











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
En la literatura existente, se tienen estudios previos relacionados con la aplicación de modelos de Machine Learning para el monitoreo y análisis de redes inalámbricas, por ejemplo en Casas (2018), se indica que debido a la gran dimensionalidad de los datos que pueden ser recolectados de la red, se concluye que la aplicación de las técnicas del Machine Learning es útil para su análisis.
En Casas (2018), se comparan diferentes modelos de Machine Learning para el análisis de las mediciones de tráfico real de la red celular con la finalidad de detectar anomalías generadas por las aplicaciones que se ejecutan en los smartphones y para la predicción de la QoE (Quality of Experience) para algunas aplicaciones populares. Los resultados de dicho trabajo indican que los modelos basados en los árboles de decisión son los más precisos en el problema planteado y que los modelos colaborativos, como los de stacking, son capaces de incrementar significativamente el desempeño y la robustez de los análisis.
El monitoreo, la evaluación y la predicción de la calidad de experiencia en las redes de comunicaciones móviles también es un problema actual y que tiene por finalidad establecer los niveles de calidad con respecto a la provisión de los servicios. En Casas et al. (2017), este problema se lo evidencia mediante mediciones de QoS (Quality of Service) con el uso de terminales de usuario y mediante retroalimentaciones de los usuarios. Con base en las mediciones realizadas con los dispositivos de usuario y la aplicación de múltiples técnicas de Machine Learning supervisado, se logra predecir el QoE experimentado por los usuarios en aplicaciones populares como YouTube y Facebook. De los resultados obtenidos se indica que el modelo propuesto basado en árboles de decisión es capaz de predecir con una exactitud de 91 % el QoE y con un 98 % la aceptabilidad del servicio.
En Lupera-Morillo y Parra (2020), se realizó el estudio de la propagación de las señales en un ambiente específico como lo son los túneles del metro de la ciudad de Quito. En este estudio, mediante la simulación de la propagación de las señales utilizando el modelo de trazado de rayos, se llegó a determinar que las condiciones de propagación influyen en los parámetros de cobertura que se reflejan en el perfil de retardo de potencia y en el mapa de calor de la intensidad de la señal recibida. Es por esto que se debe corroborar lo obtenido en la simulación con mediciones de campo en ambientes específicos y cuyos datos recolectados deben ser detenidamente analizados con las técnicas modernas actualmente disponibles con la finalidad de detectar ciertos comportamientos como que las paredes y la polarización de la onda tienen una influencia en la propagación de la señal de radio o que existe diferencia en los coeficientes de reflexión en las paredes del túnel en las secciones donde no hay curvaturas.
En el trabajo de Masri et al. (2021), mediante técnicas de Machine Learning se establece el tiempo y el destino óptimo para el proceso de handover en una red 5G (Quinta Generación). Además, se menciona que el modelo aprendido se utiliza para la ejecución del handover con base en las condiciones de radio que se predicen. Esta propuesta se evaluó en simulación mediante las métricas de desempeño del sistema.
Asimismo, en Quistial et al. (2018) se realizaron mediciones de campo en la ciudad de Quito de los parámetros de cobertura en la banda de 900 MHz y se concluyó que los datos obtenidos no se ajustan de manera exacta con los modelos conocidos de propagación debido a las particularidades existentes en este territorio, fundamentalmente en lo relacionado con el tipo de suelo, la estructura física y los materiales utilizados en la construcción de las edificaciones y a las condiciones ambientales, tipográficas y geográficas de la ciudad de Quito. Es por esto que para realizar un análisis de los parámetros de calidad y cobertura de las redes de comunicaciones móviles es necesario efectuar mediciones de campo en el lugar de interés para contar con datos reales a procesar y los cuales se ajustan a la realidad de la zona que se está analizando.
En Boucetta et al. (2021), se estudia la calidad de los enlaces en redes IoT (Internet Of Things) con base en el análisis de los parámetros de la intensidad de la señal recibida y de la tasa de errores en la transmisión. En este estudio, se trata de determinar las propiedades temporales de dichos parámetros para seleccionar los canales apropiados para aplicaciones críticas y mejorar la QoS de la red. Para esto, se aplican técnicas de Machine Learning a un conjunto de datos reales recolectados en Francia.
Actualmente, de acuerdo con Almeida et al. (2019) se ha propuesto utilizar los UAVs (Unmanned Aerial Vehicle) como puntos de acceso Wi-Fi(Wireless Fidelity) o estaciones base celulares con la finalidad de utilizarlos ante situaciones emergentes de comunicaciones o para reemplazar a determinados equipos de red. Ante esta situación, se ha propuesto estimar la QoS para dicha red mediante la aplicación de técnicas de Machine Learning basadas en redes neuronales convolucionales. En la investigación mencionada se consideran los siguientes parámetros: posición del UAV, ubicaciones de los usuarios y sus tráficos ofrecidos. De acuerdo con los investigadores, el método propuesto provee estimaciones rápidas y exactas con una complejidad computacional reducida.
Tomando en cuenta que la etapa de recolección de datos es fundamental y será un factor determinante para la obtención de resultados válidos, se han propuesto consideraciones para la ejecución de esta actividad y que se encuentran disponibles en la literatura. Por ejemplo, en Scott y Frobenius (2008) se proporciona una revisión de los principios y terminología básicos de parámetros de radiofrecuencia para teléfonos móviles y sistemas de datos inalámbricos. Mientras que Foegelle (2018) analiza los últimos avances en la forma de realizar pruebas de radiofrecuencia de 5G según la 3GPP (3rd Generation Partnership Project: Proyecto Asociación de Tercera Generación).
Por otra parte, se debe mencionar que existen metodologías de creación de modelos basados en aprendizaje automático, como los presentados en Mahmoud e Ismail (2007) que presenta una revisión del uso del aprendizaje automático en la gestión de datos, la seguridad o mejora de procesos operativos en las telecomunicaciones. También Singh et al. (2016) y Choudhary y Gianey (2017) presentan un análisis detallado de los algoritmos de aprendizaje automático supervisado respecto a la eficiencia de cada uno y su aplicación.
En la literatura no existe un modelo predictivo de zonas de handover y zonas de handover fallidos que se base en mediciones de campo de redes celulares operativas y técnicas de Machine Learning, lo cual se trata de abordar de una manera inicial en este artículo. Además, se puede mencionar que los resultados obtenidos serán el punto de partida para proponer metodologías que permitan mejorar los procesos de handover.
Este artículo se encuentra estructurado de la siguiente manera: en la sección II se describen los principales conceptos de Machine Learning, la técnica de los árboles de decisión y el proceso de handover. En la sección III se describe la creación del DataSet, el preprocesamiento de los datos, la creación del modelo y la evaluación de este. En la sección IV se presentan los resultados obtenidos de la aplicación de la técnica de los árboles de decisión sobre los datos recolectados. Finalmente, en la sección V se presentan las conclusiones obtenidas.
MARCO TEÓRICO
Machine Learning
En las últimas décadas, el aprendizaje de máquina ha sido una gran herramienta para trabajar con grandes cantidades de datos, realizar análisis, estudios y posteriores modelos que ayuden a predecir el comportamiento de cualquier tipo de variable con base en un número determinado de variables que se deseen comparar. El Machine Learning ha sido aplicado en diferentes campos de las ciencias humanas y tecnológicas a lo largo del tiempo, dentro de las que se destacan la aplicación en medicina, desarrollo tecnológico, educación, construcción, finanzas, telecomunicaciones, entre otras, como lo presenta Choudhary y Gianey (2017).
Se pueden mencionar tres tipos de Machine Learning principales utilizados para alcanzar un aprendizaje autónomo de máquina, que se han aplicado en los sistemas de telecomunicaciones, y estos son: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo Mahmoud y Ismail (2007). El aprendizaje supervisado se caracteriza por un aprendizaje basado en etiquetas que se proveen con los datos de entrada, el aprendizaje no supervisado por su parte realiza aprendizaje sin etiquetas, basándose en el comportamiento de los datos, mientras que el aprendizaje por refuerzo utiliza un sistema de estado y recompensas para retroalimentar el proceso de aprendizaje. Cada uno de estos tipos se aplica de acuerdo al caso de estudio y utilizan diferentes técnicas o algoritmos para su implementación. Por ejemplo, en este trabajo se utilizó aprendizaje supervisado usando la técnica de árboles de decisión.
Técnica de Árbol de decisión
De la revisión bibliográfica realizada, se observa que existen algoritmos o técnicas para implementar modelos de predicción usando Machine Learning, como árboles de decisión, que se caracterizan por ser fáciles de comprender y el análisis de resultados es sencillo.
Para la obtención de los modelos con árboles de decisión, al ser un aprendizaje supervisado, se requiere de una cierta cantidad de datos etiquetados de la variable que se desea predecir Singh et al. (2016). Además, esta técnica se caracteriza porque mientras mayor sea el conjunto de datos etiquetados, el aprendizaje del algoritmo será mejor. Al conjunto de datos para la generación del modelo se lo denomina de entrenamiento y, por lo general, se utiliza alrededor del ochenta por ciento del conjunto de datos total, mientras que el restante veinte por ciento se utiliza como test para definir la confiabilidad del modelo Singh et al. (2016). La finalidad de la creación del modelo en este proyecto es que en un futuro se pueda ingresar otro DataSet sin la necesidad de que estos estén etiquetados, para que el modelo pueda predecir si la zona de donde se tomaron los datos (mediciones) es susceptible a handover o no y si dicha zona tiene algún nivel de probabilidad de que se produzcan handover fallidos.
Los árboles de decisión es uno de los métodos del aprendizaje supervisado, considerado como un algoritmo de clasificación, en donde es posible obtener una función de salida de valores discretos Singh et al. (2016), Choudhary y Gianey (2017). Este método se caracteriza porque su análisis e interpretación es muy simple, ya que comúnmente se lo asocia con un diagrama de flujo, aunque presenta varias diferencias. Un ejemplo bastante difundido de este método es la predicción de la ejecución o no de una actividad con base en ciertas condiciones de entrada.
En el árbol de decisión se observa una raíz que corresponde al nivel más alto, del cual empiezan a nacer ramas de criterios diferenciados, estas a su vez de ser necesario entregan valores discretos con base en la variable que se está analizando.
Handover en redes LTE
El proceso de handover permite mantener la conexión entre la red y el terminal móvil cuando por el movimiento del terminal existe un traspaso de la conexión de una estación base a otra. Este proceso tiene sus particularidades cuando el terminal se encuentra en el modo inactivo (idle mode) durante el cual el teléfono se encuentra con una conexión a la red pero sin la transmisión de datos de usuario; o, en el modo conectado (connected mode) durante el cual el usuario utiliza alguno de los servicios de la red. El proceso de handover es controlado por la red y asistido por el UE (User Equipment), y se basa en mediciones realizadas por el UE de intensidad de señal y calidad de señales de referencia específicas del enlace de bajada tanto de la S-BS (Server-Base Station) como también de las estaciones base vecinas Tayyab et al. (2019).
En Tayyab et al. (2019), se definen diferentes tipos de handover, los handover intra e inter-frecuencia que se tienen cuando la S-BS y la estación T-BS (Target-Base Station) operan en la misma o en diferente frecuencia de portadora, respectivamente. Los handover también pueden ser del tipo intra-capa celular; es decir, traspasos entre un mismo tipo de celda, en este caso, se consideran las macroceldas. En cambio, cuando este proceso se ejecuta entre celdas de la misma tecnología y en la red de un mismo operador, se denomina handover intra-tecnología celular e intra-operador.
METODOLOGÍA
La metodología de este trabajo consiste en lo siguiente: creación del DataSet que incluye la definición de los parámetros a medir, identificación de las zonas de estudio y recolección de datos; preprocesamiento de los datos extrayendo las características de estos y creando un set de entrenamiento y test; creación del modelo de Machine Learning para la obtención del modelo; y evaluación con los datos de test para validar los resultados obtenidos.
Creación DataSet
Mediciones del UE
Las mediciones de los parámetros de radiofrecuencia se realizan con la finalidad de recolectar datos del proceso de handover en dos escenarios; el primero en el modo inactivo y el segundo en el modo conectado.
Existen varios parámetros que se pueden obtener desde el dispositivo móvil; la cantidad y el tipo de parámetros medidos dependen de la aplicación que se utilice. Las herramientas de medición de los parámetros de RF presentan las mediciones a partir de las funciones que el sistema operativo ofrece. En este estudio para la recolección de los datos se han utilizado UEs de características similares que disponen del sistema operativo Android y las herramientas utilizadas son: CellMapper para el registro de las estaciones base localizadas en el sector de estudio, NetMonitor Cell Signal Logging que presenta las medidas de los parámetros de RF, GPS Logger para el registro de eventos específicos y Force LTE para forzar una conexión LTE permanente en el UE. Todas las herramientas se encuentran disponibles en la Play Store de Google en los celulares Android.
Se consideraron parámetros específicos relacionados con el proceso de handover y además parámetros generales de RF, entre ellos:
RSSI (Received Signal Strength Indicator). El indicador de intensidad de la señal recibida corresponde a un valor de la potencia de una señal recibida por un dispositivo que incluye el ruido y la interferencia (Tayyab et al., 2019). Comúnmente, se lo utiliza para evaluar la potencia de las celdas en una zona determinada; sin embargo, resulta insuficiente para explicar todos los problemas que se pueden dar en una red celular, ya que su valor no necesariamente está relacionado con la velocidad de transmisión y en general con la calidad de la conexión.
RSRQ (Reference Signal Received Quality). La Señal de referencia Calidad recibida es un indicador que se utiliza para describir la calidad de la señal en una zona determinada como se muestra en la Ecuación 1 (Tayyab et al., 2019):
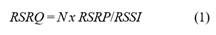
Donde N es el número de Resource Block transmitidos, que corresponde a la unidad más pequeña de información que se transmite; y, RSRP (Reference Signal Received Power) es el valor de potencia recibida promedio sin las componentes de interferencia y ruido Tayyab et al. (2019).
RSSNR (Reference Signal Signal to Noise Ratio). La señal de referencia Relación señal/ruido es una medida de la potencia de la señal deseada respecto al ruido, que describe el estado de la señal de acuerdo a las condiciones del medio Tayyab et al. (2019).
Zonas de estudio
Se escogieron diferentes zonas para cada uno de los escenarios propuestos. La primera zona para el análisis del handover en el modo inactivo corresponde a un sector urbano de la ciudad de Quito, ya que se requiere de una zona en donde se produzca una gran cantidad de handovers. Por otra parte, la segunda zona que se emplea para el análisis del handover en el modo conectado corresponde a un sector rural de la ciudad de Quito, porque se requiere de una zona en donde exista alta probabilidad de que se produzcan fallas en el handover que se reflejan como interrupciones o distorsiones en la conexión. El tipo de conexión que se estableció en el segundo escenario es una conexión de VoIP (Voice Over Internet Protocol).
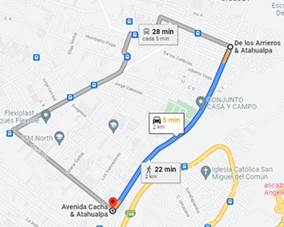
Zona 1 en modo inactivo: La recolección de datos de los parámetros de RF en esta zona se realiza con la ejecución de recorridos en tres rutas. La primera ruta se presenta en la Figura 1 que se caracteriza por ser una de las principales vías de tránsito del sector. Es una ruta que tiene una longitud aproximada de 2 Km y en la cual se presentan varios procesos de handover.
La segunda ruta considerada y que se presenta en la Figura 2 tiene una longitud aproximada de 2.2 Km en donde se presentan conexiones con varias BS. Esta ruta se trata de una vía medianamente transitada.
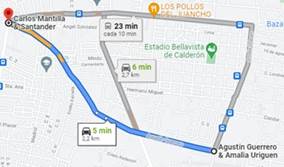
Figura 2 Trayecto de la segunda ruta para la recolección de datos en el modo inactivo, tomado de Google Maps
En cambio, la tercera ruta, que tiene una longitud aproximada de 1.7 kilómetros, se muestra en la Figura 3 y corresponde a una vía principal de conexión de alto tránsito en una zona comercial.
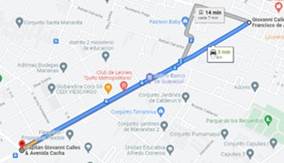
Figura 3 Trayecto de la tercera ruta para la recolección de datos en el modo inactivo, tomado de Google Maps
Zona 2 en modo conectado: Como se indicó, la recolección de datos en el modo conectado se realiza en una zona rural que presenta un flujo vehicular de alta velocidad. La zona que se puede visualizar en la Figura 4 se seleccionó, ya que es un lugar donde se presentan problemas en el proceso de handover con interrupciones o distorsiones en la conexión. Durante el proceso de recolección de datos se detectaron estos problemas y fueron registrados. Las rutas que se recorrieron en esta zona se pueden visualizar en la misma figura que tienen longitudes de 1.39, 2.48, 1.86, y 2.23 Km.
Para los dos escenarios, el modo inactivo y conectado, se recolectaron los datos tomando en cuenta los objetivos del aprendizaje, tomando los parámetros de la Tabla 1.

En el escenario 1 con modo inactivo, se recolectaron 25 830 muestras; en cambio, para el escenario 2 para el modo conectado se inició con 17 199 muestras que permitieron generar un DataSet único para cada escenario.
Preprocesamiento de datos
Para la obtención del modelo se realiza un preprocesamiento de los DataSets generados, donde se filtran las variables de interés, se eliminan los datos erróneos y se incluye variables adicionales para el aprendizaje. Dentro de las variables adicionales se agregó una variable para identificar los puntos geográficos donde se producen los procesos de handover y se crearon las variables que fueron las etiquetas para el aprendizaje supervisado con la técnica de árbol de decisión como son: si existe handover para el modo inactivo (escenario 1) y si existe falla en el handover en el modo conectado (escenario 2). Además, dentro de este paso se dividió cada DataSet en dos partes para la posterior evaluación del modelo creado. De esta manera se consideró el 80 % del DataSet para el proceso de entrenamiento y creación del modelo y 20 % para la evaluación del modelo entrenado.
Creación del modelo de Machine Learning
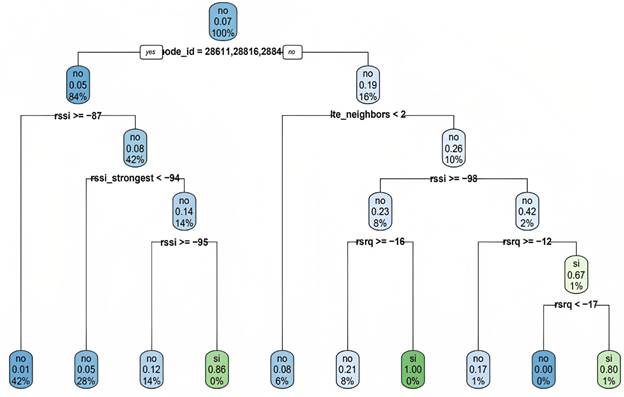
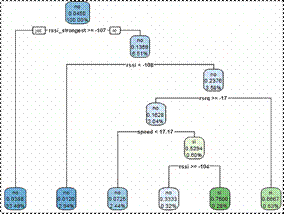
Una vez que se dispone del set de entrenamiento se procede a la creación del modelo de cada escenario con la técnica de árboles de decisión usando la herramienta RStudio. Dentro de la creación del modelo se inicia definiendo la tarea del aprendizaje para cada escenario. En el escenario 1, se busca identificar las condiciones donde se produce un proceso de handover mientras que el escenario 2 busca encontrar las condiciones donde se producen fallas en el handover. A continuación, dentro de RStudio se definen las variables de entrada y la variable con la etiqueta para la clasificación de que si existe o no handover o falla en el handover de acuerdo al escenario. Finalmente, se obtiene el modelo con la técnica árbol de decisión de manera gráfica, donde se presenta el comportamiento de los datos basándose en el set de entrenamiento y la variable para la clasificación, de esta manera se definen las condiciones para que se produzca el handover o falla de handover según el escenario. Los árboles de decisión obtenidos como ejemplo para el escenario 1 en modo inactivo y el escenario 2 con modo conectado se muestran en las Figuras 5 y 6, respectivamente.
Evaluación del modelo de Machine Learning
Para evaluar el modelo de Machine Learning obtenido se consideró el set de test reservado en el preprocesamiento de los datos y el modelo resultante de la aplicación de la técnica de árbol de decisión. De esta manera, se comparó el comportamiento de la variable definida como etiqueta de manera real y usando el modelo, mediante la realización de varias pruebas con la finalidad de obtener un modelo que alcance un mejor desempeño y que no presente una complejidad alta.
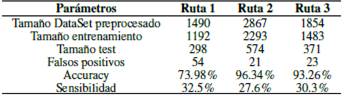
Para el escenario 1 se obtuvo la matriz de confusión para cada una de las rutas que permite identificar el número de falsos positivos del modelo como lo muestra la Figura 7.
Además, se analizaron algunos hiperparámetros para evaluar los modelos determinando los mejores resultados en la Tabla 2.
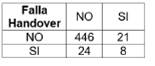
Mientras que para el escenario 2, se obtuvo la matriz de confusión de la Figura 8 donde de la misma manera se puede comprobar la precisión de los datos obtenidos con el modelo creado.
Como se observa, se tienen 24 falsos positivos de una DataSet pre procesado de 2495 muestras, con 1196 muestras de entrenamiento, 499 muestras de test y un accuracy de 95.5 %.

4. RESULTADOS
Del análisis de los conjuntos de datos recolectados se encontró que a pesar de haber depurado el conjunto de muestras, se tiene un desbalance entre la cantidad de datos de los puntos donde no existen procesos de handover con respecto a la cantidad de datos que se tiene en los puntos en lo que sí existe dicho proceso. Adicionalmente, se debe mencionar que ciertos parámetros que fueron considerados en el conjunto de datos no aparecen en los árboles de decisión porque su impacto no es relevante en la definición de las reglas establecidas en los modelos.
El modelo ejemplo obtenido mediante el árbol de decisión para el escenario 1 en el modo inactivo presenta las características de las zonas de cobertura normal de una estación base (sin handover) y de sus zonas de handover. Las principales condiciones que se pueden destacar y se obtienen del árbol son las siguientes:
La zona de cobertura normal de una estación base se tiene en un sector donde el RSSI es mayor a -87 dBm independientemente de los valores de otros parámetros de RF.
Existe una alta probabilidad de que la zona de cobertura normal presente un RSSI menor a -87 dBm y mayor o igual a -95 dBm y el RSSI_strongest mayor o igual a -94 dBm.
Existe gran probabilidad de que en la zona de cobertura normal de una estación base se presenten un RSSI menor a -87 dBm y el RSSI_strongest menor a -94 dBm.
Es posible que en una zona normal de cobertura de una estación base la cantidad de lte_neighbors sea de 1 o 0.
Existe una probabilidad importante de que en una zona de handover el lte_neighbors sea mayor o igual a 2, el RSSI tenga un valor mayor o igual a -98 dBm y el RSRQ sea menor a -16 dB.
De igual manera, se debe mencionar que en una zona de handover es probable que el lte_neighbors sea mayor o igual a 2, el RSSI sea menor a -98 dBm y el RSRQ se encuentre entre los valores de -12 dB y -17 dB.
Al analizar el árbol de decisión del escenario 2, que corresponde al modo conectado, se presentan las siguientes condiciones:
Existe una alta probabilidad de que no existan problemas en el proceso de handover si el RSSI_strongest es mayor o igual que -107 dBm sin importar las condiciones de los otros parámetros considerados
Existe una alta probabilidad de que no existan problemas de handover cuando el RSSI_strongest es menor que -107 dBm, el RSSI es mayor que -108 dBm, con un RSRQ mayor o igual a -17 dB y una velocidad de movimiento menor a 17.17 m/s.
Se debe considerar las zonas en donde se presenta que el RSSI_strongest es menor que -107 dBm, el RSSI es mayor que -108 dBm y menor a -104 dBm, con un RSRQ mayor o igual a -17 dB y se puede alcanzar una velocidad de movimiento mayor o igual a 17.17 m/s, ya que existe la posibilidad de que se produzcan problemas en el handover en dichas zonas.
Finalmente, existe probabilidad de que se tengan problemas de handover en las zonas en donde el RSSI_strongest es menor que -107 dBm, el RSSI es mayor que -108 dBm y un RSRQ menor a -17 dB.
De las condiciones establecidas, se puede mencionar que las zonas de handover se caracterizan por la cantidad de BS vecinas presentes, la intensidad de la señal de la S-BS y se observa que depende de una cantidad específica de ruido e interferencia existente.
Por otra parte, las zonas de problemas de handover presentan dependencia simultánea de determinados valores de la intensidad de la señal de la T-BS y de la S-BS, de determinados valores de ruido e interferencia y se caracterizan porque dichas zonas se manifiestan cuando el UE se mueve a una velocidad determinada. Estas zonas no dependen de parámetros como la cantidad de BS vecinas, como se esperaría, o de otros parámetros considerados en el análisis.
5. CONCLUSIONES
En este artículo se presenta un método para analizar el comportamiento de los parámetros de RF y de aquellos relacionados directamente con el proceso de handover. Los análisis permiten obtener un modelo predictivo de las zonas de handover y de aquellas zonas de ocurrencia de problemas en el proceso handover; es decir, que si se cuenta con un conjunto de datos de mediciones de campo de parámetros de una red LTE en una zona determinada, es posible predecir si dichas zonas tienen algún nivel de probabilidad de ser zonas de ejecución de handover y de ocurrencia de problemas en dicho proceso.
Es pertinente mencionar que la originalidad y novedad de lo presentado en este artículo se basa en un análisis minucioso de los parámetros de RF medidos en la ciudad de Quito mediante técnicas de Machine Learning con la finalidad de identificar patrones de comportamiento de los parámetros en las redes de comunicaciones móviles que permitan identificar manifestaciones de la ocurrencia del proceso de handover o de problemas en su ejecución. Consecuentemente, y mediante un análisis detenido de dichas zonas, se podrían identificar causas y razones que permitan proponer medidas para mejorar la calidad en la prestación de los servicios. Esto es diferente a lo realizado en trabajos similares, como en Casas (2018) y Casas et al. (2017), en donde se evalúan y predicen los niveles de calidad de servicio, más no la forma de detectar la degradación de la calidad de la conexión con base en mediciones. En un trabajo futuro se propone utilizar otras herramientas de recolección de datos para incorporar nuevos parámetros en el análisis. Adicionalmente, se mejorarán los procedimientos de recolección de datos y se ampliarán las condiciones de toma de las muestras para considerar otros factores influyentes, como por ejemplo, la intensidad de tráfico en la red. Además, se utilizarán técnicas diferentes de Machine Learning para mejorar el desempeño de los modelos y comparar con los resultados obtenidos en este artículo.





