente posición y el algoritmo continúa hasta que se alcance el final del recorrido.
Características visuales
Los elementos visuales se identifican analizando y catalogando los detalles existentes en el entorno, considerando la posición del robot cuando se captura la imagen. Generalmente, se considera que los elementos visuales más significativos para representar el entorno son aquellos ubicados en o cerca de las paredes. Un mapa bidimensional de la habitación recorrida por el robot puede construirse utilizando estos elementos visuales y la ubicación estimada derivada de la odometría. Por ejemplo, la Figura 7 ilustra una habitación virtual con varios objetos cotidianos típicamente encontrados en un hogar. Estos objetos suelen permanecer estacionarios. Por lo tanto, el robot debe navegar por esta habitación siguiendo un circuito cerrado, preferiblemente cuadrangular, capturar imágenes y registrar la posición estimada desde donde se tomó cada imagen.

Además, el robot debe centrarse en capturar imágenes de la pared más cercana a su recorrido. La Figura 8 ilustra tres capturas realizadas por el robot en diferentes puntos. Durante la navegación, tomará una captura de pantalla en cada paso basado en el número de imágenes especificadas por el usuario para la habitación. Por ejemplo, si se requieren veinte imágenes en una habitación donde cada pared mide 4 metros de largo, se tomará una imagen cada 20 cm. Además del número de capturas y las dimensiones de las paredes de la habitación, también se puede determinar la frecuencia del recorrido. Cuantos más circuitos se completen, más detallada será la construcción del mapa de la habitación y más fácil será localizar al robot.
Una vez completados los circuitos, el robot utiliza la información almacenada para construir el mapa bidimensional. Las imágenes capturadas contendrán objetos de los cuales se deben extraer detalles específicos. El módulo de reconocimiento de objetos [32] procesa las imágenes para obtener descriptores, que luego se aprenden y se vinculan a la pose del robot durante la captura. Esta información se integra en una representación bidimensional, formando el mapa de la habitación. Antes de iniciar cualquier recorrido por la habitación, el robot debe identificar la pared más cercana para determinar dónde enfocará sus capturas de imagen, simplemente girando su cabeza hacia la pared visible. Esta detección de paredes se logra estimando visualmente las distancias. Antes de la navegación, el robot debe estar posicionado en paralelo a la pared seleccionada y colocado en una esquina de la habitación. Luego captura una imagen, que se analiza posteriormente dividiéndola en dos partes.

Por ejemplo, la Figura 9 muestra tres capturas diferentes de una habitación tomadas desde varias posiciones del robot. En la imagen 9(a), la pared más cercana está a la izquierda, mientras que en las imágenes 9(b) y 9(c), está a la derecha. Para cada imagen, se identifican puntos de interés en cada lado utilizando el algoritmo A-KAZE [26]. La imagen con más puntos salientes indica la ubicación de la pared más cercana, asumiendo que la habitación está libre de obstáculos.

La Figura 10 muestra los resultados de la evaluación para cada imagen, con los puntos salientes indicados por pequeños círculos de colores. En la imagen 10(a), el lado derecho contiene la mayoría de los puntos salientes, con 108 en comparación con 36 en el lado izquierdo; en la 10(b), predomina el lado izquierdo con 128 puntos frente a 50 en el derecho; y en la 10(c), nuevamente el lado izquierdo lidera con 119 puntos comparados con 53 en el derecho. Basándose en estas observaciones, el robot luego gira hacia el lado con más puntos salientes para continuar su exploración de la habitación.

Algoritmo para la construcción del mapa
La construcción del mapa bidimensional procede de la siguiente manera: inicialmente, el robot realiza un circuito cerrado alrededor de una habitación cuadrada, capturando y registrando imágenes junto con sus respectivas poses. Es esencial conocer las dimensiones de las paredes, el tamaño del paso durante el movimiento y el número de iteraciones. El robot mejora su comprensión de la habitación con cada circuito adicional completado. Al inicio del algoritmo 3 (ver figura 11, el robot realiza una captura inicial para detectar la pared más cercana y determinar el ángulo para su siguiente giro.
Antes de comenzar su movimiento, el robot registra su posición actual mediante odometría como el punto de referencia global para la habitación. Posteriormente, se registra la distancia recorrida, indicando tanto la longitud del trayecto del robot como la distancia total que necesita navegar dentro de la habitación. Esta medida se monitorea continuamente durante un ciclo de trabajo, que persiste hasta que la distancia recorrida sea igual a la longitud combinada de las cuatro paredes de la habitación.

Después de completar el circuito y almacenar la base de datos de la habitación, se inicia el algoritmo 4 (ver figura 12) para aprender de una nueva base de datos que incluye información de captura y pose. Se extraen todos los puntos de interés, se construyen histogramas y se entrena una red neuronal utilizando el método de Growing Cell Structures (GCS) [32].

El algoritmo 5 (ver figura 13) se utiliza para evaluar el mapa. Este módulo procesa las imágenes, extrayendo puntos salientes y construyendo histogramas. Estos histogramas se utilizan luego para evaluar la red neuronal entrenada. Este proceso ayuda a identificar las neuronas correspondientes. Una vez determinadas las clases, se recuperan las poses asociadas. Las posiciones bidimensionales en el mapa se calculan luego y se devuelven.
El algoritmo opera dentro de ciertas restricciones, que incluyen conocer las dimensiones de la habitación para calcular la distancia total que el robot recorrerá alrededor de ella. Además, el entorno debe estar libre de obstáculos, ya que este trabajo no incorpora estrategias de evasión de obstáculos.
Finalmente, si algún elemento dentro de la habitación ha sido movido, el robot debe reconstruir su mapa de navegación para reflejar estos cambios.

Resultados y discusión
Los experimentos descritos en esta sección se dividen en dos partes: (1) construcción de un mapa bidimensional y (2) localización dentro del mapa. Estos experimentos se han llevado a cabo utilizando tanto robots NAO virtuales como reales.
Entorno virtual
Construcción del mapa
La habitación simulada representada en la Figura 7, con dimensiones de 6×6 metros, fue creada utilizando Webots. Esta habitación estaba amueblada con varios objetos, como sillas, mesas y retratos. Se empleó un robot NAO virtual para construir el mapa bidimensional de la habitación. El robot inició su recorrido desde la esquina inferior izquierda de la habitación, navegando en un circuito cerrado cuadrangular. El robot giró la cabeza hacia las paredes durante todo su recorrido para capturar imágenes. Las paredes se numeraron del 1 al 4 en sentido antihorario para ilustrar los resultados de la construcción del mapa bidimensional.
El robot completó dos circuitos en sentido antihorario alrededor de la habitación, capturando imágenes y registrando sus relaciones espaciales. El número de imágenes tomadas por pared se detalla en la Tabla 1. El término ’vuelta’ se refiere al número de circuitos que completa el robot. ’Imágenes’ indica el número total de imágenes guardadas durante cada vuelta. ’Pared 1’, ’Pared 2’, ’Pared 3’ y ’Pared 4’ indican el número de imágenes almacenadas para cada pared. En total, se registraron 164 imágenes y sus poses asociadas, las cuales se utilizaron para construir el mapa bidimensional.

Los parámetros correspondientes al reconocimiento de objetos se detallan en la Tabla 2. Como se señala, se realizaron tres iteraciones de construcción de mapas bidimensionales utilizando 100, 200 y 300 neuronas, respectivamente. El objetivo fue evaluar la efectividad del módulo en construir un mapa que refleje con precisión las observaciones del robot dentro de la habitación.
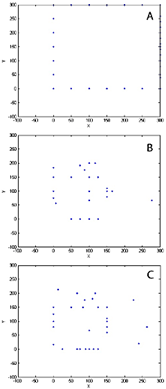
Después del entrenamiento, se generaron mapas bidimensionales que contenían 72, 111 y 132 poses, respectivamente. Los puntos marcados en cada mapa en la Figura 14 representan una pose asociada con una neurona. Es evidente que a medida que aumenta el número de neuronas, la distribución de las poses se vuelve más refinada. Es importante destacar que las poses se homogeneizaron en las coordenadas y se mantuvieron constantes durante el recorrido para asegurar que se muestre una distribución precisa.
Tabla 2 Parámetros del módulo de reconocimiento de objetos para la construcción del mapa bidimensional

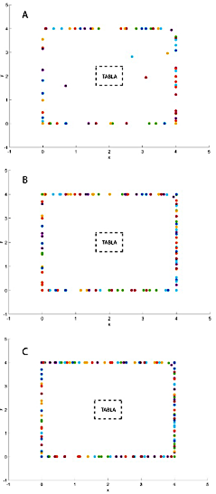
Figura 14 Distribución de neuronas por poses en la habitación de los experimentos: (a) 1, (b) 2 y (c) 3.
La distribución en el mapa construido con cien neuronas es subóptima, ya que incluye algunas poses en áreas donde el robot no ha viajado, junto con agrupamientos de poses en ciertas secciones. La distribución mejora significativamente en el mapa construido con doscientas neuronas, aunque aún se observa cierto apilamiento de poses. El mapa con trescientas neuronas muestra la mejor distribución, cubriendo más áreas de manera más completa. Aunque aún existen algunas poses erróneas, son mínimas.
Gracias al mapa bidimensional, el robot puede identificar las ubicaciones de las paredes, lo que le permite evitarlas mientras ejecuta sus tareas.
Ubicación en el mapa
El propósito del mapa bidimensional es permitir que el robot regrese a la posición global 0 en el mapa una vez que haya completado sus tareas. Con el mapa construido, el robot puede determinar su ubicación dentro de la habitación utilizando una o dos imágenes de las paredes más cercanas. Se realizaron cuatro experimentos para validar esta funcionalidad.
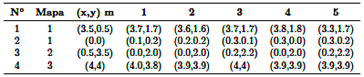
La Tabla 3 enumera los parámetros, que incluyen el número de experimento, el mapa bidimensional construido en la sección anterior (1, 2 y 3), y la posición real a calcular (x, y) en metros.
La construcción del mapa bidimensional se evalúa de la siguiente manera: el robot virtual captura dos imágenes desde diferentes perspectivas en cada una de las cuatro posiciones más cercanas a las paredes bajo evaluación. Ejemplos de estas capturas realizadas por el robot se ilustran en la Figura 15. En cada posición, se capturan dos imágenes de las paredes más cercanas.

Las dos primeras imágenes superiores corresponden a la posición (0, 0), mientras que las dos siguientes corresponden a la posición (4, 4) dentro de la habitación. Los resultados se presentan en la Tabla 3, que detalla cinco evaluaciones con dos imágenes para cada experimento. El módulo registra las poses individuales capturadas en cada columna para los cuatro experimentos, con un par de imágenes por evaluación.
Escenario real
Construcción del mapa
El mapa bidimensional se construyó en una habitación de 4×3 metros, dentro de la cual el robot desarrolló un mapa de 3×3 metros. La habitación contiene varios elementos, incluidos carteles con información diversa. La Figura 16 muestra las cuatro paredes de la habitación, ilustrando los elementos utilizados para el aprendizaje. Además, hay una plataforma de 30 cm ubicada en el centro de la habitación, como se muestra en la Figura 17. Esta plataforma sostiene 20 objetos distribuidos a lo largo de los bordes, mejorando la visibilidad para el robot y asegurando que los objetos permanezcan dentro del área de trabajo de los manipuladores para facilitar su recuperación.

Esta evaluación completó tres circuitos para construir un mapa más preciso. El robot inició su ruta desde las coordenadas globales de la habitación (0, 0), ubicadas en la esquina derecha de la pared 1.
Durante los recorridos, el robot gira la cabeza hacia la pared para capturar imágenes mientras avanza y mantiene su posición relativa (Figura 18).


La Tabla 4 detalla las imágenes capturadas durante cada circuito a lo largo de las paredes. Esta tabla especifica el número de circuitos completados, el total de imágenes tomadas y las imágenes capturadas correspondientes a cada pared. Se registraron un total de sesenta y ocho imágenes y poses utilizadas para construir el mapa bidimensional.
Al igual que en el escenario virtual, las imágenes capturadas se introducen en el módulo de reconocimiento de objetos, encargado del aprendizaje de características y la generación del mapa de la habitación.
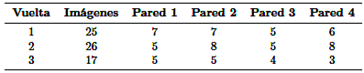
Tabla 5 presenta los parámetros utilizados para generar el mapa de la habitación, incluyendo el número de experimentos realizados, las imágenes utilizadas para el entrenamiento, el número de neuronas y las épocas involucradas.

Después del entrenamiento, los mapas bidimensionales contenían 27 y 36 poses, respectivamente. La Figura 19 muestra estos mapas, donde los puntos azules indican las poses en las que el robot capturó imágenes. La Figura 19(a) ilustra el mapa ideal, mostrando las poses objetivo para la captura de imágenes durante los experimentos. El mapa construido para el experimento 1 corresponde a la Figura 19(b), mientras que el mapa para el segundo experimento se representa en la Figura 19(c). Estos mapas reflejan la distribución de las neuronas asociadas con cada pose. Se observa que al aumentar el número de neuronas de 400 a 500 mejora ligeramente la distribución. Sin embargo, el tamaño del mapa construido se redujo de 3×3 metros a 1,5×1,5 metros.
Desde el análisis anterior, se puede inferir que la reducción en el tamaño del mapa se debió a numerosos falsos positivos y a la interasociación de poses, lo que condujo a su consolidación.
Localización en el mapa bidimensional
La tarea de localización en el mapa bidimensional sirve varios propósitos. Un objetivo clave es que el robot regrese al punto de partida para entregar un objeto solicitado por el usuario. Además, el robot utiliza el mapa para localizar las paredes de la habitación, lo que ayuda a evitarlas durante las tareas de búsqueda de objetos.
Por lo tanto, con el mapa construido, el robot puede determinar su ubicación dentro de la habitación utilizando una o dos imágenes de las paredes más cercanas. Esta capacidad se evaluó a través de diez experimentos que se llevaron a cabo.
La Tabla 6 enumera los números de experimento y las posiciones correspondientes a calcular (x, y) en metros.

La precisión de la ubicación del robot en el mapa bidimensional se determina utilizando dos imágenes capturadas desde las posiciones potenciales más cercanas a la pared adyacente a ese punto.
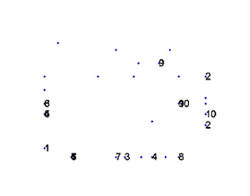
Los resultados se presentan en la Tabla 7, donde se muestran las diez ubicaciones asociadas con dos poses derivadas de la evaluación de las dos imágenes tomadas desde cada posición. Debido a las imprecisiones en la construcción del mapa bidimensional, las poses obtenidas no coinciden estrechamente con las posiciones reales.
La mayor precisión se logró con la pose número (1), mostrando una precisión de ±(0.25, 0.16) cercana a la pose esperada. La siguiente mejor precisión se obtuvo con la pose número (9), mostrando una precisión de ±(0.34, 0.62). Las poses menos precisas fueron (2) y (8), con precisiones de ±(1.50, 0.50) y ±(1.75, 2.00), respectivamente. Aunque el mapa construido fue inexacto, la evaluación arroja resultados favorables dados el mapa entrenado. La Figura 20 proporciona una representación gráfica de las diez ubicaciones determinadas, utilizando el módulo en el mapa bidimensional previamente entrenado. Se observa que la mayoría de las poses están muy cerca de las posiciones entrenadas, excepto 2, 7 y 8, que estaban significativamente desalineadas.

Conclusiones
Este estudio presenta el desarrollo de un algoritmo para la construcción de mapas bidimensionales utilizando odometría inercial y elementos visuales. El mapa bidimensional se crea utilizando un módulo de reconocimiento de objetos basado en características locales y redes neuronales artificiales no supervisadas. Este módulo se utiliza para aprender el diseño de la habitación y asociar una pose con cada neurona en la red, que se entrena para representar el mapa bidimensional.
Se realizaron experimentos utilizando (1) un robot NAO virtual y (2) un robot NAO real en un escenario auténtico. Los resultados son prometedores, ya que fue posible construir un mapa bidimensional de la habitación y localizar con precisión el robot móvil con una precisión de hasta ±(0.06, 0.1) en simulación y ±(0.25, 0.16) en el entorno natural. Estos resultados pueden mejorarse aún más mejorando la calidad de las imágenes capturadas.
El enfoque para generar mapas a partir de información visual presenta varias limitaciones, incluyendo las siguientes:
Las cámaras del robot NAO no son óptimas para capturar imágenes de alta calidad, lo que conduce a errores tanto en las fases de aprendizaje como de reconocimiento.
El entorno debe estar estructurado para incluir suficientes referencias visuales en las paredes de la habitación para mejorar la precisión de localización del robot.
Esta implementación no tiene en cuenta elementos dinámicos; por lo tanto, la escena solo contiene al robot, la mesa y los objetos circundantes.
El camino del robot debe ser recto, lo que requiere un camino despejado libre de objetos para permitir un posicionamiento adecuado con respecto a la pared y sus marcadores visuales.
El enfoque depende en gran medida de la información visual, por lo que la ausencia de esta información causaría confusión y obstaculizaría significativamente la capacidad del robot para navegar por la habitación.
Trabajo futuro
Fusión avanzada de sensores: El trabajo futuro se centrará en mejorar la integración de datos de odometría inercial y elementos visuales. Este enfoque tiene como objetivo reducir la dependencia únicamente de características visuales, mejorando así la robustez y precisión del sistema.
Evaluación de arquitecturas de redes neuronales: Se evaluarán diversas arquitecturas de redes neuronales para determinar cuál es la más adecuada para la tarea de construcción de mapas. La arquitectura que muestre el mejor rendimiento será seleccionada para un desarrollo e implementación adicionales.
Pruebas de detectores avanzados de puntos característicos: Para mejorar el rendimiento del sistema, se probarán detectores de puntos característicos de última generación. Se espera que estos detectores ofrezcan mejoras significativas en la detección y procesamiento de puntos característicos, contribuyendo a la eficiencia general del sistema.

