











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
Las redes eléctricas inteligentes de distribución (REID) o Smart Grids, son sistemas de infraestructura eléctrica que integran Tecnologías de la Información y las Comunicaciones (TIC) avanzadas para mejorar la eficiencia y confiabilidad del suministro de energía eléctrica. Uno de los componentes clave de las REID es la digitalización de los sistemas de distribución. Esto implica el uso de sensores y medidores inteligentes (SM, por sus siglas en inglés) con una diversidad de tecnologías de comunicación bidireccional integrando una infraestructura de medición avanzada (AMI, por sus siglas en inglés) [1], que permite enviar y/o recibir información entre el SM y la empresa distribuidora de energía eléctrica.
Cabe destacar que los SM pueden medir no solo la potencia activa, sino también varios parámetros importantes como la potencia reactiva y por ende la potencia aparente, los valores RMS de voltaje y corriente (un segundo y medio ciclo de verdadero RMS), el factor de potencia. y distorsión armónica, etc. [2] . Esta información es almacenada como series temporales, que son conjuntos de datos registrados a lo largo del tiempo, donde cada punto de datos está asociado con una marca de tiempo específica. Posteriormente, estos datos pueden ser utilizados en algoritmos y/o modelos de confiabilidad, respuesta a la demanda y programación de carga, detección de robos de electricidad, modelado de carga y previsión de carga, estimación de estado, localización de fallas, gestión de interrupciones, protección contra fallas de alta impedancia, monitoreo en tiempo real, entre otras [2], [3].
Los SM recopilan mediciones con una frecuencia que puede oscilar entre 5, 15, 30 minutos y una hora [1], [3], [4], generando miles o incluso millones de datos en función del número de SM instalados. La velocidad de transmisión de esta información puede variar según la arquitectura de las TIC empleada. En algunos casos, los datos se envían inmediatamente tras su medición, mientras que en otros puede existir una demora de varios minutos, horas e incluso días antes de ser transmitidos al centro de control o base de datos donde se almacenan por el sistema de gestión de datos de medición (MDMS, por sus siglas en inglés).
El MDMS se encarga de almacenar, gestionar y procesar los datos de los SM para que otras aplicaciones y servicios del sistema eléctrico puedan utilizarlos correctamente. Sin embargo, estas bases de datos pueden estar incompletas debido a falta de registros o entradas, errores de calidad de datos, limitaciones en la disponibilidad de datos, procesos de extracción de datos incompletos, actualización insuficiente, falta de integración de datos, entre otros motivos. Por tanto, los operadores del sistema de distribución (DSO, por sus siglas en inglés) deben garantizar la obtención de un conjunto completo de datos en un estado estacionario futuro para su uso en las aplicaciones mencionadas anteriormente, para lo cual la revisión de la literatura muestra que se han propuesto varias soluciones enfocadas en la predicción de las series temporales.
Entre estas propuestas destacan los métodos tradicionales como los modelos autorregresivos (AR), media móvil (MA), media móvil autorregresivo (ARMA) y media móvil autorregresivo integrado (ARIMA). Por otro lado, los métodos de datos no lineales se basan en tecnologías de Inteligencia Artificial (IA), lógica difusa, métodos metaheurísticos y combinaciones híbridas de estos enfoques [5]. Entre todos estos métodos, aquellos basados en IA se destacan por su capacidad de adaptabilidad y ajuste de parámetros según el tamaño de la muestra o base de datos. Además, son efectivos para enfrentar escenarios y/o casos con cambios en las condiciones ambientales, datos meteorológicos como temperatura, humedad, velocidad del viento y radiación solar, así como variaciones estacionales y diversos tipos de días, incluidos festivos, considerando diferentes entradas y horizontes temporales.
Una amplia gama de técnicas propuestas en IA se encuentran detalladas en [5], [6], [7], enfatizando en especial los métodos basados en el aprendizaje automático (Machine Learning, ML) como las Redes Neuronales Artificiales (Artificial Neural Networks, ANN) y métodos de aprendizaje profundo (Deep Learning, DL) con arquitecturas como Redes Neuronales Recurrentes (Recurrent Neural Networks, RNN), Memoria a Largo Plazo (Long Short-Term Memory, LSTM), Unidad Recurrente con Compuerta (Gated Recurrent Unit, GRU) [8] y Redes Neuronales Convolucionales (Convolutional Neural Networks, CNN). Además, se han incorporado mecanismos de atención [9], [10], [11]. y arquitecturas de Codificador-Decodificador que combinan diversas metodologías de DL.
Sin embargo, las redes eléctricas de distribución actuales se encuentran en un proceso de transición hacia las REID. En este contexto, aun no existe una homologación con respecto a las frecuencias de adquisición y reporte de estas mediciones y pueden estar implementadas una o varias TIC que influirán en el tiempo de actualización y almacenamientos de datos en el MDMS. Además, los modelos DL propuestos en investigaciones recientes han sido evaluados en casos de estudio específicos, con respecto a la frecuencia de mediciones y horizonte de predicción, centrándose en la implementación de los nuevos avances en IA y arquitecturas de entradas multivariables y salida de una variable principalmente potencia o energía activa [12], [13], [14].
Con todos los nuevos avances en IA y considerando las características de las TIC empleadas y las aplicaciones del MDMS, es crucial implementar una arquitectura que garantice la confiabilidad y calidad del servicio. En este contexto, el objetivo principal es identificar qué arquitectura o arquitecturas de ANN o DL podrían ser más adecuadas para aplicaciones en empresas, estudios o investigaciones, demostrando los rendimientos más óptimos en diversos escenarios de frecuencia de muestreo y tiempos de actualización de datos. Esto es crucial dado que las funciones del MDMS requieren magnitudes de voltaje y corriente para ejecutar las aplicaciones mencionadas en [2], [3]. Este enfoque implica realizar predicciones multivariables y multipaso a corto plazo para completar los datos hasta que estén disponibles o se actualicen, a diferencia de lo planteado en [12], [13], [14]. En consecuencia, las arquitecturas a comparar se caracterizarán por tener entradas y salidas multivariables. Se examinarán diferentes escenarios relativos a la frecuencia de toma de mediciones y tiempos de actualización de datos, a fin de abordar la variedad de TIC implementadas en la REID.
El artículo está organizado de la siguiente manera: en la sección 2 se presentan la AMI y los SM, analizando las arquitecturas y tecnologías de adquisición. En la sección 3 se describen las arquitecturas de las redes neuronales recurrentes y convolucionales, híbridas y mecanismos de atención, explicando su funcionamiento y los principios en los que se basan. La sección 4 expone la metodología propuesta, incluyendo las diversas arquitecturas seleccionadas, métricas de rendimiento, las entradas y salidas para los modelos de DL, así como el manejo de la base de datos y el proceso de entrenamiento y prueba de cada modelo. En la sección 5 se presentan los resultados y su correspondiente análisis. Finalmente, se presentan las conclusiones del trabajo.
INFRAESTRUCTURA DE MEDICIÓN AVANZADA (AMI)
Esta sección se enfoca en AMI, especialmente en los Medidores Inteligentes (SM) y las Tecnologías de Adquisición y Almacenamiento de Datos. Se analiza cómo la arquitectura de los medidores y las tecnologías de recopilación de datos presentan desafíos significativos para la predicción a corto plazo en el contexto de la gestión de la energía eléctrica. Estos desafíos incluyen la gestión de grandes volúmenes de datos en tiempo real y la garantía de la precisión y la integridad de la información recopilada, elementos esenciales para lograr una predicción efectiva en entornos dinámicos.
En este sentido, el lado de medición del sistema de distribución ha sido el foco de las inversiones en infraestructura más recientes. Los primeros avances de automatización de la medición, o AMR (Automatic Meter Reading), permitieron a las empresas de servicios públicos leer de forma remota los registros de consumo y la información básica del estado de las instalaciones de los clientes [15]. Debido a su sistema de comunicación unidireccional, AMR se limita a la lectura remota no pudiendo ejecutar aplicaciones adicionales, lo que llevó a las empresas de servicios públicos a avanzar hacia AMI.
AMI dota a las empresas de servicios públicos con comunicación bidireccional a los SM, pero también la capacidad de evaluar el estado de la red. Los recientes sistemas de AMI, equipados con una arquitectura mejorada y trabajando en conjunto con sensores inteligentes y una tecnología de control distribuido más sofisticada, permiten a las empresas de servicios públicos realizar el control y la gestión de la red [16].
Medidores inteligentes (SM)
La medición es el primer tema a considerar con respecto a la integración de energías renovables. Si bien el control y el monitoreo en tiempo real pueden evitarse por un tiempo, la facturación requiere que se implemente una estrategia de medición desde la aparición del primer dispositivo en el sistema. Hay dos arreglos de medición principales actualmente en uso, con diferentes niveles de impacto potencial en un sistema AMI, medición única y medición dual.
La medición bidireccional única es la más común entre los prosumidores, que consiste en emplear un único medidor para registrar tanto la energía que fluye hacia la red como la que proviene de ella. Estos medidores deben ser bidireccionales, capaces de medir el flujo de energía positivo y negativo. Esta disposición admite la medición neta, un esquema de tasas que valora teóricamente la energía generada al mismo nivel que la energía consumida. En cambio, la medición dual realiza un seguimiento separado de las cantidades de energía entregadas y recibidas, información que se pierde cuando se utiliza la disposición de un solo medidor.

Figura 1: Usuario con un medidor inteligente y medidor inteligente adicional (opcional) para monitoreo de GD
Específicamente, la generación está vinculada a la carga del cliente, lo que hace imposible determinar exactamente cuánta energía renovable se genera. Por ejemplo, en la Fig. 1 se presenta un diagrama unifilar donde las flechas rojas indican la dirección de la energía según si se consume, se genera o se almacena la energía eléctrica [17].
Esto plantea una problemática: un sistema solar fotovoltaico que genera 2kW en una casa con una carga de 3kW no se puede distinguir de una casa que no genera nada y consume 1kW. La solución a este problema es utilizar un segundo medidor, uno dedicado al sistema de generación renovable. El enfoque de medición dual es superior desde la perspectiva de los datos, y es preferido por la mayoría de las empresas de servicios públicos, pero es poco común debido a la complejidad y el costo de instalar un segundo medidor. Tanto la medición única bidireccional como la medición dual impactan en el sistema AMI ya que multiplican la cantidad de datos que se deben recopilar.
En un sistema de datos muestreados o de intervalo, la medición bidireccional podría duplicar la cantidad de datos recopilados de cada intervalo porque la energía entregada y recibida probablemente se registraría como mediciones separadas. La medición dual puede triplicar los datos de cada premisa porque el medidor primario aún puede ser bidireccional. Además, la presencia de recursos de generación en cada sitio puede crear un interés o la necesidad de otras cantidades medidas.
Finalmente, como se mencionó en la introducción los SM pueden tomar mediciones de demanda, energía, instantáneas, calidad y armónicos, en la Fig. 2 se muestran mayor detalle de las capacidades de medición en cuanto a variables de demanda (potencia) y de energía, mediciones instantáneas y respecto calidad de la energía y armónicos (calidad de producto técnico)
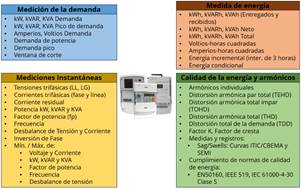
Arquitectura
La arquitectura implica el despliegue de una infraestructura heterogénea, que incluye dispositivos de medición, redes de comunicación y sistemas de recolección, almacenamiento local o a través de servicios en la nube y procesamiento de datos a través de un MDMS, así como las tareas de administración e instalación asociadas para su correcto funcionamiento y se basa en cuatro pilares principales:
Un dispositivo de medición inteligente.
Un dispositivo de recopilación de datos, conocido como concentrador de datos.
Un sistema de comunicación utilizado para el flujo de datos.
Un sistema centralizado de gestión y control, que se encuentra en el centro de control.
Los sistemas de SM son implementaciones heterogéneas con diferentes requisitos y características, ya que dependen en gran medida del uso previsto. Además, se pueden encontrar diferentes tipos de medición en el mismo sistema de medición inteligente. Se pueden diferenciar tres grupos principales de medición:
A pedido: los flujos de datos medidos desde los puntos de consumo a los centros de control a pedido específico de la empresa de servicios públicos cuando sea necesario;
programado: flujos de datos medidos desde los puntos de consumo a los centros de control mediante tareas preprogramadas y entre cuatro y seis veces al día;
A granel: la utilidad recopila información de medición de todos los dispositivos varias veces al día [18].
Tecnologías de adquisición y almacenamiento de datos
El componente de comunicaciones juega un papel crucial en las redes eléctricas inteligentes. Se utilizan tecnologías de comunicación avanzadas, como el Internet de las cosas (IoT) y el 5G, para conectar y transmitir datos entre los diferentes elementos de la red, permitiendo una gestión más eficiente y segura.
La adquisición de información de los medidores inteligentes se realiza principalmente a través de tecnologías de comunicación inalámbrica y cableada. Las tecnologías inalámbricas más comunes incluyen ZigBee, Wi-Fi y GSM (Sistema Global para Comunicaciones Móviles), mientras que las tecnologías cableadas incluyen Ethernet y RS-485.
ZigBee es una tecnología inalámbrica de bajo consumo de energía que se utiliza ampliamente en la red de distribución eléctrica. Permite la comunicación bidireccional entre los medidores y la infraestructura de la red de distribución. Wi-Fi también es una opción popular, ya que es ampliamente compatible y ofrece una alta velocidad de transmisión de datos. GSM utiliza la red móvil para transmitir información de los medidores a través de mensajes de texto o datos.
En cuanto a las tecnologías cableadas, Ethernet es ampliamente utilizada debido a su alta velocidad de transmisión y confiabilidad. Se utiliza principalmente para la comunicación entre los medidores inteligentes y el centro de control. RS-485 es otra opción común, especialmente para la comunicación a larga distancia.
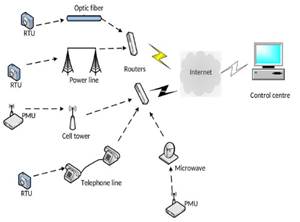
En la Fig. 3, se observa un esquema de distintas tecnologías de comunicación, donde se observa que las tecnologías de adquisición y almacenamiento de información de medidores inteligentes en una red de distribución eléctrica ofrecen una amplia variedad de opciones, tanto inalámbricas como cableadas, para obtener una descripción más detallada de estas tecnologías, se puede consultar en [19].
Estas tecnologías brindan una lectura precisa y una amplia gama de funcionalidades avanzadas. El almacenamiento de la información puede ser centralizado o distribuido, a través de servidores locales o usando servicios en la nube a través del MDMS, algunos casos de este tipo de implementaciones se detallan en [20].
Una función fundamental del MDMS es validar y predecir los datos de los SM para asegurar la integridad y precisión de la información, a pesar de las distintas frecuencias de toma de mediciones y tiempos de actualización en la base de datos. De esta manera, las demás aplicaciones y servicios del sistema eléctrico pueden hacer un uso adecuado de los datos.[21].
En conclusión, la elección, implementación e instalación de las tecnologías de adquisición y almacenamiento de datos adecuados dependerá de las necesidades y recursos disponibles de cada empresa de servicio eléctrico.
Arquitecturas de Deep Learning
En esta sección se exploran las principales arquitecturas de Deep Learning empleadas para el pronóstico a corto plazo en el ámbito de medidores inteligentes. Se presentan y analizan cuatro enfoques principales: Redes Neuronales Recurrentes (RNN), Redes Neuronales Convolucionales (CNN) y Redes Neuronales Híbridas Encoder-Decoder y Mecanismos de atención. Estas estructuras son de vital importancia en este estudio, siendo examinadas minuciosamente para comprender su aplicación en la precisa predicción de datos de medición en el corto plazo.
Redes neuronales recurrentes
Las redes neuronales recurrentes (RNNs por sus siglas en inglés) son una arquitectura de aprendizaje profundo que se utilizan para modelar secuencias de datos. A diferencia de las redes neuronales feed-forward tradicionales, las RNNs (Fig. 4a) tienen retroalimentación, lo que les permite tomar decisiones basadas en el contexto anterior.
Las RNNs tienen la capacidad de mantener estados ocultos a lo largo del tiempo, lo que les permite recordar información de secuencias anteriores. Esto las hace adecuadas para resolver problemas de procesamiento del lenguaje natural, reconocimiento de voz, traducción automática y otras tareas relacionadas con la secuencia de datos.
Existen diferentes variantes de RNNs, y algunas de las más comunes son las Simple RNN, LSTM (Long Short-Term Memory) (Fig. 4b) y GRU (Gated Recurrent Unit) (Fig. 4c). A continuación, se proporciona una descripción detallada de cada uno de estos tipos de RNN [8]:
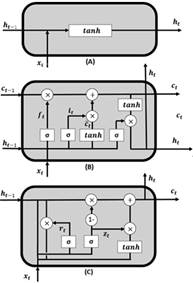
Figura 4: Representación esquemática de (A) Red Neuronal Recurrente simple (RNN), (B) Memoria a Largo-Corto Plazo (LSTM) y (C) Unidad Recurrente Cerrada (GRU) [8] .
Simple RNN, es el tipo más básico de RNN. Su principal fortaleza radica en su simplicidad computacional. Sin embargo, sufre del problema de desvanecimiento de gradientes, lo que significa que a medida que la red se retroalimenta en el tiempo, los gradientes pueden volverse muy pequeños y la red se vuelve incapaz de aprender dependencias a largo plazo.
LSTM es una variante de RNN que soluciona el problema de desvanecimiento de gradientes. Esto se logra mediante el uso de unidades de memoria, denominadas celdas, que permiten retener información durante largos períodos de tiempo. Las celdas LSTM tienen estructuras internas llamadas puertas que regulan el flujo de información, lo que les permite recordar y olvidar información según corresponda.
GRU es otra variante de RNN que también aborda el problema de desvanecimiento de gradientes. Similar al LSTM, el GRU utiliza unidades de memoria para almacenar y recordar información. Sin embargo, en lugar de utilizar celdas y puertas separadas, el GRU utiliza un conjunto de puertas que controlan el flujo de información dentro de la red. Esto lo hace computacionalmente más eficiente que el LSTM.
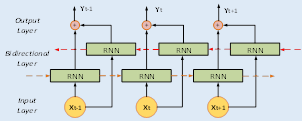
Además de las RNNs mencionadas, también existe la opción de utilizar redes neuronales recurrentes bidireccionales (Fig. 5). Esta arquitectura combina dos RNNs, una que procesa la secuencia en orden directo y otra que la procesa en orden inverso. De esta manera, la red puede capturar tanto la información del pasado como la del futuro al mismo tiempo, lo que puede ser útil en tareas de predicción o clasificación en las que la información contextual puede ser bidireccional.
Redes neuronales convolucionales
Las redes neuronales convolucionales (CNN) como se muestra en la Fig. 6, son un tipo de arquitectura de redes neuronales profundas utilizadas principalmente para el procesamiento de imágenes y reconocimiento visual, se han destacado en el campo de la visión por computadora debido a su capacidad para extraer automáticamente características relevantes a partir de imágenes complejas y realizar operaciones de convolución en ellas.
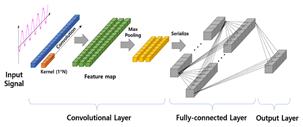
Sin embargo, en los últimos años, se ha demostrado que las CNN también pueden ser aplicadas con éxito en el análisis de series temporales, lo que ha ampliado su ámbito de aplicación a un nuevo dominio.
La principal ventaja de utilizar las CNN en el análisis de series temporales es su capacidad para extraer características relevantes a partir de datos secuenciales y realizar operaciones de convolución en ellos de manera eficiente. Esto permite la detección automática de patrones y tendencias ocultas en los datos a lo largo del tiempo, lo que puede ser especialmente útil en la predicción y clasificación de eventos futuros en las series temporales. Para aplicar las CNN en el análisis de series temporales, es necesario adaptar su arquitectura y métodos de entrenamiento para que sean compatibles con este tipo de datos. Esto implica realizar operaciones de convolución en 1D en lugar de 2D, y utilizar capas de pooling y de muestreo adecuadas para reducir la dimensionalidad de los datos secuenciales.
En cuanto a la aplicación de las CNN en series temporales, han demostrado ser eficientes en diversas tareas [23], [24]. Por ejemplo, en el pronóstico del clima, se pueden utilizar para predecir variables meteorológicas como la temperatura, la humedad y la presión atmosférica en función de datos históricos [25]. En el análisis de señales biomédicas, pueden ser utilizadas para identificar patrones y tendencias en electrocardiogramas, electroencefalogramas y otros tipos de señales [26].
En resumen, las redes neuronales convolucionales (CNN) han demostrado su versatilidad al ser adaptadas al análisis de series temporales. Su capacidad para extraer características relevantes y realizar operaciones de convolución en datos secuenciales ha ampliado su posible utilización en diferentes campos.
Redes neuronales híbridas
Las arquitecturas que combinan redes neuronales recurrentes y convolucionales han mostrado buenos resultados en el procesamiento de series temporales en diversos campos, como la predicción del clima, el análisis de señales biomédicas y el procesamiento de lenguaje natural. Estas arquitecturas aprovechan las fortalezas de ambas estructuras de red para capturar tanto la dependencia temporal a largo plazo como las características espaciales en los datos, descritos en [27], [28].
Una de las arquitecturas más utilizadas es el Encoder-Decoder, que consta de dos partes principales. El encoder se encarga de representar la secuencia de entrada en un espacio de características de menor dimensión, mientras que el decoder reconstruye la secuencia de salida a partir de esta representación.
En el contexto de procesamiento de series temporales, el encoder puede estar compuesto por capas convolucionales que extraen características espaciales relevantes de la serie, como patrones a largo plazo o tendencias generales. Estas capas convolucionales se pueden combinar con capas recurrentes, como las unidades LSTM o GRU, para capturar la dependencia temporal a largo plazo y los patrones secuenciales.
El decoder, a su vez, utiliza capas más profundas de redes recurrentes para generar la salida deseada a partir de la representación obtenida por el encoder. Los estados ocultos de las capas recurrentes del encoder se utilizan como contexto para guiar la generación de la secuencia de salida paso a paso.
Estas arquitecturas han demostrado ser eficientes para capturar la estructura temporal compleja de las series temporales, ya que combinar capas recurrentes y convolucionales permite modelar tanto las dependencias a largo plazo como las características espaciales, como patrones locales, cambios abruptos o tendencias generales [29], [30].
Mecanismos de atención
En el ámbito del DL, los mecanismos de atención se han convertido en una herramienta fundamental para mejorar la capacidad de las redes neuronales para procesar información de manera efectiva y eficiente. Estos mecanismos permiten a la red centrar su atención en partes específicas de la entrada, lo que ayuda a mejorar el rendimiento en tareas complejas como la traducción automática, la generación de texto y la clasificación de imágenes.
Una de las ventajas clave de los mecanismos de atención sobre otras arquitecturas de redes neuronales es su capacidad para capturar dependencias a larga distancia en los datos de entrada. Esto significa que la red puede identificar relaciones complejas entre elementos distantes en una secuencia, lo que resulta en un mejor rendimiento en tareas de predicción de series temporales y secuencias de datos.
Luong et al. propusieron un mecanismo de atención global y atención local para la traducción automática, donde la atención local considera un subconjunto de palabras de origen a la vez, siendo computacionalmente menos costosa que la atención global o suave [9]. Por otro lado, Bahdanau et al. en [10] introdujeron la RNNsearch, que aplicó el mecanismo de atención a la tarea de traducción automática por primera vez. Finalmente, el mecanismo Multi-Head combina múltiples mecanismos de atención para capturar diferentes aspectos de la información en la secuencia de entrada, mejorando la complejidad de la relación temporal entre los datos [11].
En el contexto de la predicción de series temporales, los mecanismos de atención han demostrado ser especialmente útiles para modelar la dependencia temporal de una serie de datos. Al permitir que la red se centre en las partes más relevantes de la secuencia en cada paso de tiempo, los mecanismos de atención pueden mejorar significativamente la precisión de las predicciones y la capacidad de capturar patrones complejos en los datos temporales. En resumen, los mecanismos de atención en DL ofrecen una forma efectiva de mejorar la capacidad de las redes neuronales para procesar información de manera más eficiente y precisa, lo que los convierte en una herramienta invaluable para una amplia variedad de aplicaciones, incluida la predicción de series temporales.
Metodología
En las secciones previas se analizan las ventajas del SM en comparación con sus predecesores, así como las diferentes frecuencias de toma de mediciones y tiempos de actualización de datos en una REID, considerando la integración de diferentes tipos TIC descritos en la sección 2. También se revisan los diversos tipos de arquitecturas de DL y las propuestas para la predicción de series temporales que pueden ser utilizadas por los algoritmos o funciones del MDMS presentados en la sección 3.
La estrategia utilizada para llevar a cabo este estudio consiste en primer lugar en la recopilación o selección de datos de series temporales del sistema de medición a analizar. Estos datos incluyen mediciones de magnitudes de tensión (V), corriente (A), potencia activa (kW) y reactiva (kVAr). Se considera que las mediciones de V y A son fundamentales para el correcto funcionamiento de las funciones de MDMS.
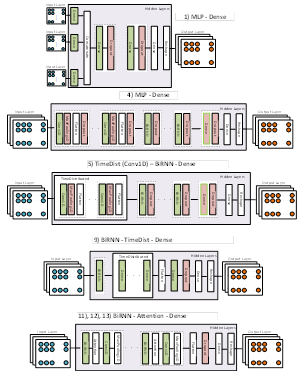
Además, la metodología empleada en este estudio integra una variedad de arquitecturas de ANN y DL para la predicción de series temporales de entradas multivariables de valores eléctricos, como voltaje (V), corriente (A), potencia (kW) y reactancia (kVAr). Específicamente, se emplearon técnicas como redes neuronales recurrentes para identificar patrones temporales, redes neuronales convolucionales para la extracción de características espaciales, combinaciones híbridas y encoder-decoder para la generación de datos secuenciales de entrada y salida, y mecanismos de atención para enfocarse en segmentos específicos de la serie temporal durante la predicción. La integración y combinación de estas arquitecturas se ilustra en la Fig. 7 y se implementaron en Python 3.10, ofreciendo un enfoque completo y eficiente para la predicción de valores eléctricos, destacándose por su precisión y eficacia en la generación de valores de V y A como salida.
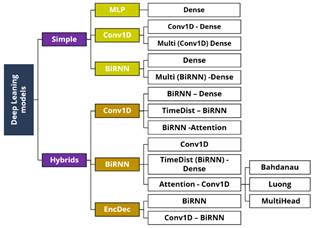
Reiterando que en una REID, pueden llegar a utilizar diferentes tipos de arquitecturas de TIC, y para lograr cubrir las posibles combinaciones de frecuencia de medición y actualización de datos de acuerdo a los descrito en la sección 2 y representados en la Tabla 1, donde el primer escenario corresponde a un periodo de medición de 5 min y actualización de datos de 15 min y la predicción son 3 pasos de 5 min con diferentes longitudes en la ventana de datos de entrada de 3, 6, 12, 24, 48, 72 y 96. En el segundo escenario corresponde a frecuencia de 5 min y actualización de datos de 30 min lo que resulta 6 predicciones de 5 min y se aplican las diferentes longitudes de entrada de datos, de esta manera se generan los escenarios al recorrer Tabla 1 para cada modelo de la Fig. 8. Cada modelo pasa por las etapas de preparación de datos, entrenamiento, ajustes de hiper parámetros, validación y rendimiento de la Fig. 8.
Tabla 1: Horizontes de predicción de datos para mediciones con distintos períodos de resolución y actualización
| Resolución | |||||
| 5 min | 15 min | 30 min | 1h | ||
| Actualización | 15 min | 3 | - | - | - |
| 30 min | 6 | 2 | - | - | |
| 1 h | 12 | 4 | 2 | - | |
| 6h | 72 | 24 | 12 | 6 | |
| 12 h | - | 48 | 24 | 12 | |
| 1 día | - | - | 48 | 24 | |
| 2 días | - | - | - | 48 | |
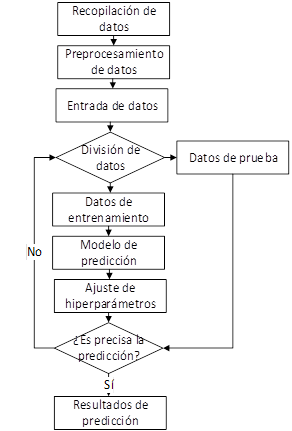
En el proceso de división de los datos, se siguió una metodología estándar en la que se separaron los datos en tres conjuntos: entrenamiento, validación y prueba. En la fase de entrenamiento, se utilizaron los datos de entrenamiento para ajustar los pesos de las redes neuronales, mientras que en la fase de validación se evaluaron diferentes hiper parámetros y se seleccionó el modelo final, en la fase de prueba se evalúa el rendimiento del modelo en datos no vistos previamente.
Por último, para la verificación y comparación de los modelos de la Fig. 7, se aplicaron las métricas de desempeño MAE (Mean Absolute Error), MAPE (Mean Absolute Percentage Error) y RMSE (Root Mean Square Error).


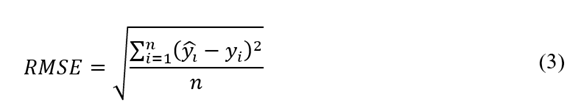
Donde y 𝑖 es el valor real, y i es el valor estimado para los diferentes escenarios de la Tabla 1.
Estas métricas fueron seleccionadas debido a su idoneidad para evaluar el desempeño de modelos predictivos de regresión. Son ampliamente reconocidas en la literatura científica y se consideran estándares en el análisis predictivo por su capacidad para ofrecer una evaluación cuantitativa y comparativa del rendimiento de los modelos.
Análisis de resultados
Para la generación de los escenarios se utilizaron datos recopilados por un SM disponibles en [31], contiene 2075259 mediciones realizadas en una casa situada en Sceaux (a 7 km de París, Francia) entre diciembre de 2006 y noviembre de 2010 (47 meses), registra mediciones cada 1 minuto de tensión (V), corriente (A), potencia activa (kW) y reactiva (kVAr) en el SM y otras mediciones del interior del domicilio que no son considerados en este trabajo.
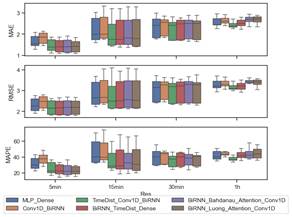
La simulación de escenarios de la Tabla 1 con diferentes longitudes de entrada de datos para cada modelo representado en la Fig. 7 se realizó en un clúster localizado en el Instituto de Energía Eléctrica, dando como resultado un total de aproximadamente 600 casos analizados.
En la Fig. 9 se muestran los diagramas de caja de 6 de los 15 modelos de la Fig. 7, que presentaron las mejores métricas de MAE, RMSE y MAPE para los distintos horizontes de predicción indicados en la Tabla 1 y ventanas de datos de entrada.
La Tabla 2 resume la comparación de los resultados de la Fig. 9 utilizando las métricas de rendimiento. Cada modelo está etiquetado con el número correspondiente al mejor rendimiento en la métrica MAE según se indica en la Tabla 3, junto con la longitud óptima de la ventana de entrada de datos (Input) y el horizonte de predicción analizado (Output). Este proceso se repite para las métricas RMSE y MAPE.
En resumen, los resultados destacan que las arquitecturas híbridas muestran un rendimiento superior en las métricas MAE, RMSE y MAPE en comparación con las arquitecturas simples. Específicamente, el modelo "TimeDist - Conv1D - BiRNN" sobresale respecto a otros modelos, como se describe detalladamente en la Tabla 3.
La Fig. 10 se presentan los diagramas esquemáticos de las arquitecturas de ANN y DL correspondientes a los números de modelo asignados en este estudio, que han demostrado obtener los mejores resultados, los cuales se detallan en la Tabla 3.
Estos resultados sugieren que la combinación de diversas técnicas de DL puede tener un impacto significativo en la precisión de la predicción multivariable y de múltiples pasos de Tensión (F_1) y Corriente (F_2). Esto se puede observar en la Fig. 11a, que muestra los resultados a escala completa, y en la Fig. 11b, que presenta un acercamiento con los datos de prueba que no fueron utilizados durante el entrenamiento del modelo.
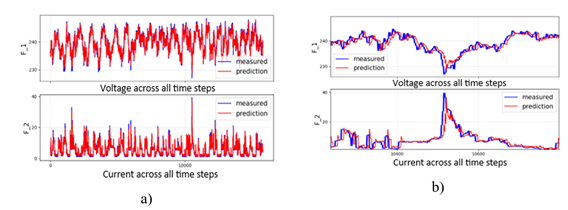
Figura 11: Predicción de Tensión (F_1) y Corriente (F_2) con datos de prueba a través del modelo “ TimeDist - Conv1D - BiRNN” con Res: 5 min. - Act: 30 min a) Escala completa y b) Con acercamiento.
Conclusiones
Las redes de distribución inteligentes han revolucionado la industria eléctrica al permitir un control y monitorización del suministro eléctrico, donde los medidores inteligentes proporcionan una gran cantidad de datos en series temporales, lo que plantea la necesidad de utilizar técnicas de inteligencia artificial para procesarlos y generar información valiosa para el sistema de distribución.
Tabla 2: Comparación de rendimiento de métricas MAE, MAPE y RMS entre los distintos modelos con respecto a MAE
| Escenario | Input - Output | Nro. Mod. | Métricas | ||||
| Res | Act. | MAE | RMSE | MAPE | |||
| 5 min | 15 min | 6-3 | 12 | 1,10 | 1,82 | 16,03 | |
| 30 min | 12-6 | 11 | 1,38 | 2,19 | 19,59 | ||
| 1 h | 12-12 | 12 | 1,71 | 2,58 | 26,72 | ||
| 6 h | 72-72 | 5 | 2,98 | 3,77 | 66,06 | ||
| 15 min | 30 min | 2-2 | 11 | 1,38 | 2,13 | 19,54 | |
| 1 h | 4-4 | 9 | 1,71 | 2,49 | 27,89 | ||
| 6 h | 48-24 | 5 | 2,69 | 3,45 | 49,43 | ||
| 12 h | 48-48 | 1 | 3,01 | 3,69 | 63,05 | ||
| 30 min | 1 h | 48-2 | 13 | 1,60 | 2,25 | 25,51 | |
| 6 h | 48-12 | 1 | 2,33 | 3,04 | 40,26 | ||
| 12 h | 48-24 | 5 | 2,41 | 3,20 | 36,97 | ||
| 1d | 48-48 | 5 | 2,44 | 3,21 | 38,52 | ||
| 1h | 6 h | 24-6 | 9 | 2,23 | 2,93 | 35,62 | |
| 12 h | 48-12 | 10 | 2,36 | 3,04 | 38,57 | ||
| 1 día | 24-24 | 10 | 2,31 | 3,00 | 36,68 | ||
| 2 día | 48-48 | 5 | 2,45 | 3,18 | 36,93 | ||
Tabla 3: Resumen de la comparación de los modelos propuestos con respecto a las métricas de rendimiento
| Nro. | Modelo | MAE | RMSE | MAPE | Total |
| 1 | MLP - Dense | 2 | 3 | 1 | 6 |
| 2 | Conv1D - Dense | - | - | - | - |
| 3 | Multi - Conv1D - Dense | - | - | - | - |
| 4 | Conv1D - BiRNN | 2 | 3 | - | 5 |
| 5 | TimeDist - Conv1D - BiRNN | 5 | 5 | 6 | 16 |
| 6 | Conv1D - BiRNN - Attention | - | - | - | - |
| 7 | BiRNN - Dense | - | - | - | - |
| 8 | Multi - BiRNN - Dense | - | - | - | - |
| 9 | BiRNN - TimeDist - Dense | 2 | 2 | 4 | 8 |
| 10 | BiRNN - Conv1D | - | - | - | - |
| 11 | BiRNN - Bahdanau - Att. - Conv1D | 2 | 1 | 4 | 7 |
| 12 | BiRNN - Luong - Att. - Conv1D | 2 | 1 | 1 | 4 |
| 13 | BiRNN - MultiHead - Att. - Conv1D | 1 | 1 | - | 2 |
| 14 | EncDec - BiRNN | - | - | - | - |
| 15 | EncDec - Conv1D - BiRNN | - | - | - | - |
Los resultados obtenidos en este estudio indican que las arquitecturas de ANN y de DL son herramientas efectivas para el procesamiento de datos de series temporales en un SM y asumiendo que las funciones de MDMS requerirán magnitudes de voltaje (V) y corriente (A) para su ejecución, por lo que las arquitecturas a comparar fueron de entradas (V, I, kW y kVAr) y salidas (V y A) multivariables.
Se analizaron diferentes escenarios respecto a la frecuencia de toma de mediciones y tiempos de actualización de datos, para cubrir la posibilidad de que se encuentren implementadas diferentes TIC en la REID. De esta manera, se identificó la arquitectura de DL que presentó mejores métricas de rendimiento en los distintos escenarios de predicción analizados.
Se optimizó la ventana de entrada de datos en el entrenamiento, y una vez realizada la comparación de las métricas de rendimiento MAE, MAPE y RMSE para 600 casos, el modelo "TimeDist - Conv1D - BiRNN" mostró mejores resultados en comparación con otros modelos, como se muestra en la Tabla 3.
Estos modelos pueden ser utilizados para generar/completar datos a utilizar como ingreso a las aplicaciones de un MDMS (Distribution Management System) como estimación de estado, programas de respuesta a la demanda y monitoreo de la operación en tiempo real.
En este trabajo se empleó información que se puede encontrar en base de datos de acceso libre como son V, I, kW y kVAr. Sin embargo, los nuevos desafíos surgen con la integración de datos adicionales provenientes de los medidores inteligentes en otras aplicaciones del MDMS, como se ilustra en la Fig. 2. Es crucial realizar un análisis exhaustivo para identificar las variables pertinentes para el modelo y considerar la inclusión de variables exógenas.
Además, dado que los tiempos de envío y actualización de datos pueden variar incluso dentro de una misma empresa, las arquitecturas deben asegurar que la información medida o las predicciones estén disponibles de manera consistente en una escala temporal adecuada. Esto implica adaptarse a las necesidades específicas del operador del sistema y aprovechar la información adicional proporcionada por los medidores inteligentes según lo requiera el MDMS.

