











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
Particle Swarm Optimization (PSO) como método estocástico de optimización global inicia con estudios realizados por Kennedy y Eberhart (1995), quienes se fijan como objetivo inicial simular gráficamente el movimiento sincronizado e impredecible de grupos tales como los bancos de peces o las bandadas de aves, intrigados por la capacidad de estos grupos para separarse, reagruparse o encontrar alimento. Dentro de esta misma línea, con trabajos previos en el ámbito de la biología y de la sociología, que concluyen que el comportamiento, inteligencia y movimiento de estas agrupaciones, entre las cuales se podría incluir con un cierto grado de abstracción a los seres humanos, está relacionado directamente con la capacidad de los individuos para compartir información y aprovecharse de la experiencia semejante acumulada.
Kennedy y Eberhart (1995), modelan dicho comportamiento de forma matemática utilizando expresiones simples que revelan su potencial como método de optimización. En la terminología utilizada en PSO, Kennedy y Eberhart (1995, 2001) introducen el término general partícula o agente para representar a los peces, pájaros, abejas, hormigas o cualquier otro tipo de individuos que exhiban un comportamiento social como grupo, en forma de una colección de agentes que interactúan entre sí. De acuerdo con los fundamentos teóricos del método, el movimiento de cada una de estas partículas hacia un objetivo común en dos dimensiones está condicionado por dos factores básicos, la memoria autobiográfica de la partícula o nostalgia y la influencia social de todo el enjambre. A nivel computacional, como método de optimización, esta filosofía puede extenderse a un espacio N-dimensional de acuerdo con el problema bajo análisis. La posición instantánea de cada una de las partículas de la población en el espacio N-dimensional representa una solución potencial, siendo N el número de incógnitas del problema original.
Básicamente, el proceso evolutivo se reduce a mover cada partícula dentro del espacio de soluciones con una velocidad que variará de acuerdo a su velocidad actual, a la memoria de la partícula y a la información global que comparte el resto del enjambre, utilizando una función de fitness para cuantificar la calidad de cada partícula en función de la posición que ésta ocupe, más allá de la propia naturaleza del método, los esquemas existentes para la implementación son muy diversos. En la investigación realizada por Carlisle y Dozier (2001) se muestran variantes dependiendo de cómo se actualicen las posiciones de las partículas surgen las versiones síncrona y asíncrona del algoritmo. Adicionalmente, dependiendo de cómo se haga influir la experiencia acumulada por el enjambre sobre el movimiento de cada una de las partículas que lo integran, se puede distinguir entre PSO local y global, como lo indican Eberhart y Shi (2001). Son muy extensas las variantes que los propios autores e investigadores plantean, con el propósito de mejorar el rendimiento del algoritmo original en aplicaciones concretas.
Trasladando la filosofía de PSO al campo de la vida artificial y del cómputo evolutivo, entre las múltiples áreas donde ha sido aplicado con éxito, destacan por su importancia: optimización de funciones y resolución de problemas matemáticos complejos (Laskari et al., 2002), (Hu et al., 2003), optimización de pronóstico sobre algoritmos clásicos (Barba y Rodríguez, 2015), entrenamiento de redes neuronales (Ismail y Engelbrecht, 2000), (Srinivasan et al., 2003), (Eberhart, Hu, 1999), (Wang et al., 2004), optimización de sistemas dinámicos (Hu y Eberhart, 2002), (Vesterstrom y Riget, 2002), procesado de señal (Zhao y Zheng, 2004), (Lu y Yan, 2004), gestión, planificación y optimización de recursos en redes de distribución de energía eléctrica (Naka et al., 2001), (Koay y Srinivasan, 2003), (Naka et al., 2003), (Miranda y Fonseca, 2002), (Gaing, 2003), (Chang y Lu, 2002), gestión de redes de sensores (Veeramachaneni y Osadciw, 2004a), (Veeramachaneni y Osadciw, 2004b), planificación de red en servicios de telecomunicación (Yangyang et al., 2004), gestión empresarial (Tasgetiren y Liang, 2003) y teoría de juegos (Franken y Engelbrecht, 2004), entre otros.
En las aplicaciones en el ámbito de la vida artificial se deben respetar cinco principios básicos sobre la inteligencia de grupo (Kennedy y Eberhart, 1995), (Millonas, 1994), estos principios son: proximidad, calidad, diversidad de respuesta, estabilidad y adaptabilidad.
Con base en lo anteriormente expuesto, se plantea un estudio comparativo que muestra los cambios en las constantes de aceleración c 1 y c 2 en la actualización de la posición de las partículas en PSO, con lo que se resolverá un problema de estimación de costos, mediante una Red Neuronal Artificial tipo feedforward sigmoidal con aprendizaje PSO.
El documento está estructurado de la siguiente manera. La sección 2 se describe la metodología a utilizar, en la sección 3 se presentan los resultados y discusión, y en la sección 4 se muestran las conclusiones.
Metodología
En la formulación de PSO se define la velocidad de partícula como el único operador disponible para controlar la evolución de la optimización. Se considera una población de I partículas donde cada partícula del enjambre se identifica con dos variables de estado inicializadas aleatoriamente dentro del espacio N-dimensional que establece el problema a optimizar: un vector velocidad (1a) y un vector de posición (1b) que corresponde a una solución potencial al problema de optimización:
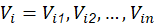
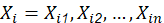
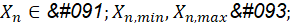
Los límites de los parámetros a optimizar (1c) conforman en su conjunto el espacio de búsqueda al cual debe restringirse el movimiento del enjambre.
Adicionalmente cada partícula mantiene en memoria información de la posición espacial asociada con la mejor solución históricamente visitada por ésta (2a) y también conoce la posición de la mejor partícula o solución encontrada por todos sus semejantes (2b). El movimiento del enjambre se realiza en pasos temporales, que se traducen a nivel de algoritmo en iteraciones contiguas.
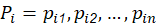
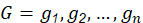
En cada iteración del método, 𝑘, cada una de las partículas de la población recorre el espacio de soluciones con una velocidad V i hacia nuevas posiciones 𝑋 𝑖 , de acuerdo con su propia experiencia 𝑃 𝑖 y con la experiencia aportada por el mejor de sus vecinos, 𝐺. En las primeras versiones del algoritmo (Kennedy y Eberhart, 1995) ésta formulación se reduce a las ecuaciones mostradas a continuación (3a) y (3b).
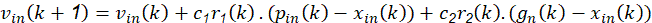
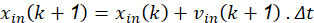
Entonces, v in (k) y x in (k) representan, la velocidad y posición en la iteración o instante de tiempo k de la partícula i en la dimensión n-ésima del espacio de búsqueda. Los factores c 1 y c 2 son las denominadas constantes de aceleración cognitiva y social, que determinan en qué medida influyen sobre el movimiento de la partícula su propia memoria y la cooperación entre individuos, respectivamente. Los términos r 1 (k) y r 2 (k) son dos números aleatorios uniformemente distribuidos entre 0 y 1, U [0,1], cuyo objetivo es emular el comportamiento estocástico y un tanto impredecible que exhibe la población del enjambre. Después de calcular la nueva velocidad de la partícula i en la dimensión n, la nueva posición x in (k+1) se actualiza directamente de acuerdo con (3b), donde se asume que la velocidad se aplica durante un cierto período de tiempo 𝛥𝑡, típicamente de valor unitario. El proceso descrito se extiende al espacio N-dimensional, de forma que se van componiendo iterativamente nuevos vectores de posición Xi, utilizando, como en cualquier otro método de cómputo evolutivo una función de fitness para ponderar la calidad de dicha solución parcial, actualizando los vectores P i y G si se detectan resultados mejores.
El movimiento de los agentes sobre el espacio de soluciones y el rendimiento del algoritmo está condicionado por el grado de contribución de las tres componentes de la velocidad en (3a) y que tienen que ver con el comportamiento social como método de optimización global: hábito o inercia, para considerar la tendencia de la partícula; memoria, nostalgia o autoaprendizaje para incluir la experiencia de la propia partícula, y cooperación, conocimiento social, conocimiento de grupo o información compartida, para reflejar el intercambio de información y el comportamiento social como grupo (Kennedy, 1997).
El procedimiento computacional completo para el algoritmo PSO se puede resumir de la siguiente manera:
Paso 1: Inicialización.
Establecer tiempo t=0 y número de partículas NP.
Genera partículas NP al azar 𝑋 𝑖 0 , 𝑖=1,2,…,𝑁𝑃 cuando 𝑋 𝑖 0 = 𝑥 ??1 0 , 𝑥 𝑖2 0 ,…, 𝑥 𝑖𝑛 0 .
Generar las velocidades iniciales para cada partícula aleatoriamente, 𝑉 𝑖 0 , 𝑖=1,2,…,𝑁𝑃 cuando 𝑉 𝑖 0 = 𝑣 𝑖1 0 , 𝑣 𝑖2 0 ,…, 𝑣 𝑖𝑛 0
Evaluar cada partícula en el enjambre usando la función objetivo 𝑓 𝑖 0 para 𝑖=1,2,…,𝑁𝑃
Para cada partícula en el enjambre, establecer 𝑃 𝑖 0 = 𝑋 𝑖 0 , cuando 𝑃 𝑖 0 = 𝑝 𝑖1 0 =𝑥 𝑖1 0 , 𝑝 𝑖2 0 =𝑥 𝑖2 0 ,…, 𝑝 𝑖𝑛 0 =𝑥 𝑖𝑛 0 junto con el mejor valor de fitness, 𝑓 𝑖 𝑝𝑏 para 𝑖=1,2,…,𝑁𝑃
Encontrar el mejor valor de fitness entre todo el enjambre, de manera que 𝑓 𝑙 min 𝑓 𝑖 0 para 𝑖=1,2,…,𝑁𝑃 con sus posiciones correspondientes 𝑋 𝑖 0 . Establecer el óptimo global a 𝐺 0 = 𝑋 𝑖 0 tal que 𝐺 0 = 𝑔 1 =𝑥 𝑙,1 , 𝑔 2 =𝑥 𝑙,2 ,…, 𝑔 𝑛 =𝑥 𝑙,𝑛 con su valor de fitness 𝑓 𝑔𝑏 = 𝑓 𝑙
Paso 2: Actualizar el contador de iteraciones
t = t +1.
Paso 3: Actualizar el peso inercial.
Paso 4: Actualizar la velocidad.
Paso 5: Actualizar posición
Paso 6: Actualizar 𝑃 𝑏𝑒𝑠𝑡
Cada partícula se evalúa mediante el uso de permutación para ver si mejora 𝑃 𝑏𝑒𝑠𝑡 , siempre que 𝑓 𝑖 𝑡 < 𝑓 𝑖 𝑝𝑏 para 𝑖=1,2,…,𝑁𝑃 entonces el mejor 𝑃 𝑏𝑒𝑠𝑡 se actualiza como: 𝑃 𝑖 𝑡 = 𝑋 𝑖 𝑡 y 𝑓 𝑖 𝑝𝑏 = 𝑓 𝑖 𝑡
Paso 7: Actualizar 𝐺 𝑏𝑒𝑠𝑡
Encuentra el valor mínimo 𝑃 𝑏𝑒𝑠𝑡
Es decir, 𝑓 𝑙 𝑡 = min 𝑓 𝑖 𝑝𝑏 , 𝑖=1,2,…,𝑁𝑃; 𝑙 ∈ 𝑖;𝑖=1,2,…,𝑁𝑃
Si 𝑓 𝑙 𝑡 < 𝑓 𝑔𝑏 , entonces el 𝐺 𝑏𝑒𝑠𝑡 es actualizado a 𝐺 𝑡 = 𝑋 𝑙 𝑡 y 𝑓 𝑔𝑏 = 𝑓 ?? 𝑡
Paso 8: Aplicar criterio de parada.
Si el número de evaluaciones de funciones excede el número máximo de evaluaciones de funciones, para: caso contrario regresa al paso 2.
El modelo de estimación de Redes Neuronales Artificiales tiene una estructura común de tres capas (Freeman y Skapura, 1991); las entradas son peso, tipo de soldadura y diámetro; en la capa oculta se aplica la función de transferencia sigmoidea, y en la capa de salida se obtiene el valor estimado. El resultado de ANN es:
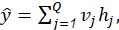
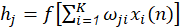
donde 𝑦 es el valor estimado (4a), Q es el número de nodos ocultos, 𝑣 𝑗 y 𝜔 𝑗𝑖 son los pesos lineales y no lineales de las conexiones ANN, respectivamente, 𝑥 𝑖 representa i ésima variable de entrada (4b). La expresión analítica de la función de transferencia sigmoidea (5) es:
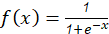
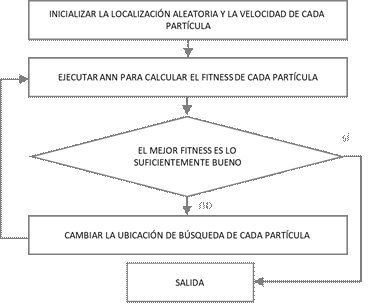
El peso de las conexiones ANN, 𝑣 y 𝜔 se ajustan con el algoritmo de aprendizaje PSO. En la Fig. 1 se ilustra la integración de la ANN con PSO. Se inicializa el enjambre de partículas con un tamaño determinado. Se calcula la función de costo (MSE descrita más adelante), correspondiente a cada peso de las conexiones de la ANN.
Cuando el mejor desempeño es alcanzado, en este caso el Error Mínimo, el algoritmo finaliza; caso contrario se realiza una nueva búsqueda de posición para cada partícula. Figura 1
Existen diferentes métricas para evaluar el rendimiento de la ANN, en este trabajo se calculan la Raíz Cuadrada del Error Cuadrático Medio (RMSE) (6a), Error Cuadrático Medio (MSE) (6b) y el Coeficiente de Determinación (R 2 ) (6c), como se muestra a continuación,
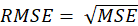
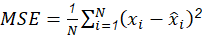
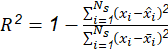
Donde, a partir de la muestra de validación, 𝑥 𝑖 es el i-ésimo valor observado, 𝑥 𝑖 es el i-ésimo valor estimado, 𝑥 es la media del valor observado, y N es el número de muestras.
Resultados y Discusión
En la aplicación empírica, una ANN feedforward sigmoidal es implementada para evaluar el algoritmo PSO. La ANN es utilizada en este caso para la estimación de costos de construcción industrial.
Para este estudio se utilizaron 2.253 datos de un fabricante real de elementos de tubería para transferencia de fluidos en operaciones de minería a gran escala (Rodríguez y Durán, 2013). La base de datos incluye un conjunto de 6 variables de entrada y 1 de salida. Las variables significativas fueron identificadas por medio de un análisis de correlación entre las entradas y las salidas, en este caso son, peso, tipo de soldadura y diámetro.
El conjunto de datos se divide en dos partes: un conjunto de datos de entrenamiento (con el 75%) y un conjunto de datos de prueba con el restante 25%.
El éxito del algoritmo radica en su capacidad de ajustar las posiciones de las partículas en un área del espacio de soluciones prometedora, de acuerdo a una función objetivo que se desea minimizar, en este caso el Error Cuadrático Medio (MSE).
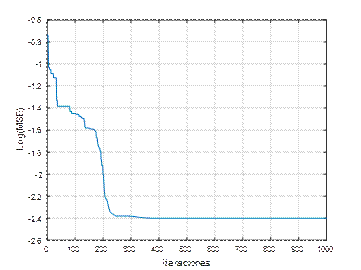
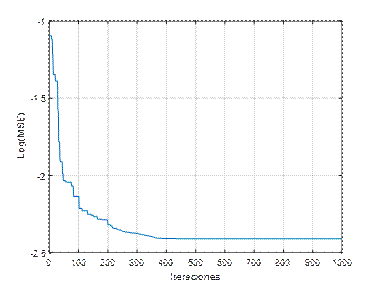
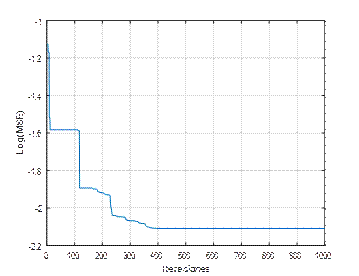
En la figura 2 se muestran los resultados del desempeño de una ANN (3,5,1), de la función de costo Error Cuadrático Medio (Mean Squared Error, MSE), y coeficientes de aceleración, c 1 =0.05, c 2 =0.05. A partir de la figura, se observa que con más de 200 repeticiones el algoritmo converge en el mínimo. En la figura 3 se han variado los coeficientes a c 1 =0.2, c 2 =0.2, como resultado se observa que el algoritmo logra el mínimo con alrededor de 400 repeticiones. Mientras que en la figura 4, se ilustran los resultados con los parámetros c 1 =0.5, c 2 =0.5, la función converge en más de 300 iteraciones. En la figura 5, se presentan los resultados con los parámetros c 1 =0.95, c 2 =0.05, la función converge en 400 iteraciones, al igual que en la figura 6, la que usa c 1 =0.05, c 2 =0.95. En la figura 7 se presentan los resultados con los parámetros c 1 =0.95, c 2 =0.95, la función converge en menos de 400 iteraciones.
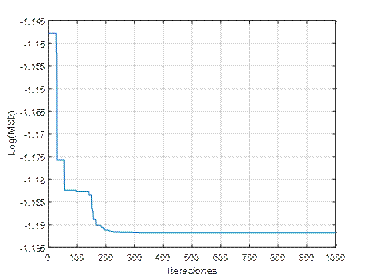
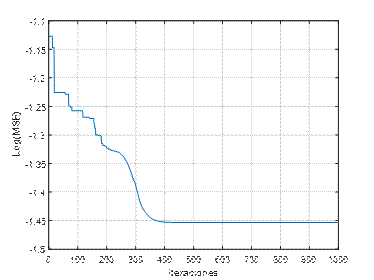
Los resultados de las métricas aplicadas para evaluar la exactitud de la estimación por medio de la ANN-PSO se muestran en la tabla 1. El experimento se repitió 3 veces usando la misma configuración. A partir de los resultados se puede observar que valores muy pequeños de c 1 y c 2 (cercanos a cero) obtienen baja exactitud en la estimación de costos de fabricación de tubería, en tanto que la mejor exactitud es lograda por medio de una ANN cuyos coeficientes de aceleración son mayores o iguales a 0.5.
Los resultados presentados en la tabla guardan relación con las aseveraciones de Duarte y Quiroga (2010), quienes determinan que los dos coeficientes de aceleración cercanos a cero producirán una búsqueda fina en una región, mientras coeficientes cercanos a uno permitirán a la partícula la posibilidad de sobrepasar al 𝐺 𝑏𝑒𝑠𝑡 y al 𝑃 𝑏𝑒𝑠𝑡 resultando en una búsqueda amplia.
Los valores obtenidos en las métricas RMSE y R 2 en el presente experimento, no difieren en mayor medida de los obtenidos por medio de un modelo neuronal más complejo basado en una ANN recurrente usada por Barba y Bodero (2017) para la estimación de costos de tuberías que aplica los mismos datos.
Las condiciones de término comúnmente usadas para finalizar el proceso de optimización son:
Número máximo de iteraciones: El proceso termina después de alcanzar un número fijo de iteraciones.
Número de iteraciones sin mejoras: El proceso de iteración termina después que se alcanza un número fijo de iteraciones en la que no se han obtenido alguna mejora en términos de solución.
Error mínimo de la función objetivo: El error entre el valor obtenido de la función objetivo y el mejor valor de eficacia (fitness) es menor que un umbral prefijo esperado.
El mal ajuste de los parámetros puede provocar que el PSO converja a una solución en pocas iteraciones, o a una buena solución en muchas iteraciones.
A menudo, PSO puede encontrar una mala solución en pocas iteraciones (conocida como convergencia prematura), o una mala solución en muchas iteraciones.
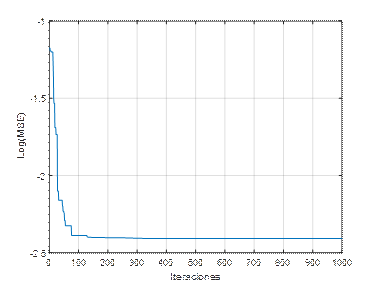
Tabla 1: Resultados de la exactitud en la estimación, a partir de diferentes valores de c 1 y c 2 .
| Repetición 1 | Repetición 2 | Repetición 3 | Promedio | |||||||
| c 1 | c 2 | RMSE | R 2 | RMSE | R 2 | RMSE | R 2 | RMSE | R 2 | |
| 0.05 | 0.05 | 0.1937 | 53.0% | 0.2209 | 38.9% | 0.2088 | 45.4% | 0.2078 | 45.8% | |
| 0.2 | 0.2 | 0.1859 | 56.8% | 0.0830 | 91.7% | 0.1595 | 74.5% | 0.1428 | 74.3% | |
| 0.5 | 0.5 | 0.0640 | 94.9% | 0.0656 | 94.6% | 0.0671 | 94.5% | 0.0655 | 94.7% | |
| 0.05 | 0.95 | 0.0615 | 95.3% | 0.0671 | 94.8% | 0.0607 | 95.4% | 0.0631 | 95.2% | |
| 0.95 | 0.05 | 0.1031 | 88.2% | 0.0985 | 89.0% | 0.0641 | 95.0% | 0.0885 | 90.7% | |
| 0.95 | 0.95 | 0.0623 | 95.1% | 0.0611 | 95.3% | 0.0610 | 95.3% | 0.0614 | 95.2% | |
| 2.95 | 2.95 | 0.0618 | 95.3% | 0.0611 | 95.4% | 0.0635 | 94.9% | 0.0621 | 95.2% | |
| 5.95 | 2.95 | 0.0612 | 95.2% | 0.0618 | 95.2% | 0.0626 | 95.3% | 0.0618 | 95.2% | |
| 5.95 | 5.95 | 0.0612 | 95.3% | 0.0773 | 95.0% | 0.0655 | 95.1% | 0.0680 | 95.1% | |
| 10 | 10 | 0.0675 | 95.3% | 0.0656 | 95.1% | 0.0626 | 95.2% | 0.0652 | 95.2% | |
Conclusiones
PSO se puede definir como un método de optimización rápido, fácil de implementar y eficaz, en el cual los parámetros a sintonizar incluyen el peso inercial, las constantes de aceleración c 1 y c 2 , el tamaño de la población y el límite superior de la velocidad v max ; sin entrar a valorar aún la influencia del tipo de topología de la población, la importancia determinante de la función de fitness o la inserción de técnicas alternativas para mitigar el riesgo de convergencia prematura inherente a PSO.
En definitiva, la formulación de PSO se reduce a caracterizar el movimiento de las partículas en base a un operador velocidad que debe aunar exploración y convergencia, descomponiendo para ello la velocidad en tres componentes en un intento por sintetizar un comportamiento social.
En este contexto los valores de los coeficientes de aceleración de PSO c 1 y c 2 juegan un papel importante dentro del modelo del algoritmo: c 1 > 0 y c 2 = 0, las partículas serán independientes; c 1 = 0 y c 2 > 0, entonces las partículas serán colectivas; c 1 = c 2 , las partículas serán atraídas por un valor promedio; c 1 > c 2 , la experiencia propia es mayor que la del grupo; c 1 < c 2 , la experiencia del grupo es mayor que la propia; si c 1 y c 2 disminuyen, las trayectorias de desplazamiento de las partículas son suaves; y si, c 1 y c 2 aumentan, entonces los movimientos de las partículas serán abruptos.
La capacidad de ajustar las posiciones de las partículas en un espacio de soluciones satisfactoria, tomando en cuenta la función objetivo a minimizar (Error Cuadrático Medio - MSE) garantizó el éxito del algoritmo del experimento.
Dentro de la fase experimental, para valores muy pequeños de c 1 y c 2 (cercanos a cero) se obtiene una baja exactitud en la estimación de costos de fabricación de tubería. Una ANN ofrece mayor exactitud con coeficientes de aceleración mayores o iguales a 0.5, como lo indican en su estudio Duarte y Quiroga (2010).
Los resultados alcanzados en las métricas RMSE R 2 en este experimento utilizando una Red Neuronal Artificial tipo feedforward sigmoidal con aprendizaje PSO no difieren significativamente de los obtenidos por medio de una ANN recurrente aplicada por Barba y Bodero (2017), para analizar los mismos datos.

