











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Los sistemas de detección de peatones (SDP) son uno de los componentes tecnológicos más importantes que han surgido en los últimos años con el desarrollo de robótica móvil aplicada al sector automotriz y otras tecnologías similares destinadas a la seguridad vehicular [6], las cuales necesitan operar con altos estándares de calidad y tener una alta eficacia y precisión, debido a que su objetivo es proteger la vida humana a través de evitar que suceda un atropellamiento [7].
Varios informes, a nivel mundial, indican que los accidentes de tránsito generan altos costos materiales y humanos [8], donde los peatones tienen un alto porcentaje de accidentabilidad, llegando hasta el 22 % [9]. En el caso de Ecuador, los atropellamientos representan más del 10 % de las defunciones por accidentes de tránsito [10]. Por lo tanto, la detección de peatones es un tema de investigación activo y desafiante debido a la complejidad de la escena vial, la cual cambia constantemente debido a varios factores, por ejemplo, las condiciones atmosféricas contribuyen a una baja visibilidad y a un cambio permanente de la iluminación, las oclusiones generan información incompleta de la forma humana, la distancia perjudica la calidad de la información visual [6], [11], [12]. En la noche estos percances se magnifican debido a los ambientes de oscuridad [6], [7], [13], [14].
Por otra parte, debido al reciente éxito que han presentado las técnicas de aprendizaje profundo (Deep Learning) [15], [16], el principal objetivo de este trabajo es poner en marcha un método para la detección de peatones en la noche usando información visual en el infrarrojo lejano y las redes neuronales convolucionales, específicamente las arquitecturas del tipo Faster R-CNN [1], [14], [16], [17], [18], [19] para obtener un sistema competitivo que genere resultados de vanguardia comparables a los existentes en los trabajos previos. Por lo tanto, se presenta una nueva arquitectura Faster R-CNN a múltiples escalas, la cual es evaluada bajo los conjuntos de prueba de las bases datos CVC-09 [4] y LSIFIR [5]. Los resultados evidencian mejoras especialmente al detectar peatones que se encuentran en la lejanía.
El documento está organizado de la siguiente manera. A partir de la segunda sección se presenta los métodos y materiales usados, donde se detallan los trabajos previos realizados en el campo de los SDP en especial técnicas de aprendizaje profundo. Adicionalmente, se describe el diseño propuesto de la nueva arquitectura Faster R-CNN para la generación de regiones de interés, la clasificación y la detección de peatones durante la noche, seguido de la evaluación experimental para distintas configuraciones del modelo propuesto. Posteriormente en la sección de resultados y discusión se exhiben los valores obtenidos respecto a la calidad de detección sobre las bases de datos destinadas al desarrollo de SDP en la noche. Finalmente, la última sección está dedicada a las conclusiones, recomendaciones y los trabajos futuros que se pueden efectuar para mejorar esta propuesta.
Métodos y materiales
Trabajos previos
Actualmente, existen múltiples investigaciones especializadas en la detección de peatones en la noche [6], [7], [12], [13], [14], [19], [20], [21], [22], [23], [24], [26], [27], [29], [36], [37], [38], [40], [41]. Para llevar a cabo este proceso, generalmente, se divide el trabajo en dos partes, la primera consiste en la generación de ROI; y la segunda en la clasificación de las mismas, en peatones o el fondo, de esta manera, se logra mantener localizada a la persona mientras permanece en la escena.
Generación de ROI sobre imágenes en el infrarrojo lejano
Para la generación de ROI sobre imágenes en el infrarrojo existen varios métodos, los más populares son: ventanas deslizantes (Sliding window) [20] que buscan exhaustivamente sobre toda la imagen en varias escalas, lo que hace que el método demande muchos recursos computacionales y no ser efectivo para aplicaciones en tiempo real. Para subsanar estos inconvenientes se han creado nuevas propuestas, por ejemplo, segmentación por movimiento, propuesto por Chen et al.[21] donde utilizando PCA y técnicas Fuzzy identifican regiones de interés local. Kim y Lee [23] han desarrollado un método que combina segmentos de imagen en lugar de umbrales y las bajas frecuencias de las imágenes en el infrarrojo lejano. Ge et al.[24] han propuesto un método de segmentación adaptativo compuesto de dos umbrales, uno especializado para localizar zonas brillantes y otro para zonas de poco contraste. Chun et al.[25] aplica detección de bordes para obtener un generador de ROI más rápido.
En la actualidad existen métodos más sofisticados que usan modelos de redes neuronales convolucionales, y sus variantes, para la generación de nuevas propuestas [1], [6], [14], [20]. Así, la detección de puntos de calor en resolución multiespectral usando IFCNN (Illumination Fully Connected Neural Network) ha sido propuesta por Guan et al.[13]. Vijay et al.[22] añaden una red neuronal convolucional al trabajo de Chen et al.[21], para la clasificación. Kim et al. [26] han usado cámaras en el espectro visible para detectar peatones en la noche usando CNN. Otras alternativas la red de propuestas de región (Region Proposal Network o RPN), inicialmente se central en localizar las ROI mediante una combinación de búsqueda exhaustiva y ventanas deslizantes, en tres orientaciones y tres escalas (9 cajas de referencia) por cada ventana deslizante. Cada propuesta inicial sirve para el entrenamiento de una red completamente convolucional para generar las predicciones del cuadro delimitador y los puntajes de probabilidad [1].
Clasificación de peatones sobre imágenes en el infrarrojo lejano
Los métodos desarrollados para la clasificación se pueden agrupar en dos categorías: los modelos basados en la generación manual de características [27], [28], [29], y los modelos de aprendizaje automático de características usando técnicas de aprendizaje profundo (DL, Deep Learning) [13], [16], [30], [31], [32], [33], [34], [35].
En el primer caso se usan distintos métodos manuales de generación de características junto con un algoritmo de clasificación, algunos ejemplos son: HOG + SVM [36], [37], HOG + Adaboost [38], HOG + LUV [39], Haar + Adaboost [40], Haar + HOG y SVM [41]. En la segunda categoría están las redes neuronales convolucionales (CNN) [7], [13], [16], [31], [35], con sus distintas arquitecturas, como son R-CNN [42], Fast R-CNN [43] y Faster R-CNN [1], [19].
La arquitectura Fast R-CNN [1], [19] esencialmente disminuye la carga computacional, respecto a CNN, y por esta razón disminuye el tiempo de detección que presenta la capa R-CNN [43]. En consecuencia, Fast R-CNN junto con búsqueda selectiva, presenta una mejor calidad de detección. Sin embargo, ambos métodos necesitan de un generador de ROI externo y tienen problemas al momento de detectar objetos pequeños que, en el contexto de los peatones, implica largas distancias [43], [44].
Para remediar estos inconvenientes se ha llegado a Faster R-CNN [1], [19] que añade un generador de ROI basado en capas completamente conectadas RPN el cual comparte con Fast R-CNN [19], los mapas de características generados por la red convolucional. Por ende, se puede implantar redes muy profundas debido a que la imagen total pasa una sola vez por la etapa CNN [19].
Por lo tanto, Faster R-CNN está siendo utilizada ampliamente para construir SDP [6], [14], [44]. Por ejemplo, en [6] se ha empleado Faster R-CNN para detección de peatones en múltiples espectros, inicialmente se ha entrenado Faster R-CNN únicamente con imágenes a color e infrarrojas, Faster RCNN-C y Faster RCNN-T respectivamente, utilizando para el entrenamiento un nuevo modelo de red neuronal. Posteriormente se han combinado características en diferentes etapas creando así los modelos Early Fusion, Halfway Fusion, Late Fusion y Score Fusion. Adicionalmente, Wang et al.[14], tomando como referencia a Liang et al.[43], combina RPN + BDT para construir un sistema de detección de peatones en múltiples espectros. Sin embargo, se considera que Faster RCNN no funciona muy bien para la detección de peatones, debido a que los mapas de características no presentan la información suficiente para peatones a larga distancia. Por esta razón, Feris et al.[45] han propuesto una subred para la generación de ROI en múltiples escalas junto con una subred para la clasificación basada en Fast R-CNN.
Sistema de detección de peatones en la noche
La Figura 1 muestra el esquema propuesto para el desarrollo del SDP en la noche, usando imágenes tomadas con iluminación infrarroja y como arquitectura base Faster R-CNN junto con el modelo VGG16 [2] donde se han desarrollado algunos cambios detallados a continuación.
Generación de ROI sobre imágenes en el infrarrojo lejano
Debido a que la arquitectura original de Faster RCNN [1], [19] presenta problemas de detección en el caso de peatones que se encuentran en la lejanía, se considera la arquitectura desarrollada en Feris et al.[45]. Por lo tanto, se ha decidido colocar dos redes de propuestas de región (RPN) independientes, que presentan diferentes características, las mismas que están detalladas en la Tabla 2. En ambos casos, con un enfoque dirigido a peatones a corta (RPNCD) y larga distancia (RPNLD). Como se muestra en la Figura 2, RPNLD es alimentado por las características que son proporcionadas por la capa conv4_3 de VGG16 [2], debido a que las redes de agrupación pueden discriminar peatones que se encuentren en la lejanía, donde los mapas de características más abundantes son beneficiosos para detectar peatones a largas distancias [11]. En cuanto a RPNCD al igual que la arquitectura original de Faster R-CNN [1] es alimentado por las características entregadas por la capa conv5_3, ya que extrae las características más representativas presentes en la imagen, por esta razón proporciona excelentes resultados para peatones a corta distancia.

Figura 1. Esquema del sistema de detección de peatones en la noche usando Faster R-CNN e imágenes en el infrarrojo lejano.
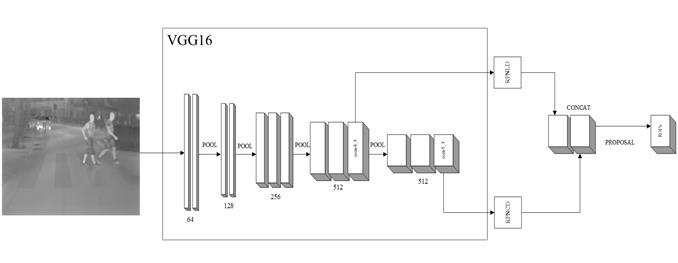
Figura 2. Arquitectura RPN multiescala basada en la red VGG16 [2]. Esta es la subred encargada de la etapa de generación de ROI.

Figura 3. Arquitectura de clasificación MS-CNN [41]. Esta subred está destinada para la etapa de clasificación.
Clasificación de ROI sobre imágenes en el infrarrojo lejano
Para la etapa de clasificación se propone la arquitectura que se presenta en la Figura 3. Como en [45] se considera aumentar la resolución de los mapas de características aplicando deconvolución, para proveer mejor información a la capa de agrupamiento ROI. Por lo tanto, la parte de Fast R-CNN recibe como entrada directamente las características extraídas por la capa conv4_3 de VGG16 [2], su deconvolución y las ROI generadas por RPNCD y RPNLD, en conjunto.
Detalles técnicos de la implementación
El aprendizaje de la arquitectura propuesta se ha desarrollado a partir de las bases de datos CVC-09 [4] y LSIFIR [5] que se detallan a continuación:
1. La base de datos CVC-09 [4]: Es una de las bases más utilizadas para la detección de peatones en la noche. En este caso se la usó para el entrenamiento y prueba de la propuesta, y posteriormente para su validación. En la Tabla 1 se describen los conjuntos de entrenamiento y de prueba. Esta base de datos viene etiquetada con los peatones presentes en la escena Bgt

Sin embargo, para el caso de largas distancias la base de datos presenta inconsistencias que han sido corregidas. Así, se ha re-etiquetado un conjunto de imágenes para corregir estos inconvenientes y depurar los errores de etiquetado.
2. La base de datos LSI Far Infrared Pedestrian Dataset (LSIFIR) [4]: Es otra base de datos importante destinada al desarrollo de algoritmos de detección de peatones en la noche. En la Tabla 2 se describen los conjuntos de entrenamiento y de prueba, con sus respectivos tamaños. En este caso al igual que CVC-09 se la usó para el entrenamiento, validación y prueba de la propuesta.

Tabla 2. Contenido de la base de datos LSIFIR. El valor entre paréntesis representa el número de fotogramas que contienen peatones
Para el aprendizaje de la red, el algoritmo inicialmente re-escala la parte más corta de la imagen de entrada a 600 pixeles. En cuanto al entrenamiento de la red, se lo realiza mediante la metodología de entrenamiento conjunto aproximado planteada por Ren et al.[1], además, los pesos de cada capa perteneciente a la red son inicializados por medio del modelo pre-entrenado VGG16, para luego ser sintonizado mediante Minibatch Stochastic Gradient Descent [46] y el reciente algoritmo de optimización Adam [47] con hiperparámetros detallados en la Tabla 3.
En cuanto a las RPN, estas trabajan de manera independiente. Por lo tanto, su entrenamiento también lo es. Las propuestas generadas por cada una de ellas son combinadas para luego ser etiquetadas mediante el algoritmo de NMS (Non Maximum Supression), donde si el índice IoU (Intersection over union), dada por Ecuación (1), es mayor que 0,6 es un peatón, si es menor que 0,3 es etiquetado como no peatón, y en caso de no cumplir con ninguna de las dos condiciones, dichas propuestas son excluidas del entrenamiento.
Inmediatamente, en la etapa de clasificación se vuelve a aplicar NMS para reducir redundancias en la detección, aplicando un umbral de 0.6, donde cada detección mayor al umbral se etiqueta como peatón caso contrario no peatón.

Donde B gt es la intersección y B det la unión, entre el cuadro delimitador real anotado en la base de datos CVC-09 [4] o LSIFIR [5] y el resultado del cuadro delimitador predicho por nuestro modelo.
Evaluación experimental
Para llegar al modelo propuesto, se han desarrollado múltiples experimentos, como se puede observar en las Tablas 4 y 5. Donde se analiza la subred de generación de ROI y los efectos que provoca la configuración de las distintas escalas y las relaciones de aspecto de RPNCD y RPNLD.
Para los experimentos se ha hecho uso de los conjuntos de entrenamiento de CVC-09 junto con LSIFIR para la etapa de aprendizaje de la red y los conjuntos de prueba para la evaluación.
Adicionalmente, se analizó la subred de clasificación y los efectos que provoca la deconvolución. En la Tabla 5, los resultados demuestran que al aplicar esta estrategia permite aumentar la resolución de los mapas de características, lo cual provoca un incremento del mAP en un 6 % aproximadamente.
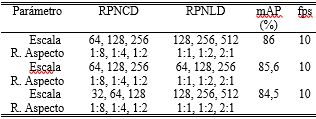
Tabla 4. Parámetros de configuración de cajas de referencia RPN para peatones a corta y larga distancia. Resultados de la subred de generación de ROI

Resultados y discusión
En cuanto a la evaluación de la efectividad de la propuesta se utilizaron dos de las bases de datos que representan el punto de referencia, destinadas al desarrollo de sistemas de detección de peatones durante la noche utilizando iluminación infrarroja.
Protocolo de evaluación
Para evaluar el sistema propuesto se propone la métrica precisión media promedio (mAP que es el Mean Average Precision) la cual permite medir la precisión del detector, de manera que se calcula la precisión promedio de cada detección para diferentes valores del índice recall [1].
Adicionalmente, se seguirá el protocolo estándar planteado por Dollár et al. [48], es decir, se usarán las curvas que relacionan la tasa de error promedio (miss rate) versus los falsos positivos por imagen (FPPI); en el rango de 10−2 a 100 FPPI, que es un indicador de la exactitud especializado en temas vehiculares para la detección de peatones.
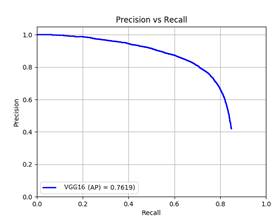
Figura 4. Curva Precisión vs. Recall de los resultados obtenidos con el modelo VGG16 [2] junto con Faster R-CNN para la clase peatón, sobre la combinación de los conjuntos de prueba de las bases de datos CVC-09 y LSIFIR.
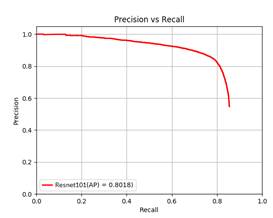
Figura 5. Curva Precisión vs. Recall de los resultados obtenidos para el modelo Resnet 101 [3] junto con Faster R-CNN para la clase peatón, sobre la combinación de los conjuntos de prueba de las bases de datos CVC-09 y LSIFIR.
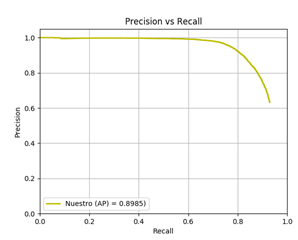
Discusión de los resultados
Los experimentos llevados a cabo sobre los conjuntos de prueba de las bases de datos CVC-09 [4] y LSIFIR [5] para distintas arquitecturas de red Faster R-CNN se presentan en la Tabla 6. Los resultados han sido obtenidos bajo las mismas condiciones computacionales, donde se puede observar que esta nueva propuesta alcanza un mAP de 94,6 %, en la etapa de validación, lo que demuestra que el aprendizaje es superior a las otras propuestas. Pero tiene el inconveniente de requerir un mayor esfuerzo computacional.
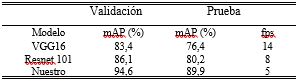
Tabla 6. Resultados de las pruebas y validación de la base de datos CVC-09. Precisión media promedio (mAP) y procesamiento de imágenes por segundo (fps)
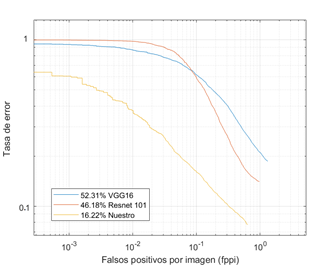
Figura 7. Curvas de las tasas de error promedio versus FPPI para las distintas arquitecturas de red Faster R-CNN sobre la combinación de los conjuntos de prueba de las bases de datos CVC-09 y LSIFIR.
Tabla 7. Comparación tasas de error promedio de sistemasde detección de peatones en la noche bajo las bases de datosCVC-09 y LSIFIR
Así se puede observar en la Figura 7 que se ha superado los resultados de los modelos originales de Faster R-CNN y otros modelos presentados por otras investigaciones, como se detalla en la Tabla 7.
Tiempo de procesamiento
Para la evaluación experimental se usó un equipo compuesto por una GPU con el sistema operativo Linux 16.04, una tarjeta Nvidia Geforce GTX 1080 Ti, con 11 GB GDDR5X 352 bit de memoria. El tiempo de entrenamiento fue de 5 horas aproximadamente. El tiempo promedio de detección es de 170 milisegundos, sobre imágenes de 640×480 píxeles; es decir, el sistema procesa 5 imágenes por segundo.

Conclusiones y recomendaciones
Conclusiones
En este trabajo se ha presentado un método de detección de peatones en la noche usando modernas técnicas de inteligencia artificial, donde se realizaron los siguientes aportes:
Desarrollar una nueva arquitectura DL basada en Faster R-CNN junto con el modelo VGG16 para la detección de peatones en la noche usando imágenes en el infrarrojo lejano. La red RPN de múltiples escalas presentó una mejor detección específicamente para peatones a larga distancia. En comparación con la arquitectura original de RPN, la arquitectura de RPNCD y RPNLD produjo mejores resultados, la nueva arquitectura incrementó el mAP del 76,4 al 86 %. Adicionalmente, se presentó un aporte significativo al aplicar la deconvolución a la subred de clasificación donde, el mAP incrementó del 86 al 89,9 %. Sin embargo, la deconvolución añadida en la etapa de clasificación incrementa la carga computacional. En consecuencia, la red reduce el procesamiento de 10 fotogramas a 5 fotogramas por segundo.
Comparar el desempeño de la arquitectura original de Faster R-CNN junto con los modelos VGG16 y Resnet 101, sobre las bases de datos CVC-09 y LSIFIR, obteniéndose resultados superiores en mAP 9,7 % para Resnet 101 y 13,5 % para VGG16. En cuanto a la tasa de error promedio, se obtuvo una diferencia de 29,96 % para Resnet 101 y 36,09 % para VGG16.
Respecto a la detección, el modelo propuesto demuestra un rendimiento superior respecto a los métodos Olmeda et al.[2] y John et al.[18], donde la tasa de error promedio es reducida en un 8,88 % respecto a [2] y 49,18 % respecto a [18].
El tiempo de procesamiento es de 5 fotogramas por segundo, lo que convierte a esta propuesta en un método viable para aplicaciones en tiempo real, destinado a seguridad vehicular.

