











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
El propósito del presente estudio es diseñar un algoritmo predictivo de recomendación que permita predecir la producción de energía eléctrica de tres centrales hidroeléctricas Mazar, Molino y Sopladora, aprovechando el contexto de la capacidad de producción en ese preciso momento, la hidrología y la filosofía de operación.
Para lograrlo se establecen las siguientes fases:
Estado del Arte. En esta fase se realiza el estudio e investigación de lo que se conoce acerca de la predicción de la demanda energética. Esto permite enfocar las acciones para la implementación del algoritmo de predicción de generación eléctrica.
Objetivos y Metodología. En esta fase se describen los objetivos general y específico del presente estudio, así como la metodología aplicada para la construcción y evaluación del modelo predictivo de recomendación.
Contribución. En esta fase se procede a construir tres modelos predictivos uno para cada una de las centrales Mazar, Molino y Sopladora. El primer objetivo es determinar el comportamiento normal de las tres centrales de generación en base al contexto de la hidrología y la filosofía de operación. Y el segundo objetivo es la construcción de los modelos predictivos que aprovechen la capacidad instalada y los recursos hídricos para recomendar la producción más acertada.
Descripción de resultados. La descripción de resultados está dispuesta en dos etapas, la primera es un análisis acerca del impacto de la optimización en la operación de las centrales de generación. Este análisis se realiza comparando los datos actuales con los optimizados. La segunda etapa corresponde al análisis del impacto observable en el escenario de vertimientos lo que constituye el aporte significativo de este trabajo.
ESTADO DEL ARTE
El despacho energético depende de la demanda y de la oferta existente en un Sistema Eléctrico de Potencia (SEP). Sin embargo, el modelo predictivo de recomendación que se propone está enfocado únicamente a maximizar la producción de energía de las centrales de generación de menor costo de producción de energía eléctrica, que son las centrales Molino, Mazar y Sopladora. Esta decisión está basada en la obligación que tiene el CENACE de garantizar el abastecimiento de energía al mínimo costo, preservando la eficiencia y transparencia [1].
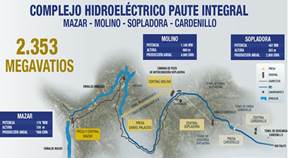
El emplazamiento de las centrales de generación antes mencionadas se muestra en la Fig. 1, en la cual, el modelo predictivo de recomendación debe tener la capacidad de predecir la generación total del complejo Paute Integral. Para lograrlo debe considerar: la estación del año, los caudales de entrada, el nivel de los embalses, restricciones técnicas como equipos en mantenimiento, equipos disponibles, al igual que feriados largos y el clima.
Para diseñar el modelo predictivo de recomendación, se han investigado algunas alternativas; sin embargo, la mayoría de los algoritmos se centran en el pronóstico de la demanda de la energía eléctrica requerida a corto plazo. Ahora, el objetivo del presente trabajo radica en determinar la máxima cantidad de producción de energía eléctrica que se puede generar en base a caudales y niveles de embalse de las centrales de generación Molino, Mazar y Sopladora. Por tanto, se analizan los métodos basados en inteligencia artificial que han dado resultado en el campo de despacho energético.
Redes Neuronales Artificiales
Las redes neuronales artificiales han sido usadas para el escenario tradicional, en que los SEP son diseñados y operados como una sola entidad, y se requiere un pronóstico de demanda de corto plazo, que permita garantizar que el suministro sea confiable. El uso de este método de aprendizaje automático ha reportado muchos éxitos en la predicción a corto plazo en ámbitos de STLF (Short Term Load Forecast), principalmente enfocado en el reconocimiento y clasificación de patrones [3].
Considerando que la predicción de la oferta de energía está basada en hechos observados, se identifican dos razones por la cuales se considera a las redes neuronales aptas para la tarea de predicción y estas son [3]: (1) Las redes neuronales artificiales tienen la capacidad de aproximar numéricamente cualquier función continua con una precisión arbitraria. (2) Las redes neuronales artificiales es un método donde los resultados dependen de los datos proporcionados; por lo tanto, no se requiere postular modelos y estimar parámetros.
La arquitectura de red neuronal más utilizada para la demanda de corto plazo es la Perceptrón Multicapa y las metodologías que se han aplicado son las siguientes:
En un caso, se utilizaron datos de la demanda de energía de cada hora del día como series temporales distintas, correspondientes a los años 2011 y 2012; es decir, se tiene 24 series y, por tanto, se desarrollaron 24 redes neuronales. Con este método se ha logrado que la predicción de cada hora sea independiente. Adicional, se ha considerado que, al realizarlo de la forma expuesta, cada red neuronal resultante tiene menor cantidad de parámetros con relación a una sola red neuronal con 24 nodos de salida [3]. En el otro caso, se utilizaron datos de la serie de tiempo recolectadas cada 15 minutos del periodo que comprende desde el 2007 al 2016. Los datos que contiene son: día, hora, minutos y demanda [4].
Para el pre-procesamiento de datos, se ha establecido que para determinar el perfil de la demanda el factor más importante es el calendario, diferenciando los días laborables, de los fines de semana y días festivos, además del día de la semana y hora del día. Con estas consideraciones, se ha realizado la siguiente clasificación, basado en tres tipos de días que son:
Días laborables.
Fines de semana.
Días Feriados.
Otro factor importante es el clima; por lo cual, se utilizó la temperatura diaria máxima ponderada, obtenida de estaciones meteorológicas.
Finalmente, con el objeto de caracterizar la estacionalidad anual de la demanda, cada mes del año es representado por la humedad relativa media mensual, velocidad del viento media mensual y precipitación media mensual [4] [3].
Los diseños de los trabajos revisados están basados en el Perceptrón Multicapa (MLP) feedForward full conected. Este diseño está conformado por una capa oculta cuya función de activación corresponde a la Tangente Hiperbólica Sigmoidea; mientras que, la función de activación de la única neurona de la capa de salida utiliza una función lineal.
En lo referente a la cantidad de neuronas, el trabajo [3] no indica la cantidad de neuronas en la capa oculta; sin embargo, indica que se han utilizado 13 entradas para predecir la demanda del día siguiente y determinar el despacho. Las entradas son:
La demanda de la misma hora del día anterior y de las cinco horas antes de ese día.
La demanda de la misma hora del mismo día de la semana anterior.
La clasificación del tipo de día: laborable, fin de semana o feriado, que ocupa dos entradas.
La temperatura máxima ponderada del día y las características del mes que son: humedad relativa, velocidad del viento y la precipitación media mensual ocupan otras cuatro entradas.
Otro trabajo [4] indica el uso de ocho entradas para predecir la demanda, una capa oculta con 27 neuronas, una capa de salida que corresponde a la demanda de energía eléctrica. Las entradas utilizadas son: a) temperatura, b) humedad, c) hora del día, d) día de la semana, e) una variable que indica si es un día festivo / fin de semana, f) carga media del día anterior, g) carga de la misma hora del día anterior, y h) Carga de la misma hora y el mismo día de la semana anterior.
Finalmente, para el entrenamiento de las redes neuronales artificiales se ha utilizado el método backpropagation implementado en MatLab con el algoritmo Levenberg Marquardt. [4].
Algoritmos Random Forest
El pronóstico de la demanda a corto plazo hace referencia a la predicción con una hora, un día, o una semana de antelación de la demanda y su precisión está directamente relacionada con la seguridad, la estabilidad y la economía en el funcionamiento del SEP [5].
El algoritmo Random Forest tiene la ventaja de ser tolerante al ruido, resistente al sobreajuste y sólo se necesita examinar pocos parámetros en comparación con otros métodos [5].
Con lo descrito anteriormente, se analiza el trabajo realizado por Huang et al. [5], en el que se propone un método predictivo STLF de estimación de la demanda energética basado en random forest. Para lo cual, se realiza la siguiente metodología:
Los datos utilizados corresponden a la carga histórica del año 2012 de una ciudad al noreste de China. El conjunto total de datos contiene 366 días, el 9% (33 días) se utilizan para el conjunto de pruebas y el 91% (333 días) con conjunto de entrenamiento. El muestreo es de cada hora.
Con el objeto de aumentar la fiabilidad del experimento, el conjunto de prueba se distribuye al azar y en cuatro trimestres.
Basados en los datos anteriores se establecen dos tipos de predicciones: con una hora de anticipación y con un día de anticipación; para lo cual, se utilizan las siguientes características:
El valor de la carga historia de tiempo (t-i) (i=1,2,3…;240)
Día laborable (1->Sí,2-> No)
Día actual.
El momento (de 0 a 23, 24 horas del día)
En este estudio se ignoran las covariables como la temperatura.
Un punto importante en esta metodología es que se realiza una etapa de preselección para obtener las variables más importantes para la clase objetivo. Únicamente las variables más importantes antes obtenidas sirven para entrenar el modelo de Random Forest.
OBJETIVOS Y METODOLOGÌA
Objetivo general
Crear un modelo predictivo de recomendación para el proceso del pre-despacho de energía que permita maximizar la producción de energía eléctrica en las centrales Mazar, Molino y Sopladora en base a los generadores en operación, los caudales de entrada de agua y cuotas de los embalses de Mazar y Amaluza.
Objetivos específicos
Identificar los algoritmos predictivos utilizados para despacho energético a corto plazo y sus ventajas.
Identificar las variables predictivas que se pueden considerar par la creación del modelo predictivo.
Analizar la información disponible acerca del despacho energético en las centrales de generación Mazar, Molino y Sopladora.
Crear un modelo predictivo para cada central de generación con las dependencias existentes por tratarse de un complejo hidroeléctrico en cascada.
Pruebas del algoritmo con días puntuales en los meses de enero, febrero y marzo del 2020.
Metodología de trabajo
Con el objeto de alcanzar el objetivo general y los objetivos específicos, la metodología del trabajo conlleva los siguientes pasos:
Obtención de la información referente al despacho energético de las centrales de generación Mazar, Molino y Sopladora por separado.
Análisis de datos de cada una de las centrales de generación y determinación del comportamiento.
Definición del conjunto de información que se utilizará para el aprendizaje y evaluación del modelo predictivo de recomendación del despacho energético. Para este proceso se utiliza información de 5 años para las Centrales Mazar y Molino (46.297 registros), y para la Central Sopladora se utiliza información de tres años (28.752 registros).
Entrenamiento del modelo predictivo de recomendación utilizando el algoritmo Random Forest. Para el entrenamiento se utilizará el 80% de los datos y el 20% restante para la evaluación del modelo.
Evaluación del modelo predictivo de recomendación con métricas de regresión error cuadrático medio (RMSE) y el coeficiente de determinación (R² score).
Verificación de las variables predictivas más importantes con Ramdom Forest.
Ajuste de datos de entrenamiento hasta conseguir un error adecuado para la predicción del modelo.
Prueba del modelo predictivo de recomendación con la información real.
CONTRIBUCIÓN
Con el objeto de corroborar los objetivos planteados, se realiza tres modelos predictivos, uno para cada central de generación Mazar, Molino y Sopladora. La tecnología que se utiliza para la construcción de los modelos antes descritos es Random Forest. Las principales ventajas y las razones por las que se escogió esta tecnología son las siguientes:
Es un modelo de propósito general que sirve tanto para clasificación como para regresión. Esto quiere decir que funciona correctamente para el presente caso de estudio.
Este modelo es apto para trabajar con grandes volúmenes de datos, dado que tiene la capacidad de combinar los principios de baggin (algoritmos ensamblados) con selección de la variable aleatoria, añadiendo así diversidad y reduciendo el coste computacional. Esta característica es de gran utilidad ya que la información es horaria por 5 años y representa una gran cantidad de datos.
Organización del piloto
Para la organización del piloto se procedió a construir tres modelos predictivos uno para cada una de las centrales: Mazar, Molino y Sopladora. El objetivo es determinar el comportamiento óptimo de las tres centrales de generación basado en la filosofía de operación, las condiciones ambientales y la capacidad de producción disponible al momento.
Para el caso de la Central Sopladora, por ser una central que no posee embalse, la generación de energía depende directa y totalmente de la generación de la Central Molino.
Fase 1. Comportamiento de las tres centrales
Para determinar el comportamiento de las tres centrales se realiza el modelo predictivo de las tres centrales de generación y se evalúan los resultados. Los datos por considerar en los tres modelos corresponden a:
El caudal de entrada, medido en m³/s.
La cota de los embalses para el caso de las centrales Mazar y Molino, para el caso de la central Sopladora es el nivel de la cámara de interconexión. Estos datos son medidos en metros sobre el nivel del mar (m.s.n.m.).
Las unidades de generación disponibles, medido en unidades. Cada central de generación cuenta con las siguientes unidades de generación:
La central Mazar: 2 unidades de generación.
La central Molino: 10 unidades de generación.
La central Sopladora: 3 unidades de generación.
Respecto al central Molino, se incluye la información de la generación de la Central Mazar y para el caso de la Central Sopladora se incluye la generación de la Central Molino.
Modelo predictivo para la central Mazar
En este acápite se explica el proceso involucrado en el entrenamiento del modelo predictivo de recomendación para la central Mazar.
Obtención de datos. Los datos fueron obtenidos del sistema SARDOM (sistema desarrollado internamente en CELEC SUR). Este sistema es utilizado para recopilar la información de la generación de las centrales de generación.
Los datos obtenidos para el análisis del comportamiento de la central Mazar se basaron en los campos expuestos en la Tabla 1.
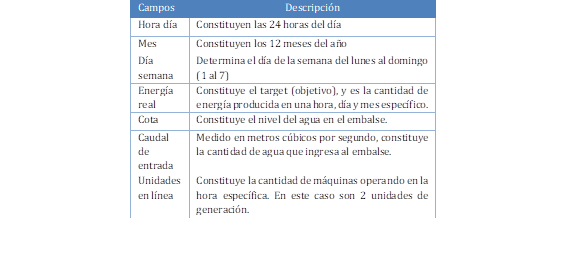
La información obtenida acorde a la Tabla 1, está basada en la historia de 5 años.
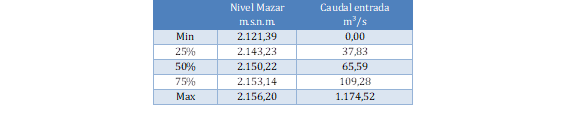
Análisis de datos: La dispersión de los datos se puede revisar en la Tabla 2.
En la Tabla 2 se puede observar que el caudal más elevado se encuentra en el último cuartil y sus valores superan los 109 m³/s. De igual manera, respecto a la cota el último cuartil supera los 2.153 metros sobre el nivel del mar, lo cual coincide con la presencia de varios vertimientos.
Los datos en percentiles de energía se visualizan en la Tabla 3.
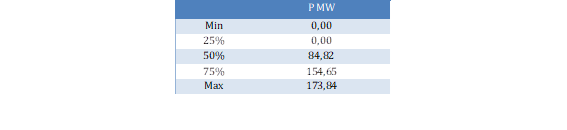
Considerando que cada unidad de generación tiene la capacidad máxima de 85 MW, en la Tabla 3 se puede corroborar que el 25% del tiempo no se produce energía eléctrica, del 25% al 50% se genera energía eléctrica equivalente a una máquina y sólo del 50% del tiempo en adelante se utilizan las dos máquinas para generar energía.
Definición de datos de entrenamiento: El conjunto de datos disponible para el entrenamiento consiste en 5 años desde el 2015 hasta el 2019, en total 46.297 registros. De estos registros se obtienen el 20% para la evaluación del modelo y se utilizan los datos correspondientes a los tres primeros meses posteriores para la evaluación del modelo como test en vivo, esto es: enero, febrero y marzo del 2020.
Entrenamiento del modelo predictivo: El entrenamiento del modelo predictivo se realiza con 250 árboles, utilizando el 80% de los datos para el entrenamiento y el 20% para la evaluación.
Evaluación del modelo: Los resultados de la evaluación se observan en la Fig. 2. Las métricas utilizadas para evaluar el modelo de predicción se observan en la Tabla 4:

La Tabla 4 indica que el error en la predicción es de 17,97; sin embargo, se tiene una precisión del 92% en la predicción de los datos de evaluación. El valor de RMSLE de 0,42 indica que no existe sobreajuste en la predicción, lo que implica que el modelo tiene una capacidad aceptable para generalizar.
Modelo predictivo para la central Molino
En este punto se explica el proceso involucrado en el entrenamiento del modelo predictivo de recomendación para la central Molino.
Obtención de datos: Los datos también fueron obtenidos del sistema SARDOM. Los datos obtenidos para el análisis del comportamiento de la central Molino se basaron en los campos: hora día, mes, día semana, energía real, cota, caudal entrada, unidades en línea, como se puede observar en la Tabla 5.

La información obtenida acorde a la Tabla 5, está basada en la historia de 5 años, recopilada en forma horaria.
Análisis de datos: La dispersión de los datos se puede revisar en la Tabla 6, en la cual se puede observar que el caudal más elevado se encuentra en el último cuartil y sus valores superan los 168 m³/s. De igual manera, respecto a la cota el último cuartil supera los 1.990 metros sobre el nivel del mar, lo cual coincide con la presencia de varios vertimientos.
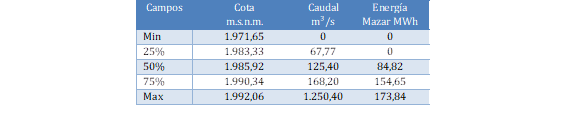
Distribución de datos de la variable target: La distribución de datos de la variable target durante los cinco años analizados mantiene la forma reflejada en la Tabla 7.
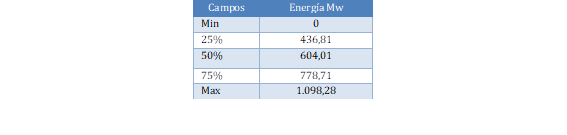
En la Tabla 7 se puede observar el comportamiento de la generación de energía de la Central Molino. Este comportamiento refleja que el 50% del tiempo de producción de energía eléctrica representa valores superiores a 604 MWh de un total de 1.100 MWh.
Definición de datos de entrenamiento: El conjunto de datos disponible para el entrenamiento consiste en 5 años desde el 2015 hasta el 2020, en total 46.297 registros. De estos registros se obtiene el 20% para la evaluación del modelo y se utilizan los datos correspondientes a los tres primeros meses posteriores para la evaluación del modelo como test en vivo, esto es: enero, febrero y marzo del 2020.
Entrenamiento del modelo predictivo: El entrenamiento del modelo predictivo se realiza con 550 árboles, utilizando el 80% de los datos para el entrenamiento y el 20% para la evaluación.
Evaluación del modelo: Los resultados de la evaluación se observan en la Fig. 3.
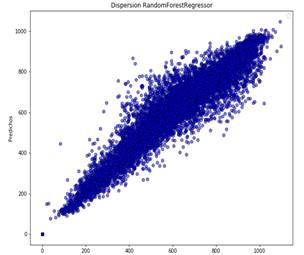
Las métricas utilizadas para evaluar el modelo de predicción se observan en la Tabla 8:

La Tabla 8 indica que el error en la predicción es de 75,28, el cual compara el valor predicho respecto al valor conocido; sin embargo, se tiene una precisión del 89% en la predicción de los datos de evaluación. Por tanto, el valor RMSE se le considera tolerable dentro de los parámetros indicados. El valor de RMSLE de 0,14 nos indica que no existe sobreajuste en la predicción, lo que implica que el modelo tiene una capacidad aceptable para generalizar.
Modelo predictivo para la central Sopladora
En este acápite se explica el proceso involucrado en el entrenamiento del modelo predictivo de recomendación para la central Sopladora.
Obtención de datos: Los datos obtenidos para el análisis del comportamiento de la central Sopladora, obtenidos del sistema SARDOM, se basaron en los campos: hora, día, mes, día de la semana, energía real, cota, caudal entrada, y unidades en línea; expuestos anteriormente en Mazar, adicionando los campos expuestos en la Tabla 9.
La información obtenida acorde a la Tabla 9, está basada en la historia de 3 años, recopilada en forma horaria.
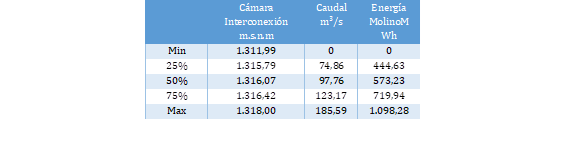
Análisis de datos: La dispersión de los datos se puede revisar en la Tabla 10, en la que se puede observar que el caudal más elevado se encuentra en el último cuartil y sus valores superan los 123,17 m³/segundos. De igual manera, respecto al nivel de la cámara de interconexión en el último cuartil supera los 1.316,42 metros sobre el nivel del mar.
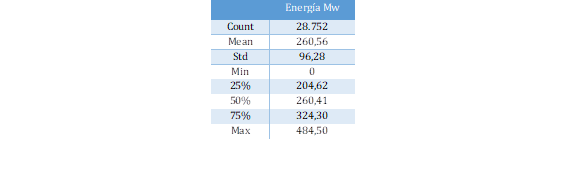
Distribución de datos de la variable target: La distribución de datos de la variable target durante los tres años analizados mantiene la forma reflejada en la Tabla 11, en la que se puede observar el comportamiento de la generación de energía de la Central Sopladora. Este comportamiento refleja que el 50% del tiempo de producción de energía eléctrica representa valores superiores a 260 MWh de un total de posible de 487 MWh.
Definición de datos de entrenamiento: El conjunto de datos disponible para el entrenamiento consiste en 3 años desde el 2017 hasta el 2020, en total 28.752 registros. De estos registros se obtiene el 20% para la evaluación del modelo y se utilizan los datos correspondientes a los tres primeros meses posteriores para la evaluación del modelo como test en vivo, esto es: enero, febrero y marzo del 2020. El piloto se lo realiza con datos del mes de abril de 2020.
Entrenamiento del modelo predictivo: El entrenamiento del modelo predictivo se realiza con 400 árboles, utilizando el 80% de los datos para el entrenamiento y el 20% para la evaluación.
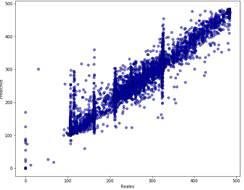
Evaluación del modelo: Los resultados de la evaluación se observan en la Fig. 4.
Las métricas utilizadas para evaluar el modelo de predicción se observan en la Tabla 12:

La Tabla 12 indica que el error en la predicción es de 28,07; sin embargo, se tiene una precisión del 91% en la predicción de los datos de evaluación. El valor de RMSLE de 0,22 nos indica que no existe sobreajuste en la predicción, lo que implica que el modelo tiene una capacidad aceptable para generalizar.
Fase 2. Optimización de los modelos predictivos de recomendación
Para la realización de la optimización, se determina, tanto para la Central Mazar como para la Central Molino un límite de cota que representa la presencia de vertimiento inminente. En caso de llegar a dicho límite, se debe proceder con el despacho de la energía máxima, o en su defecto, con el despacho del 90% del volumen de agua ingresado en el embalse el día anterior, esto acorde al siguiente artículo [6].
Acorde a lo indicado, se determina que el límite de cota que indica vertimiento inminente para el embalse de la Central Mazar es de: 2.151,5 m.s.n.m. y para la cota del embalse de la Central Molino es de: 1.989 m.s.n.m. [6].
RESULTADOS
La descripción de resultados está dispuesta en una primera etapa, que consiste en un análisis acerca del impacto de la optimización en la operación de las centrales de generación. Este análisis se realiza comparando los datos actuales con los optimizados.
Primera etapa
Par el caso de la Central Mazar, la comparativa de los dos escenarios actual y optimizado se puede observar en las Fig. 5 y 6 Escenarios Central Mazar.
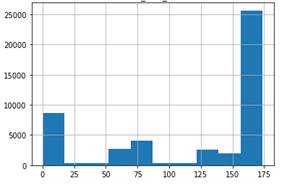
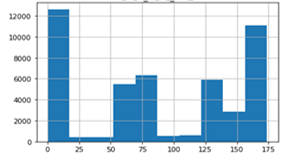
Par el caso de la Central Molino, la comparativa de los dos escenarios actual y optimizado se puede observar en las Figs. 7 y 8 Escenarios Central Molino.
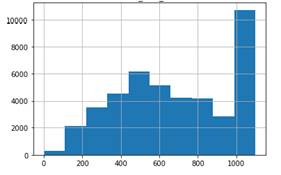
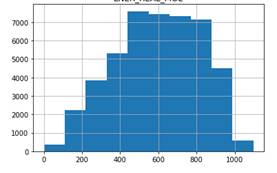
De este análisis se concluye que podría existir un incremento de generación de energía aplicando el modelo predictivo de recomendación con una seguridad del 94% para el caso de la central Molino y 96% para el caso de la Central Mazar.
Para el caso de la central Sopladora, depende directamente de la producción de energía de la Central Molino y por ende de los niveles de la cámara de interconexión; por tanto, no se modela una optimización para esta central, simplemente se modela el estado actual.
CONCLUSIONES Y RECOMENDACIONES
Durante la ejecución del piloto se realizó una comparación entre los valores predichos, los valores reales y los valores estimados por el organismo encargado de regular el despacho energético del Ecuador (CENACE). Cabe recalcar que los valores predichos del algoritmo de recomendación cumplen con la optimización esperada y denotan un incremento en la generación de energía durante el periodo de invierno.
Para el caso de la central Mazar, cuando la cota llega al valor de vertimiento inminente que corresponde a 2.151,5 m.s.n.m. el modelo predictivo recomienda el valor máximo de generación, esto es potencias cercanas a los 170 MW.
Así mismo, cuando no existen unidades disponibles para la generación, el valor predicho es 0 y cuando la cota está llegando a su valor mínimo de operación 2.105 m.s.n.m y tiene poco caudal de entrada al embalse, y existe una máquina disponible, el algoritmo respeta la generación mínima factible de 65 MWh acorde a lo esperado.
Para el caso de la Central Molino, cuando la cota llega al valor de vertimiento inminente que corresponde a 1.989 m.s.n.m. el modelo predictivo recomienda el valor máximo de generación; esto es, el máximo valor de generación 1.100 MWh menos el 5% de la potencia como reserva rodante, requerido por AGC. Así mismo, cuando no existen unidades disponibles para la generación, el valor predicho es 0 y cuando la cota del embalse está llegando a su valor mínimo de operación 1.975 m.s.n.m y tiene poco caudal de entrada, y existe una máquina disponible, el algoritmo respeta la generación mínima factible de 25 MWh acorde a lo esperado.
Para la central Sopladora no se generó ninguna optimización. Para el test, se consideraron cinco escenarios reales en los que se probó el algoritmo planteado vs el algoritmo del CENACE. Los datos predichos del algoritmo planteado en tres escenarios tuvieron menor diferencia respecto al despacho real en comparación con la predicción del algoritmo del CENACE.
Finalmente, es importante recalcar que los factores determinantes para la predicción adecuada son la cota, el caudal de entrada y las unidades de generación.

