











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
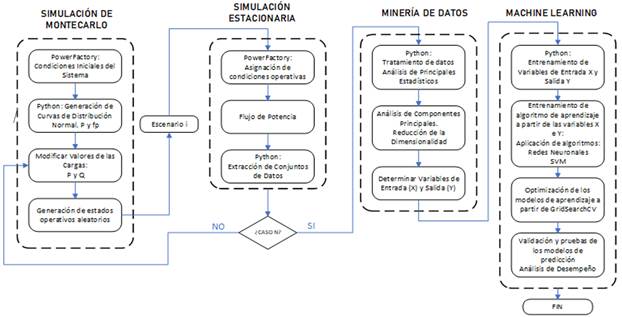
El presente trabajo está enfocado en el cálculo de los parámetros de la curva P-V tales como Potencia de Carga máxima, Voltaje en el punto de colapso, Margen de cargabilidad, Potencia y Voltaje en los Puntos de operación, basado en la técnica del Equivalente Thévenin. Para determinar los diferentes puntos de operación que permitan establecer un conjunto de datos extensos, se emplea Simulación de Montecarlo, estableciendo N condiciones operativas. Obtenido el dataset, se procede a efectuar una reducción de la dimensionalidad empleando la técnica de Feature extraction denominada Análisis de Componentes Principales, seguidamente se emplea modelos entrenados basados en técnicas de Machine Learning con sus correspondientes análisis de desempeño.
La operación de los Sistemas Eléctricos de Potencia (SEP) cerca de sus límites físicos, incurre en la presencia en ciertas perturbaciones de manera imprevista las cuales podrían causar una eventual violación de los límites de seguridad del SEP, que puede conllevar a poner en riesgo de un posible colapso total o parcial.
Entre las herramientas más utilizadas para analizar la estabilidad de voltaje en los sistemas de potencia está la determinación de las curvas Potencia-Voltaje (P-V) y de la capacidad de transferencia disponible. Con relación al desarrollo de las tecnologías de medición sincrofasorial, el uso de herramientas de monitoreo de estabilidad de voltaje en tiempo real es de gran utilidad. Entre las herramientas empleadas está la técnica del Equivalente de Thévenin, la cual permite calcular la proximidad entre el estado operativo actual y el colapso de voltaje, a través de la determinación de la curva P-V en tiempo real. Así, se puede determinar la robustez relativa del sistema de transmisión respecto de las barras de carga [1]. Asimismo, existen otros métodos de análisis de estabilidad de voltaje tales como el análisis de sensibilidad o modal del jacobiano reducido [1]. No obstante, estos métodos convencionales no realizan una predicción anticipada (alerta temprana) del punto de máxima transferencia de potencia, sino que brindan un valor único para la condición de análisis. En este sentido, el presente trabajo plantea una metodología capaz de realizar esta predicción.
La curva P-V se determinar a partir de un punto de operación dado, consecuentemente se puede establecer los valores del margen de cargabilidad considerando la capacidad de transferencia disponible. La aplicación de la técnica del Equivalente de Thévenin en un corredor de transmisión se lo realiza considerando tanto las barras de envío y como las de recepción, considerando que en cada uno de estos puntos se tiene instalado una Unidad de medición fasorial (PMU, por sus siglas en inglés). Las PMUs son dispositivos que permiten efectuar una estimación de sincrofasores de las ondas sinusoidales de corriente y voltaje AC. Sus características de alta precisión, velocidad de respuesta y sincronización de tiempo, hacen de estos equipos ideales para el monitoreo global en estado estable y dinámico. Adicional a los valores y mediciones estimadas por parte de las PMU en cada uno de los extremos del corredor de transmisión, se requiere determinar el estado operativo de todo el sistema, es decir, los valores de voltaje y corrientes de cada uno de las barras y corredores de transmisión [1] [2].
Para el análisis a efectuarse, se emplea el sistema de prueba de 39 barras disponible en DIgSILENT PowerFactory. Se consideran tres corredores de transmisión que son: Línea 4-14 (Corredor 1), Línea 21-22 (Corredor 2) y Línea 16-17 (Corredor 3). La selección de estos corredores se lo realiza a partir del criterio de cargabilidad y selección de áreas analizadas en [3].
El conjunto de datos que se obtendrá de la red de prueba de manera general está compuesto por:
Voltaje de Punto de Colapso para los corredores de transmisión seleccionados.
Potencia de carga máxima para los corredores de transmisión seleccionados.
Margen de cargabilidad para los corredores de transmisión seleccionados.
Voltaje y Potencia en el punto de operación para los corredores de transmisión seleccionados.
Voltajes y corrientes para cada una de las líneas y barras del sistema.
De esta manera, se genera un dataset de 88 variables. Por lo tanto, a partir de todo este conjunto de datos, se propone elaborar un modelo inteligente que permita determinar los valores críticos tales como del voltaje en el punto de colapso y del margen de estabilidad de los corredores de transmisión.
Para este fin, debido a la gran cantidad de información obtenida del sistema se emplea como punto de partida a lo que se denomina “Feature Extraction”, mediante estas técnicas se procederá a efectuar una reducción de la dimensionalidad del conjunto de variables. Entre las técnicas de Feature Extraction se tiene al denominado Análisis de Componentes Principales (PCA, por sus siglas en inglés), en donde primeramente se hace una identificación de las entradas y salidas del modelo a entrenarse.
Para la estimación o predicción de los valores del voltaje en el punto de colapso y del margen de estabilidad se emplean técnicas de Machine Learning, los cuales, en complemento a la reducción de la dimensionalidad obtenida, permitirán obtener modelos entrenados, que ante condiciones operativas determinadas permitirán estimar los valores críticos del sistema. Las técnicas a emplearse serán: Redes Neuronales y Máquinas de Soporte Vectorial, en su versión de regresor. Para un mejor desempeño de los modelos, se ha empleado una técnica de optimización denominada GridSearchCV, la cual permitirá establecer los mejores parámetros para cada uno de los modelos de regresión. Al tratarse de modelos entrenados, existe la necesidad de establecer parámetros que permitan tener una estimación de su rendimiento y precisión. Por lo cual, para el caso práctico del presente trabajo se ha empleado el índice Mean-Squared Error (MSE), en base al cual se realizará un análisis comparativo con cada uno de los modelos empleados.
MARCO TEÓRICO
Estabilidad de Voltaje
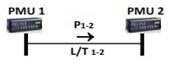
En base a la curva P-V se pueden determinar parámetros tales como los voltajes de colapso y la máxima transferencia de potencia en un corredor de transmisión a partir de un punto de operación dado, de esta manera además se pueden establecer los valores del margen de cargabilidad considerando la capacidad de transferencia disponible. Para determinar estos parámetros se emplea la técnica basada en el modelo del Equivalente de Thévenin, en donde, considerando al corredor de transmisión cuyas barras son B1 y B2 como en la Fig.1, de envío y recepción respectivamente, se puede realizar la estimación en tiempo real, considerando que en cada una de las barras se tiene instalado una PMU [1].
Fuente: [1]
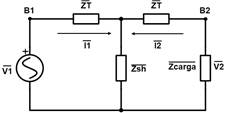
Considerando el circuito equivalente basado en el modelo “T” de la línea de transmisión de la Fig. 2, se tiene representado a la barra de envío B1 como un generador equivalente y a la barra de recepción B2 como una carga equivalente.
Fuente: [1]
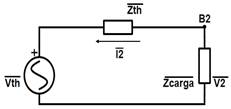
En relación al Teorema del Equivalente de Thévenin, se tiene que a un circuito eléctrico lineal se lo puede representar por un circuito equivalente, el cual está conformado por un generador de voltaje ( (V_th ) ̅) en serie con una impedancia ( (Z_th ) ̅), tal como se muestra en el circuito de la Fig. 3.
Fuente: [1]
Las expresiones que permiten la obtención del circuito equivalente de Thévenin se detallan a continuación [1] [2]:
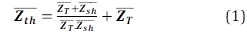
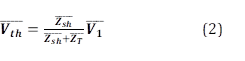
Obtenidos los parámetros del equivalente de Thévenin, se los puede emplear para la deducción de la expresión de la curva P-V, la misma que está dada por la siguiente expresión:
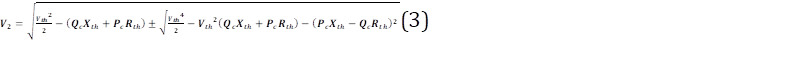
Simulación de Montecarlo
Se trata de una técnica que permite la generación de datos de forma aleatoria basados en una función de distribución conocida.
Su aplicación está enfocada en determinar situaciones en las cuales se requiere hacer una estimación y toma de decisiones a partir de variables con incertidumbre [3].
Análisis de Componentes Principales (PCA) [4] [5] [6] [7]
El análisis de componentes principales (PCA) es una técnica de minería de datos que permite reducir la dimensionalidad de los datos, manteniendo a la medida de lo posible, la variación presente en ellos. Esto se consigue mediante la transformación de los datos en un nuevo conjunto de variables, denominadas componentes principales (PCs), que no están correlacionadas, y que están ordenadas de manera que los primeros componentes conservan la mayor parte de la variación presente en las variables originales. Estas nuevas variables (zi) se determinan en base a los valores ((i) y vectores (ui) propios de la matriz de covarianza de los datos originales

La suma de los valores propios de los PCs ((i) es equivalente a la varianza total de la matriz de datos, y cada valor propio ofrece una medición de la variabilidad explicada (EVi) por el i-ésimo PC. Por lo tanto, el número de los PCs elegidos depende de la variabilidad explicada que se desee.
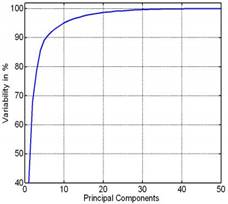
Para tener una idea de la selección del número de componentes principales, se puede también usar la gráfica de Número de Componentes Principales vs. Variabilidad Explicada. En donde, se puede observar la cantidad de información que se puede obtener de acuerdo con un número determinado de componentes principales, tal como se muestra en la Fig. 4.
Técnicas de Machine Learning
Las técnicas de Machine Learning o conocidas también de aprendizaje automático se basa en todo lo que se refiere con las ciencias de la computación, ciencia de datos y estadística. Permitiendo establecer a los algoritmos la identificación de patrones a partir de aquellos datos [8].
Entre las técnicas de aprendizaje automático que se van a emplear están:
Red Neuronal (Multi-layer Percepton)
Regresor basado en Máquinas de Soporte Vectorial (SVM)
Multi-layer Percepton (MLP) [9]
Denominado como Perceptrón Multicapa, en su traducción al español, este algoritmo es del tipo supervisado. Su aprendizaje está basado en la función:

Su entrenamiento se da en un conjunto de datos, en donde m es el número de dimensiones para la entrada y o es el número de dimensiones para la salida.
Considerando a un conjunto de características X= x 𝟏 , 𝒙 𝟐 , …, 𝒙 𝒎 y a un valor objetivo 𝒚, posee la capacidad de aprendizaje de un aproximador de función no lineal para la clasificación o regresión. En la Fig. 5 se muestra un ejemplo de un MLP de una capa oculta con salida de tipo escalar.
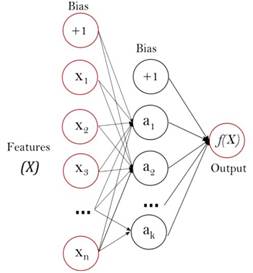
La capa que se encuentra más a la izquierda, denominada como capa de entrada, consta de un conjunto de neuronas 𝒙 𝒊 𝒙 𝟏 , 𝒙 𝟐 , …, 𝒙 𝒎 , las mismas que son la representación de las características de entrada.
La operación que efectúa cada neurona de la capa oculta consiste en la transformación de los valores de la capa anterior con una suma lineal ponderada, de la siguiente manera:

Seguidamente se determina una función de activación no lineal 𝒈 . :𝑹→𝑹−, la cual es denotada como la función de bronceado hiperbólico [10] (Fig. 6). La capa de salida recibe los valores de la última capa oculta y los transforma en valores de salida.
Fuente: [10]
Regresor basado en Máquinas de Soporte Vectorial (SVM)
La relevancia que presenta el uso de una máquina de soporte vectorial (SVM) está en la capacidad que presenta para aprender de clasificación de datos con precisión y reproducibilidad equilibradas.
La función de decisión de una SVM es un hiperplano óptimo, el cual separa (clasifica) las observaciones pertenecientes a una clase de otra en base a patrones de información sobre dichas observaciones denominadas como características. Tal hiperplano se puede usar para establecer la etiqueta más probable para los datos invisibles.
La implementación de una SVM implica el equilibrio de dos objetivos que se complementan:
Maximización del porcentaje de etiquetas correctas que se asignan a nuevos ejemplos (optimizar su precisión).
El modelo entrenado sea generalizable a nuevos datos (optimizar su reproducibilidad).
De manera general la primera característica está limitada por la importancia de los features. En cuanto a la segunda característica, se encuentra limitada por el número de ejemplos únicos utilizados para el entrenamiento del modelo [11].
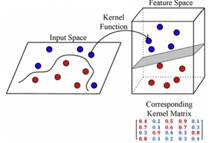
Previamente al entrenamiento del modelo, se requiere de la transformación de los datos originales de entrenamiento sin procesar a un conjunto de características que se los puede usar como entrada para la SVM. Entre los métodos empleados para este fin, se emplea al denominado “método kernel”. En donde, se usa una función kernel que representa las medidas de similitud por pares entre todos los patrones de ejemplo, las cuales se las resume en una matriz de kernel con N x N dimensiones, en donde N representa al número de observaciones.
La función de kernel permite un entrenamiento de la SVM a través de la matriz del kernel, aplicable tanto en casos lineales como no lineales, efectuando un mapeo de los datos sin procesar a un espacio de características de mayor dimensión, un ejemplo de lo detallado se muestra en la Fig. 7 [12].
Fuente: [12]
El entrenamiento de un modelo de SVM está relacionado con establecer los parámetros w y b de la función de decisión:

Esta función orienta el hiperplano, de esta manera la proyección de puntos separa al máximo los miembros de las dos clases.
Además del ajuste de los parámetros centrales (w,b), se debe de considerar como parámetros críticos a la elección de los valores de los hiperparámetros, los cuales se tratan de variables que se relacionan con el ajuste de la función de decisión y se establecen previo al inicio del entrenamiento [13].
El desempeño de la SVM se lo evalúa a partir de su sensibilidad, especificidad y precisión, estableciendo métricas e información acerca de la precisión y reproducibilidad del hiperplano SVM.
Para la evaluación conjunta de la precisión y la reproducibilidad, es necesario efectuar pruebas de permutación, de manera que el hiperplano se estima de manera iterativa mediante etiquetas de clase permutadas de manera aleatoria, considerando una ventana de valores de hiperparámetros, para varias versiones con un remuestreo del conjunto de datos [14].
PROPUESTA METODOLÓGICA
En la Fig. 11 se muestra un esquema de la metodología propuesta para el análisis predictivo de la estabilidad de voltaje. Previamente, se selecciona como red de prueba al sistema de 39 barras (New England). Considerando un corredor de transmisión por cada una de las áreas, en referencia a la Fig. 8 [15] .
Fuente: [15]
Simulación de Montecarlo
Se efectúan simulaciones iterativas, en las cuales, para cada una de las iteraciones, se varían las condiciones operativas, para el caso práctico se efectuó una variación aleatoria de todas las cargas conectadas a cada una de las barras del sistema. La variabilidad de las cargas se las obtuvo siguiendo una curva de distribución normal aleatoria, tanto para el caso de la Potencia Activa, como del valor del factor de potencia, a partir del cual se calcula la Potencia Reactiva.
En las Figuras 9 y 10 se presentan las curvas de distribución normal de la Potencia Activa de la Carga 4 y del factor de potencia, respectivamente.
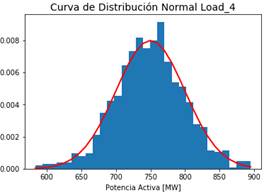
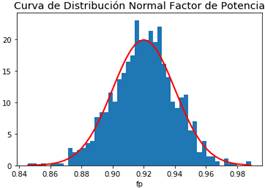
Para el caso de la potencia activa, el valor medio se lo toma del valor inicial presente en cada una de las cargas, considerando al valor de la desviación estándar en un 10% a 20% de la carga, para que exista una mayor incidencia dentro de la red, que inclusive lleve a condiciones operativas críticas. Para el caso del factor de potencia, se sigue un valor medio de 0.92 y una desviación estándar de 0.02. Teniéndose los valores de Potencia activa y factor de potencia se estima el valor de la potencia reactiva para cada una de las cargas.
Simulación de estado estacionario
Para cada una de las iteraciones dentro de la simulación de Montecarlo, se procede a efectuar el cálculo de flujos de potencia. De esta manera se obtienen los valores de Voltaje y Corriente para cada una de las barras y líneas de transmisión. Considerando que el objetivo del presente trabajo es el cálculo del equivalente Thévenin para los corredores de transmisión seleccionados y el posterior cálculo de los parámetros de la curva P-V, se efectúan dichas operaciones dentro de cada una de las iteraciones, adicionalmente se obtiene los valores de los márgenes de estabilidad.
Minería de Datos
Posterior a la generación y extracción de datos, es necesario hacer un tratamiento de estos, de manera que se pueda realizar su procesamiento y análisis.
Para este fin, inicialmente se conoce el estado de los datos, es decir que no existan ciertas inconsistencias. Además, a través del análisis estadístico se puede determinar cuan coherentes han sido los datos generados, es decir, si están dentro de los límites tanto físicos como operacionales del sistema.
En la Fig. 12, se muestra un desglose de los datos importados dentro de Python para su tratamiento.
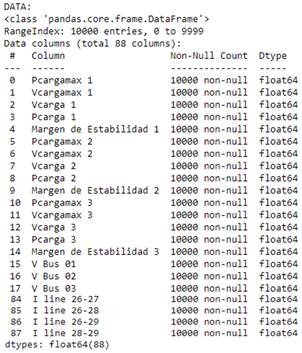
Una vez efectuado el tratamiento de datos, se procede a realizar el Análisis de Componentes Principales. Para lo cual se debe diferenciar las variables de entrada (X) y de salida (Y) que tendrán los modelos de aprendizaje y predicción. De esta manera se tiene lo siguiente:
Variables de Entrada:
Voltajes y Corrientes de las barras y líneas de transmisión del sistema.
Potencias y Voltajes en los puntos de operación obtenidos en la curva P-V para cada uno de los corredores seleccionados.
Variables de Salida:
Potencias y Voltajes en el punto de colapso obtenidas en la curva P-V para cada uno de los corredores seleccionados.
Margen de estabilidad calculado para cada uno de los corredores seleccionados.
Para la obtención de las componentes principales se emplea las variables de entrada X, siguiendo el siguiente procedimiento:
Se efectúa un escalamiento estándar de los datos y un entrenamiento de los mismos. “X=StandarScaler().fit_transform(X)”
Se obtiene la Variabilidad explicada: “pca.explained_ratio”
A partir de la Variabilidad explicada se procede a realizar el diagrama de codo, el cual relaciona a la variabilidad explicada acumulada con el número de componentes principales.
Es recomendable, en base al diagrama de codo, determinar el número de componentes principales en función a los que permitan obtener por lo menos un 90% de la información del sistema.
Determinando el número de componentes principales se procede a la obtención de las puntuaciones o “scores”, los mismos que se convertirán en la variable de entrada X a los modelos de entrenamiento.
Machine Learning
Obtenidas las variables de entrada y salida, se procede primeramente a efectuar el entrenamiento de los regresores. Para esto, se genera un subconjunto de datos de entrenamiento que se utiliza para la estimación de los parámetros del modelo, y por otra parte se genera un subconjunto de datos de test que se emplean para la comprobación del comportamiento de los modelos de aprendizaje. De manera que los valores que se generan posterior al entrenamiento son:
Subconjunto de entrenamiento: Xtrain e Ytrain.
Subconjunto test: Xtest e Ytest.
Red Neuronal MLP
Para implementar el modelo de aprendizaje basado en redes neuronales MLP se deben de establecer los siguientes parámetros [9]:
Tamaño de las capas ocultas: este parámetro representa el número de neuronas en la i-ésima capa oculta.
Función de activación: especifica la función de activación de la capa oculta. Se tienen las siguientes funciones de activación:
Identidad: ideales para implementar cuellos de botella de tipo lineal. Activación de tipo no operativa. Retorna f(x)=x.
Logística: función sigmoidea logística, retorna 𝑓 𝑥 = 1 1+ 𝑒 −𝑥 .
Tanh: función tangente hiperbólica. Retorna f(x)=tanh(x).
Relu: se trata de una función de unidad lineal rectificada. Retorna f(x)=max(0, x).
Solver: para establecer los métodos de optimización.
Lbgs: optimizador de la familia de métodos cuasi-Newtonianos.
Sgd: optimizador de gradiente descendiente estocástica.
Adam: optimizador estocástico basado en gradientes.
Alfa: parámetro de penalización (término de regularización).
Máquina de Soporte Vectorial (SVM) [16]
Los parámetros necesarios para implementar un regresor basado en máquinas de soporte vectorial son:
Kernel: similar al solver empleado en redes neuronales, se determina el algoritmo a través del cual se computará la matriz de kernel. Entre los principales están: lineal, polinomial, rbf (gaussiana), sigmoide.
C (Regularización): se trata del parámetro de penalización, el cual representa una clasificación errónea o un término de error. Este término le dice a la optimización de SVM cuánto error es soportable.
Gamma: define hasta qué punto influye en el cálculo de la línea de separación plausible.
High Gamma: solo puntos cercanos son considerados.
Low Gamma: puntos lejanos también son considerados.
Ajuste de Hiperparámetros usando GridSearchCV [17]
GridSearch se usa enfocado al ajuste de hiperparámetros los cuales construye y evalúa de manera metódica a un modelo para cada combinación de parámetros de algoritmos especificados. Permite combinar un estimador con preámbulo de búsqueda de cuadrícula para el ajuste de hiperparámetros. Por lo tanto, permite establecer los mejores parámetros a ser usados en los modelos de aprendizaje.
RESULTADOS
Se efectúa la generación de datos en PowerFactory a partir de la Simulación de Montecarlo y la Simulación de estado estacionario a partir de flujos de potencia. Este conjunto de datos se lo exporta a un archivo *.csv y posteriormente importado en el entorno de Jupyter-Python, de esta manera se tiene generado un DataFrame con 10000 filas y 88 columnas. como se muestra en la Fig. 13.
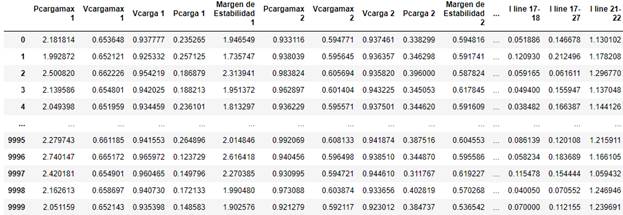
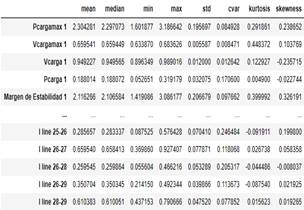
Seguidamente, se efectúa un análisis de estadística descriptiva (media, mediana desviación estándar, etc.), de la misma manera se tiene generado un DataFrame como el mostrado en la Fig. 14. A partir de los principales estadísticos de cada una de las variables del dataset, se tiene el siguiente análisis:
Relacionando los valores obtenidos entre las medias y medianas de las variables, en general, se tiene
que son valores muy cercanos, lo cual se puede interpretar de la no existencia de valores extremos.
En cuanto al valor de la desviación estándar (std), se tiene que los valores son muy bajos, por lo tanto, se produce un indicador que de que no hay una dispersión significativa de los datos.
En cuanto a los coeficientes de variación (cvar) existen casos en los cuales hay un mayor coeficiente de variación, tal es el caso de la Pcarga, Iline 25-26 e Iline 26-28, por lo tanto, sugiere que existe una mayor dispersión estas variables.
El coeficiente de Kurtosis de las variables es bajo, lo cual indica que existe una menor concentración de los datos en relación a su media, es decir la curva de distribución normal tiende a ser aplanada.
Para el caso de los coeficentes de skewness, se observa que el comportamiento de las curvas será variado, ya que existen valores positivos y negativos, no existen por lo general valores que tiendan de manera significativa a cero. Por lo tanto, los valores que tengan un coeficiente positivo tendrán su cola en el derecho, en cuanto a los coeficientes negativos tendrán sus colas al lado izquierdo. Además, en los casos en los cuales los valores tiendan a cero, su curva será casi simétrica.
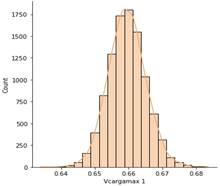
La Fig. 15 presenta el gráfico de distribución de los resultados, considerando el voltaje en el punto de colapso para el corredor 1 para tener una idea clara de su comportamiento, además de verificar las aseveraciones mostradas en el análisis estadístico. Por lo tanto, se puede verificar la asimetría de las curvas, la tendencia de las colas y la acumulación de datos entorno a la media.
Para efectuar el Análisis de Componentes Principales se parte del gráfico de diagrama de codo para determinar el número de componentes principales necesarios para tener la información suficiente del sistema. De manera que, en relación con el gráfico de la Fig. 16, se tiene:
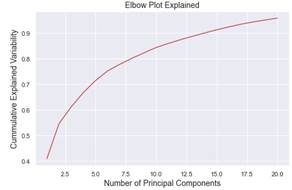
De acuerdo con el gráfico obtenido, se puede observar que con aproximadamente 14 componentes principales se puede obtener un 90% de la información, lo cual es aceptable para los fines que se buscan. De esta manera, se toman los catorce componentes principales, considerando sus "Scores" para generar la matriz X para el entrenamiento posterior.
Aplicación de Modelos Basados en Redes Neuronales
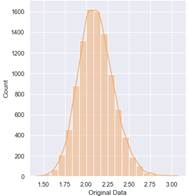
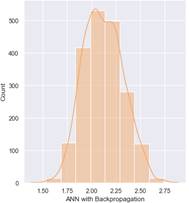
Una vez obtenidos los valores tanto de entrada como de salida, se procede a la implementación de los modelos de aprendizaje. Considerando como casos de ejemplo, los Márgenes de Estabilidad cada uno de los corredores. A continuación, se presentan histogramas que muestran la distribución de los resultados obtenidos de la predicción para cada modelo. Considerando como ejemplo a la Fig. 17, relacionada con la curva de distribución dem Margen de Estabilidad del corredor 1 dado en el dataset original.
Se puede observar que a partir de los modelos de regresión empleados permite una predicción aproximada del margen de estabilidad, considerando como referencia los valores iniciales dados por el dataset. Se aprecia que el modelo que mejor ajuste presenta es el que emplea GridSearchCV, por lo tanto, se puede verificar que ha realizado una optimización adecuada de los modelos.
Realizando una comparación de los valores de Margen de Estabilidad, caso base de la Fig. 18 y las predicciones de las Figuras 19, 20 y 21, se observa que, frente a las condiciones operativas dadas, el corredor 1 presenta un mayor Margen de estabilidad. Además, debido a la cercanía de las líneas a la apertura de la línea 16-19, tienden a tener un menor Margen de Estabilidad, muy inferior al anterior.
La condición que presenta el Corredor 1 de tener un mayor margen de estabilidad sugiere que presenta un mayor margen de estabilidad de voltaje, es decir tiende a tener menores problemas de voltaje en cuanto al incremento de parámetros tales como de las cargas, o perturbaciones de sistemas tales como de las variaciones de voltajes producidas por la apertura de líneas.
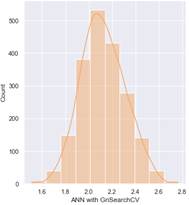
Figura 19: Predicción del Margen de Estabilidad basado en el modelo de Redes Neuronales aplicando GridSearchCV Corredor 1
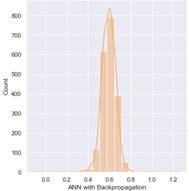
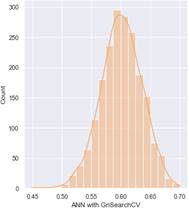
Aplicación de Modelos Basados en Máquinas de Soporte Vectorial empleando GridSearchCV
De la misma manera que en la aplicación de los modelos basados en Redes Neuronales, se emplean las variables de entrada y salida para el entrenamiento de los modelos. Como casos de ejemplos se muestran Márgenes de Estabilidad de cada uno de los corredores. Para la evaluación del desempeño de la optimización de estos modelos, se emplea los índices MSE.
Índices de Desempeño
En la Tabla 1 se detalla y se realiza una comparativa entre los índices MSE obtenidos en cada uno de los modelos aplicados a la predicción del Margen de Estabilidad de los corredores de transmisión.

Se ha considerado como indicador del desempeño de los modelos de regresión al MSE (Mean-squared-error), considerando que cuanto menor sea el valor del MSE, mayor será el ajuste del regresor, se tiene que:
Empleando GridSearchCV se tiene una mejor optimización de los parámetros de los modelos de regresión, por lo tanto, un mejor ajuste. Lo cual se puede observar, al comparar los modelos de Redes Neuronales con y sin su aplicación.
Realizando una comparación entre ANN y SVM, se tiene que el regresosr que mejores resultados se tiene es ANN con GridSearchCv, de manera que existe una mejor optimización por parte del modelo en relación al ajuste de datos obtenidos.
CONCLUSIONES Y RECOMENDACIONES
La generación del conjunto de datos a partir de simulaciones de Montecarlo permite establecer diversas condiciones operativas del sistema, a través de N simulaciones del sistema, realizando la variación de parámetros tales como de los valores de las cargas del sistema.
Es necesario dentro del análisis de datos, efectuar un análisis estadístico lo cual permita conocer el comportamiento de los datos que se han obtenido de manera preliminar.
Debido a la gran cantidad de variables que se puede obtener en el sistema, una de las herramientas que se puede usar es lo que se denomina como Feature Extraction, que a partir del Análisis PCA permite efectuar una reducción de la dimensionalidad basado en las principales características de los conjuntos de datos.
Se pudo observar dentro de la aplicación de los modelos de predicción, que el ajuste se puede optimizar a través de la herramienta de GridSearchCV, mediante el cual en base a los indicadores MSE se pudo verificar que notablemente se puede mejorar el desempeño de los modelos de regresión.
En relación a las condiciones operativas dadas en el sistema, se pudo observar que el corredor 1 presenta un mayor margen de estabilidad, por ende, menores problemas de estabilidad, a diferencia de lo que puede ocurrir en los corredores 2 y 3, que como se observó presentan valores muy inferiores.

