











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
Uno de las componentes esenciales para el desarrollo económico de un país es la electricidad, la disponibilidad de fuentes suficientes y confiables de energía a menor costo. En base a estos antecedentes, es indispensable poder determinar el comportamiento actual y futuro de la demanda eléctrica, considerando los posibles impactos producidos por variables ambientales, económicas, sociales, tecnológicas y políticas.
La exigencia en el pronóstico de la demanda eléctrica, permite a las empresas del sector eléctrico, planificar sus operaciones, identificar futuros requerimientos de infraestructura, coordinar el funcionamiento de los recursos de generación existentes, permitiendo optimizar los problemas operativos y económicos, que una mala predicción podría presentar.
En el presente trabajo se entrenaron y validaron, diferentes Modelos Ocultos de Markov (Hidden Markov Model, HMM) para el pronóstico de la demanda en horizonte de tiempo de corto plazo. Los modelos HMM han sido entrenados utilizando técnicas de aprendizaje automático no supervisado. Se desea en una siguiente entrega de este artículo, implementar modelos que utilicen técnicas de aprendizaje automático supervisado basándose en los resultados de este estudio.
Un HMM es un modelo que genera distribuciones probabilísticas, basándose en la información proveniente de la secuencia de muestras observadas. Debido a su capacidad de detectar secuencias temporales, este modelo es ampliamente utilizado para el descubrimiento de patrones temporales en aplicaciones como reconocimiento del habla, escritura y gestos, y además, reconocimiento del ADN humano [1, 2, 4].
Para el desarrollo de esta investigación, se utilizó los datos de demanda de la Empresa Eléctrica Quito S.A, EEQ, con resolución media horaria de los años 2014 hasta 2017 obtenidas de la base de datos Sistema de Información Operativa, SIVO, de la Subgerencia de Análisis de la Operación de CENACE (SAO).
Mediante este método se predice la demanda de la EEQ a corto plazo, en base a la demanda de tiempo real obtenida de un PI-Server. De esta manera, la propuesta se convierte en una herramienta de pronóstico de demanda diario para el análisis de soluciones en el despacho de energía.
METODOLOGÍA
Definiciones
Definiciones y conceptos propios utilizados para la descripción de la metodología:
Muestra de demanda media-horaria ( O i ): Vector medio-horario que describe el comportamiento de la demanda durante un día (48 valores).
Perfiles de demanda ( 𝑷 𝒊 ): Grupo de muestras de demanda media-horaria, que tienen un comportamiento similar. Se encuentra definido por el vector promedio𝝁, acompañado del vector de desviación estándar 𝝈, cada desviación estándar asociada a su valor promedio:
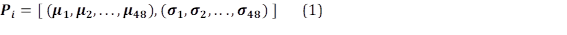
Familia de perfiles de demanda: Una familia de perfiles asocia un conjunto de perfiles de demanda, donde los perfiles pertenecientes a dicha familia tiene un grado de similitud asociado.
Perfil de demanda esperado ( 𝑷 𝒆 ): Dada la variable en tiempo real de la demanda X con h valores desde las 00:00:00 del día. El perfil de demanda esperado, es aquel que se acerca lo más posible a la señal de tiempo real. Se lo determina a través de minimización del error por partes entre la colección de perfiles de demanda 𝝁 𝒊 y la variable en tiempo real:
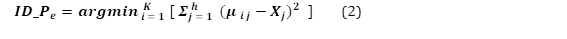
Desviación estándar de la demanda esperada: Es el vector 𝝈 del perfil de demanda esperado.
Área de demanda esperada: Área definida por el perfil de demanda esperado, donde el límite superior e inferior se calculan usando la desviación estándar y su valor promedio:


Aprendizaje supervisado: Técnica del aprendizaje automático que mapea un vector de entrada con una salida deseada. El entrenamiento de los modelos asociados se realiza a través de muestras entrada-salida.
Aprendizaje no supervisado: Técnica del aprendizaje automático que infiere una función/modelo para describir estructuras ocultas de un conjunto de datos no etiquetado.
Metodología
La metodología empleada usa el aprendizaje automático no supervisado para el descubrimiento de patrones típicos y singulares de la demanda, luego usando técnicas de agrupamiento jerárquico, se determinan las familias de demanda existentes. Finalmente la señal en tiempo real es buscada dentro de una familia de perfiles de demanda, el perfil de demanda más acercado es usado para calcular el área de demanda esperada. En la Fig. 1 se ilustra la metodología.

Descubrimiento de perfiles de demanda
Para realizar el descubrimiento de perfiles de demanda, se realizó el entrenamiento y selección del mejor modelo oculto de Markov. El detalle del desarrollo de este modelo es extenso y se puede encontrar un excelente tutorial en [3], y literatura que describe sus detalles en [1],[4] y [7].
En los siguientes párrafos se incluye los conceptos más importantes de dicho modelo, con el objetivo de explicar la metodología seguida. Se Define el HMM siguiendo la nomenclatura descrita en [7]:
Un modelo HMM realiza tres suposiciones referentes a la cadena de Markov oculta:
Suposición del horizonte limitado: la probabilidad de estar en un estado en tiempo t ( S t ) depende solamente del estado en el tiempo t-1 ( 𝑺 𝒕−𝟏 ). Se asume que el estado 𝑺 𝒕−𝟏 tiene suficiente información para predecir el futuro. Formalmente:
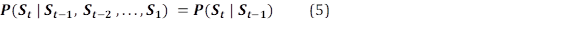
Suposición del proceso estacionario: la distribución condicional sobre un siguiente estado dado no cambia a pesar del tiempo. Es decir, se asume que las probabilidades de transición son independientes del tiempo real en el que se dio dicha transición:
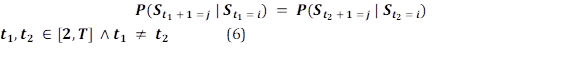
Suposición de la independencia de las salidas: la salida actual ( 𝑶 𝒊 ) es estadísticamente independiente de la salidas previas ( 𝑶 𝒊−𝟏 , 𝑶 𝒊−𝟐 , ..., 𝑶 𝟏 ) , formalmente:
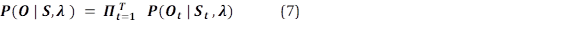
Finalmente, un modelo HMM dadas las tres suposiciones anteriores permite resolver tres tipos de problemas:
Proceso de aprendizaje/ entrenamiento: El modelo HMM es ajustado en función de las muestras O. Es decir, dada la secuencia O, se determina el mejor modelo con parámetros 𝝀 que se ajuste a la secuencia.
Proceso de evaluación: Dada la secuencia de observaciones O, la secuencia de estados S y los parámetros 𝝀, se determina la probabilidad de que dicho modelo haya generado la secuencia O dada la secuencia S, es decir, resolver la ecuación (7).
Proceso de decodificación: Se determina la secuencia de estados S “más probable” que generó la secuencia de observación O. Es decir, encontrar la secuencia S que maximiza el número de estados correctos correspondientes a las observaciones. Este problema es resuelto a través del algoritmo de Viterbi [5]
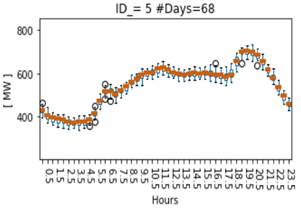
Sánchez en su trabajo [6] muestra como se puede usar un modelo HMM para encontrar patrones temporales a través de resolver los problemas descritos en el siguiente orden: 1. aprendizaje, 2. evaluación y 3. decodificación. En su trabajo se usa un 75% del conjunto de datos para el entrenamiento, un 25% para la evaluación, y finalmente, se realiza la decodificación total del conjunto de datos para el agrupamiento de muestras. Para este artículo, se ha procedido de la misma manera, de forma que, en el proceso de aprendizaje, las observaciones de entrada son las muestras de demanda media-horaria y se entrenan los modelos usando el algoritmo de maximización de la expectación (EM) para encontrar los parámetros 𝝀 [5, 7]. El número de muestras del conjunto de datos es de 1460 correspondiente a 4 años (2014-2017) de demanda de la EEQ. En el proceso de evaluación, un total de 400 modelos son entrenados, de los cuales se selecciona el modelo cuyo 𝒍𝒐𝒈(𝑷(𝑶 | 𝑺, 𝝀 )) es el mayor [5]. Para evaluar la calidad de los perfiles de demanda, se utiliza una box plots [8] con el objetivo de observar la varianza de dichos agrupamientos. La Fig. 2 muestra un ejemplo de perfil de demanda identificado con el ID=5 dónde 68 días han tenido un comportamiento similar. Se observa que la desviación estándar no excede los 20 MW, para este perfil de demanda. Un modelo poco entrenado, dará desviaciones superiores y por ende su agrupamiento no será adecuado.
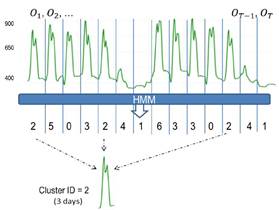
La manera de agrupar los días, se realiza a través del proceso de decodificación. Del modelo mejor entrenado se obtiene un total de K=57 agrupamientos. Es decir existe una secuencia S de longitud T que es la permutación de estos K estados, cada uno correspondiente a cada observación, creando de esta manera un mapeo entre observaciones y los estados ocultos que “generaron” estas muestras. La Fig. 3 muestra un ejemplo hipotético donde se observa cómo se asocian el agrupamiento ID=2, en los cuales tres dias son similares.
Descubrimiento de las familias de perfiles de demanda
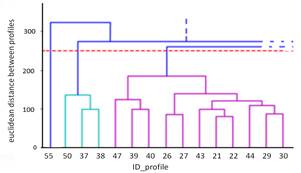
Sánchez [6] en su trabajo propone el uso de un Hierarchical Agglomerative Clustering (HAC), con el objetivo de realizar una comparación entre agrupamientos. En base de lo propuesto, para determinar si la representación del HAC es adecuada, se procedió a evaluar el agrupamiento usando el Cophenetic correlation coefficient [9]. El resultado final permite la construcción de un dendograma, donde se aprecian las familias de perfiles de demanda. La Fig. 4 muestra un extracto del dendograma total. En el eje X se encuentra los K=57 agrupamientos, mientras que en el eje Y la distancia de disimilitud euclidiana entre agrupamientos. Así por ejemplo, el perfil 39 es muy parecido al perfil 40, y ambos son muy diferentes del perfil 38, que pertenece a otra familia. El racimo en color magenta es un ejemplo de familia de perfil. Esta familia es muy categórica ya que está conformado en un 99.5% de perfiles de demanda correspondientes al día lunes, mientras que el racimo en color cyan está conformada por días jueves de máxima demanda. Adicionalmente el perfil 55 contiene días atípicos correspondiente a días feriados. El umbral que permite la distinción de familias es un valor empírico, que es determinado por el analista. Para el ejemplo, un valor de 250, permitió la creación de 6 familias.
Pronóstico de la demanda en tiempo real
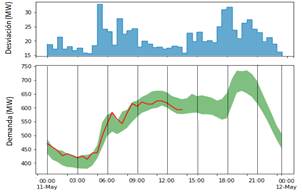
Dadas las familias de demanda y la variable en tiempo real, se puede llegar a determinar el perfil de demanda esperado. Para ello se aplica la fórmula (2) y posteriormente se procede al cálculo del área de demanda esperada conforme a (3,4). Esta área sirve como base, para identificar si la demanda del día actual, sigue algún perfil de demanda ya conocido, o de ser el caso, la demanda se está comportando de manera atípica. La Fig. 5 muestra el pronóstico de la demanda en tiempo real. La línea en color rojo es la demanda en tiempo real muestreada cada 15 minutos. La sombra en color verde es el área de demanda esperada. Es decir, se espera que el comportamiento de la demanda real esté dentro de los límites del área. Adicionalmente, en la parte superior del gráfico se ha añadido la desviación estándar del perfil de demanda esperado. Así por ejemplo, se observa que la demanda a las 18:00 podría tener una variación de 30 MW aprox. alrededor de la media. Con este último artefacto visual, el operador tiene un criterio para determinar las horas de máxima variación de la demanda. Finalmente con el objetivo de hacer más robusto al algoritmo, el perfil de demanda esperado es la unión de los tres perfiles más cercanos a la demanda real, con el criterio de máximos y mínimos. Así cada perfil aporta a la creación de valles e inflexiones.
DESARROLLO
Software utilizado
La exploración de datos ha sido desarrollada sobre Jupyter Python con las librerías asociadas a HMM (hmm_learn ). Además para el entrenamiento de los modelos, se ha desarrollado una aplicación en Python que sea capaz de realizar el entrenamiento en paralelo, explotando de esta manera la tecnología disponible.
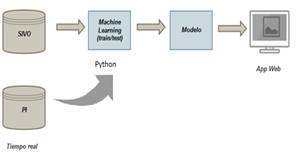
Arquitectura del software
Al inicio de esta arquitectura se encuentra una base de datos ya validada la cual permite realizar el proceso de aprendizaje/entrenamiento al modelo. Posteriormente, con la información de tiempo real, obtenida de PI-Server, se evaluó al modelo obtenifo en el proceso de entrenamiento. Finalmente los resultados son mostrados un una aplicación en el computador como se ilustra a continuación:
RESULTADOS Y EVALUACIÓN
Perfiles de demanda
El descubrimiento de perfiles efectuado desde 01-01-2014 hasta 31-12-2017 proporciona un total de 57 perfiles de demanda. La Fig. 2 muestra un ejemplo de ellos. Se obtuvieron 40 perfiles que son categóricos y 17 que son vacilantes. En los perfiles categóricos más del 90% de sus muestras pertenecen a un día en particular. Así por ejemplo, el perfil ID=39 agrupa estrictamente 43 días lunes de los años 2014 a 2017. Un ejemplo de perfil vacilante es el perfil ID=28 que contiene 19 días martes, 23 días miércoles y 9 días jueves, lo que demuestra que los días martes, miércoles y jueves tienen un comportamiento similar que era conocimiento empírico que ya tenía el operador. Adicionalmente, a través del HAC se puede detectar aquellos perfiles que tienen un comportamiento singular, por ejemplo, el perfil ID=54 (véase en Fig. 2 tiene una distancia euclidiana grande referente a otros perfiles. Este perfil agrupa 9 días feriados, entre ellos Navidad, fin de año y 2 de noviembre.
Familias de demanda
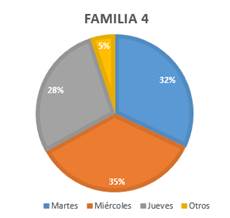
El umbral de distancia igual a 250 permitió encontrar 6 familias, de las cuales 3 son categóricas y 3 son vacilantes. Por ejemplo, como se muestra en la Fig. 7, la familia 4 es vacilante ya que contiene 32% de perfiles típicos del día martes, 35% del día miércoles, 28% del día jueves y 5% para otros días. De la misma manera se verificó que una familia puede contener los perfiles correspondientes a días feriados y otra familia contener los perfiles asociados a días de alta demanda.
Pronóstico de demanda en tiempo real
En una primera evaluación del pronóstico en tiempo real, se observó que las bandas del área de demanda esperada, no superan los 35 MW alrededor de la media, esto implica una variación del 9% de la demanda total de la EEQ (761 MW). En un tiempo de evaluación de 30 días se observó que la herramienta acierta el 86% de los casos y el valor de demanda en tiempo real se encuentra dentro de la banda de demanda esperada.

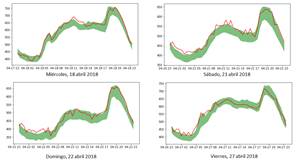
Esta evaluación sigue el criterio de control estadístico de calidad, donde se considera como día incumplido, aquel día donde se registre 2 horas (4 valores consecutivos) de desvío, fuera del área de predicción, criterio que se utiliza en el centro de control del CENACE para realizar un redespacho por desvío de demanda. Se observó que para el mes de evaluación (abril 2018), el 86% (26 días) fueron acertados por la metodología, como se ilustra en la Fig. 8. El 14% restante presenta un incumplimiento como se muestra en la Fig. 9.
4. CONCLUSIONES Y RECOMENDACIONES
La evaluación del pronóstico en tiempo real de la demanda, conforme a los resultados obtenidos en un tiempo de evaluación de 30 días es aceptable. En una futura investigación se deberá evaluar con mayor rigurosidad la herramienta. Como plan piloto se ha comenzado con la demanda de la EEQ, sin embargo dado los resultados obtenidos, se desea ampliar su uso a otros puntos de entrega en el Sistema Interconectado.
El descubrimiento de perfiles de demanda está permitiendo la ganancia de conocimiento. Si bien es cierto, anteriormente se conocía de manera empírica que la demanda de los días lunes tenía un comportamiento característico, gracias a esta investigación se confirma dicha afirmación. Además se pudo verificar que existen perfiles de demanda que son interanuales, y algunos son muy característicos en ciertos meses, lo cual puede estar ligado a temas de clima, o periodos altos de producción.
De los resultados obtenidos, se observa que la metodología tiene aún posibilidades de mejora. Por ejemplo se puede determinar una banda autoajustable cambiando las fórmulas (3,4) donde el valor de 𝜶 oscile entre 1 a 3 desviaciones estándar. Con esto se consigue ampliar el área de demanda esperada de manera que se disminuya incumplimientos.

