











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
Las enfermedades orales representan un desafío significativo para la salud pública global, afectando particularmente a las poblaciones menos privilegiadas debido a su alta prevalencia. Los costos de tratamiento suelen ser prohibitivamente altos y siguen siendo inaccesibles en muchos países de ingresos bajos y medianos. Según la Organización Mundial de la Salud, la gestión de las enfermedades orales se clasifica como la cuarta condición de salud más costosa en las naciones altamente urbanizadas. Dada su profunda repercusión en la salud general, la salud oral es un determinante esencial del bienestar humano y un componente crítico de la atención sanitaria. Además, la presencia de enfermedades orales aumenta el riesgo de padecer condiciones crónicas como diabetes, problemas respiratorios y enfermedades cardiovasculares y cerebrovasculares [1].
El aprendizaje automático (AA), una subcategoría de la inteligencia artificial (IA), emplea técnicas estadísticas, probabilísticas y de optimización que permiten a las máquinas aprender a partir de datos históricos, adquirir información y realizar predicciones sobre nuevos datos basándose en la información aprendida [2,3]. Dentro de la toma de decisiones clínicas dentales, los métodos basados en el aprendizaje profundo (AP), otra subcategoría de la IA, agilizan los procesos y abordan desafíos complejos. Entre estos métodos, una red neuronal convolucional profunda (RNC), un algoritmo bien definido en AP ha demostrado ser altamente efectiva para la segmentación de órganos y la clasificación y detección de órganos y enfermedades en imágenes médicas [4-6].
El aprendizaje automático (AA) ha demostrado una notable precisión y exactitud, superando el juicio humano en la predicción de resultados médicos [2]. Las técnicas de aprendizaje profundo (AP) ofrecen ventajas sobre los métodos basados en características en el análisis de imágenes médicas, superando consistentemente a los profesionales de la salud en la identificación de enfermedades [7].
En el campo del diagnóstico del cáncer oral, el aprendizaje profundo (AP) ha producido resultados prometedores en el análisis automatizado de patología, la obtención de imágenes de la cavidad oral, la imagenología mediante endomicroscopía láser confocal y la imagenología por fluorescencia. Estos avances facilitan la predicción del riesgo de cáncer y los resultados diagnósticos de los pacientes, permitiendo la identificación de patrones sutiles dentro de grandes conjuntos de datos ruidosos. El objetivo final es desarrollar herramientas para mejorar la salud dental pública [2], [7, 8].
Este artículo tiene como objetivo implementar un modelo para el diagnóstico del cáncer oral utilizando algoritmos de aprendizaje profundo (AP) de alto rendimiento. El modelo propuesto tiene el potencial de ser un recurso valioso en el proceso de toma de decisiones para el diagnóstico de esta enfermedad.
Revisión de la literatura
La revisión sistemática de la literatura se llevó a cabo utilizando la metodología PRISMA. Este enfoque facilitó una comprensión integral del trasfondo de la investigación, respaldó este trabajo y demostró la competencia en enfoques de aprendizaje automático (AA) y aprendizaje profundo (AP), asegurando así la relevancia del estudio [9].
El estudio presentado en [2] desarrolla y valida cuatro modelos de aprendizaje automático (AA) para predecir la ocurrencia de metástasis en los ganglios linfáticos en el carcinoma de células escamosas de la lengua oral (OTSCC) en etapa temprana, tanto antes como después de la cirugía. Los modelos de bosque aleatorio y máquina de vectores de soporte muestran un rendimiento predictivo superior en comparación con los métodos tradicionales basados en la profundidad de invasión, la proporción de neutrófilos a linfocitos o la gemación tumoral.
En una investigación separada [4], los científicos automatizan el diagnóstico de quistes y tumores odontogénicos en ambas mandíbulas utilizando radiografías panorámicas. Mejoran una CNN profunda modificada derivada de YOLOv3 para detectar y clasificar estas condiciones. El rendimiento general de la clasificación de enfermedades mejora al utilizar una CNN con un conjunto de datos aumentado en comparación con un conjunto de datos no aumentado.
Mobile Net
MobileNet utiliza convoluciones separables en profundidad, una técnica que reduce significativamente el número de parámetros en comparación con las redes que utilizan convoluciones regulares con la misma profundidad. Esta reducción de parámetros permite la creación de redes neuronales profundas y ligeras. Desarrollado por Google como una clase de CNN de código abierto, MobileNet es una excelente base para el entrenamiento de clasificadores. Los clasificadores generados con MobileNet no solo son compactos y rápidos, sino que también ayudan a minimizar el tamaño del modelo y los requisitos computacionales. Esto se logra reemplazando los filtros de convolución estándar por convoluciones profundas y puntuales [10].
Métricas de rendimiento
Curvas de características operativas del receptor (ROC): Las curvas ROC son representaciones gráficas ampliamente utilizadas para evaluar y comparar el rendimiento de los clasificadores. Estos gráficos bidimensionales ilustran el compromiso entre la sensibilidad y la especificidad en las predicciones de un clasificador. Demuestran visualmente el rendimiento del clasificador a través de varios umbrales de discriminación, facilitando la clasificación y selección de clasificadores según los requisitos específicos del usuario. Estos requisitos frecuentemente incluyen consideraciones de costos diferenciales de error y demandas de precisión [11].
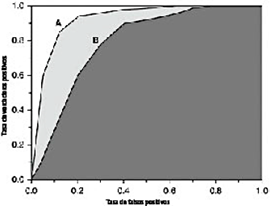
Área bajo la curva (AUC): AUC es un valor escalar único que proporciona una medida integral del rendimiento global de un clasificador binario. El valor de AUC varía de 0.5 a 1.0, donde el valor mínimo indica el rendimiento de un clasificador aleatorio, y el valor máximo corresponde al de un clasificador perfecto. En la Figura 1, se presentan las curvas ROC para dos clasificadores de puntuación, A y B. En este ejemplo, el clasificador A tiene un valor de AUC mayor que el clasificador B [12].
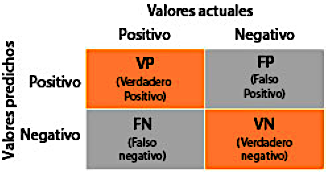
Matriz de confusión: Una matriz de confusión es una representación tabular que muestra la clase verdadera y la clase predicha de cada caso en el conjunto de pruebas. Esta matriz es esencial para evaluar el rendimiento de un modelo en un problema de clasificación. Al presentar una descomposición clara de verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos, permite una comprensión detallada del rendimiento del modelo a través de diferentes clases. La Figura 2 proporciona una representación visual de la matriz de confusión, diseñada específicamente para un problema de clasificación binaria [13].
Exactitud: Un método de prueba se considera preciso cuando mide con exactitud lo que se pretende medir. En otras palabras, puede determinar de manera efectiva la cantidad o concentración exacta de una sustancia dentro de una muestra [14].
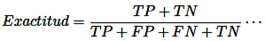 (1)
(1)Precisión: La precisión en un método de prueba se logra cuando las determinaciones o análisis repetidos sobre la misma muestra arrojan resultados consistentes. En el contexto de la exactitud, un método de prueba preciso exhibe una variación aleatoria mínima, lo que aumenta la confianza en su fiabilidad. La capacidad del método de prueba para reproducir resultados consistentemente a lo largo del tiempo subraya su dependabilidad [14].
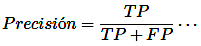 (2)
(2)Sensibilidad: Denota la capacidad de una prueba diagnóstica para detectar correctamente a los individuos afectados por una enfermedad o trastorno específico. Una prueba con alta sensibilidad minimiza las instancias de "falsos negativos", en las que la prueba no logra identificar la presencia de una enfermedad a pesar de su existencia real [14].
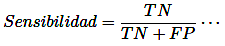 (3)
(3)Puntuación F1: Integra las mediciones de precisión y sensibilidad en una métrica unificada, facilitando una evaluación comparativa del rendimiento general a través de diversas soluciones. La puntuación F1 opera bajo la suposición de que tanto la precisión como la sensibilidad tienen igual importancia [15].
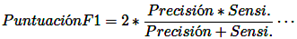 (4)
(4)Cáncer oral
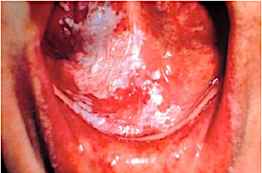
El cáncer oral incluye tumores malignos que afectan el labio, diferentes áreas de la boca y la orofaringe, como se muestra en la Figura 3. Esta forma de cáncer es más común en hombres y personas mayores, con diferencias significativas asociadas con el nivel socioeconómico. Curiosamente, en algunos países de Asia y el Pacífico, el cáncer oral se encuentra entre los tres tipos de cáncer con mayor incidencia [16].
Materiales y métodos
Adquisición de datos
El conjunto de datos utilizado en este estudio fue adquirido de la plataforma web Kaggle [17], que ofrece acceso abierto a datos descargables. El formato original de los datos consistía en imágenes jpg. El conjunto de datos incluía 131 casos, con 87 presentando imágenes de labios, membranas mucosas y la cavidad oral indicativas de cáncer oral, y los 44 restantes mostrando imágenes sin cáncer oral. La Figura 4 resume visualmente la metodología de investigación, delineando claramente las fases. La implementación de esta etapa se detalla en la Sección 2.6.1.
Partición del conjunto de datos
La partición del conjunto de datos implica una división no superpuesta de los datos disponibles en dos subconjuntos distintos: el conjunto de datos de entrenamiento y el conjunto de datos de validación. Esta separación proporciona un subconjunto para propósitos analíticos y otro para la verificación del modelo.
Conjunto de entrenamiento: El conjunto de datos de entrenamiento constituye el 90 % del conjunto total de datos, abarcando 118 imágenes de labios, mucosa y cavidad oral. Esto incluye 78 imágenes indicativas de cáncer oral y 40 imágenes sin signos de cáncer oral.
Conjunto de validación: El conjunto de datos de validación comprende el 10 % del conjunto total de datos, con 13 imágenes de labios, mucosa y cavidad oral. Esto incluye 9 imágenes indicativas de cáncer oral y 4 imágenes sin signos de cáncer oral.
La implementación de esta etapa se detalla en la Sección 2.6.2.
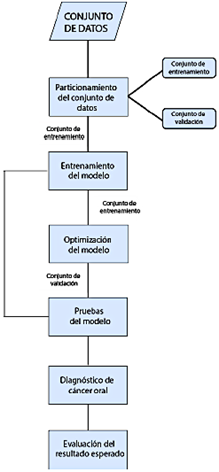
Entrenamiento, optimización y pruebas del modelo
El modelo de red neuronal convolucional (RNC) propuesto en este estudio fue implementado y entrenado en la plataforma Kaggle, utilizando Python como lenguaje de programación, debido a sus extensas capacidades en aprendizaje automático (AA) y aprendizaje profundo (AP). Estas características hacen que Python sea particularmente adecuado para gestionar las complejidades de la tarea. Durante esta fase, el conjunto de datos de entrenamiento sirvió no solo para el entrenamiento inicial, sino también para la prevalidación del modelo, sentando así las bases para una mayor optimización y pruebas.
Al validar el modelo desarrollado, que exhibe métricas de rendimiento que oscilan entre 0,5 y 1,0, se identifican las áreas que requieren mejora para optimizar su rendimiento. Se realizan ajustes utilizando el conjunto de datos de entrenamiento. Una vez que se logran métricas de evaluación satisfactorias, el modelo se somete a pruebas para verificar su efectividad y fiabilidad.
Para evaluar el modelo propuesto, se emplea el conjunto de datos de validación para confirmar su alto rendimiento. Si los resultados difieren de las expectativas, se realizan iteraciones adicionales de entrenamiento, optimización y pruebas hasta que se logren los resultados deseados. Este proceso iterativo se documenta en las secciones 2.6.3 y 2.6.4.
Diagnóstico de la enfermedad del cáncer oral
Basándose en los resultados de rendimiento obtenidos de las pruebas del modelo, se determina la capacidad para el diagnóstico automático del cáncer oral. Este diagnóstico se refiere a las imágenes de los labios, mucosa y cavidad oral utilizadas en el modelo. La implementación de esta etapa se detalla en la sección 2.6.5.
Evaluación del resultado esperado
Después del diagnóstico de cáncer oral, los resultados obtenidos se evalúan comparando su exactitud, precisión, sensibilidad y puntuación F1. A través de esta comparación, se determina que el diagnóstico proporcionado por el modelo propuesto arroja resultados satisfactorios. La implementación de esta etapa se detalla en la sección 2.6.6.
Implementación
Carga de bibliotecas y lectura de datos
El desarrollo de la solución comienza con la carga de bibliotecas esenciales, como matplotlib, NumPy y pandas. Se definen parámetros globales y se obtienen imágenes de los labios, mucosa y cavidad oral, ya sean indicativas de la enfermedad o no. Los parámetros clave incluyen:
Tamaño: Tamaño de entradae [18].
Épocas: El número de iteraciones sobre el conjunto de datos completo [19].
Tamaño del lote: División del conjunto de datos en múltiples lotes más pequeños [19].
Pliegues: El número de pliegues en los que se dividirá el conjunto de datos [20].
Generación del conjunto de datos
Se crea un conjunto de datos que comprende imágenes de labios, membranas mucosas y la cavidad oral, con o sin la enfermedad. Las imágenes se redimensionan y su cantidad se aumenta mediante diversas alteraciones, incluyendo recorte, ajuste de enfoque, rotación, modificación de brillo y volteo.
El conjunto de datos, inicialmente desequilibrado con 44 casos sin cáncer oral y 87 casos con cáncer oral, se somete a un balanceo de clases. Se determinan las clases para identificar la presencia o ausencia de la enfermedad, y las imágenes se segmentan según si muestran o no cáncer oral.
Creación de un modelo
El modelo de RNC propuesto se establece utilizando "MobileNet" como la arquitectura elegida. Además, se emplean los siguientes atributos:
Early Stopping: Configurado con una paciencia de “10” ciclos de entrenamiento, este atributo monitorea una métrica específica para detectar cualquier signo de mejora antes de concluir [21].
Adam: Este optimizador implementa el algoritmode Adam, un método de descenso de gradiente estocástico, basado en la estimación adaptativa de momentos de primer y segundo orden [22].
Sequential: Este atributo proporciona funciones de entrenamiento e inferencia para el modelo [23].
Conv2D: Una capa de convolución 2D que genera un kernel de convolución que se aplica sobre las capas de entrada, produciendo un tensor de salida [24].
Relu: Aplicado para activar la función de activación de unidad lineal rectificada [25].
MaxPooling2D: Este atributo realiza una operación de pooling máximo para datos espaciales 2D [26].
Flatten: Utilizado para aplanar la entrada sin afectar el tamaño del lote [27].
Dense: Esta capa aplica pesos a todos los nodos de la capa precedente [28].
Dropout: Durante el entrenamiento, este atributo configura aleatoriamente unidades de entrada a 0 con una frecuencia especificada en cada paso, ayudando a prevenir el sobreajuste [29].
SoftMax: Convierte un vector de valores en una distribución de probabilidad [25].
Compile: Un método que acepta un argumento de métrica y una lista de métricas [30].
Categorical cross entropy: Este atributo calcula la pérdida de entropía cruzada entre etiquetas y predicciones [31].
Accuracy: Calcula la frecuencia con la que las predicciones coinciden con las etiquetas [32].
Entrenamiento con K-fold
El entrenamiento del modelo se ejecuta utilizando los siguientes atributos:
K-fold: El conjunto de datos se divide en K pliegues, donde cada pliegue sirve como el conjunto de prueba, mientras que el resto del conjunto de datos se utiliza como conjunto de entrenamiento [33, 34].
Stratified Fold: Este atributo asegura una mayor validación cruzada, preservando la distribución de clases en el conjunto de datos, tanto en las divisiones de entrenamiento como de validación [35].
To categorical: Convierte un vector de clases (enteros) en una matriz de clases binarias [36].
Image Data Generator: Este atributo facilita la generación de bloques de entrenamiento y realiza el aumento de datos, incrementando el número de imágenes mediante modificaciones como zum, escalado, volteo horizontal, etc. [37].
Fit: Esta función se utiliza para entrenar el modelo durante un número fijo de épocas (iteraciones sobre un conjunto de datos) [38].
Model Checkpoint: Sirve como un callback para guardar el modelo o los pesos del modelo de Keras en intervalos especificados [39].
Create model: Esta función es responsable de crear y entrenar una nueva instancia del modelo [40].
De manera similar, se propone otra RNC para crear el modelo, utilizando "ResNet152V2," "DenseNet121" y "EfficientNetB6" como las arquitecturas elegidas. La Tabla 1 ilustra una comparación del rendimiento del modelo utilizando estas arquitecturas de aprendizaje profundo.
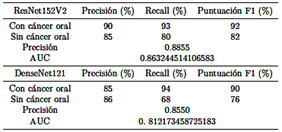
Con respecto al uso de "Efficient Net B6", surge un problema de memoria al comienzo del pliegue 3 durante el entrenamiento del modelo, lo que impide la finalización del proceso.
De manera similar, aunque los resultados del modelo utilizando las arquitecturas "Res Net 152V2", "Dense Net 121" y "Mobile Net", en el mismo conjunto de datos, son comparables, el número de hiperparámetros utilizados en MobileNet es menor. Las Figuras 5, 6, y 7 ilustran el número de hiperparámetros obtenidos para cada arquitectura:
"ResNet152V2" utilizó 76MM, como se muestra en la Figura 5.

"DenseNet121" utilizó 24MM, como se muestra en la Figura 6.

"MobileNet" utilizó 24MM, como se muestra en la Figura 7.

Verificación del modelo
El proceso de verificación del modelo se realiza utilizando todo el conjunto de datos de validación, empleando los siguientes atributos:
Evaluate: Esta función devuelve el valor de pérdida y los valores métricos del modelo en modo de prueba [38].
Predict: Genera predicciones de salida para las muestras de entrada [38].
Confusion matrix: El cálculo de la matriz de confusión se utiliza para evaluar la precisión de una clasificación [41].
Subplot: Este atributo obtiene la posición del índice en una cuadrícula con "n" filas y "n" columnas [42].
Heatmap: Se utiliza para obtener un mapa de calor de activación de clases para un modelo de clasificación de imágenes [43].
Set-ticklabels: Esta función establece los nombres de destino para la matriz de confusión.
Roc curve: Este atributo calcula la curva ROC [44].
Roc-auc-core: Calcula el AUC de la curva ROC a partir de las puntuaciones de predicción [45].
Trazado de curvas AUC
La Figura 8 muestra un gráfico de la tasa de verdaderos positivos frente a la tasa de falsos positivos, ilustrando el AUC a través de líneas. Esta visualización permite observar la relación entre estas dos variables.
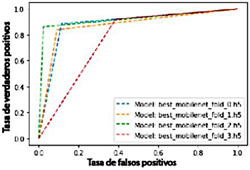
Se confirma que el modelo de RNC propuesto demuestra un alto rendimiento en la clasificación de la presencia y ausencia de cáncer oral.
Resultados y discusión
La Figura 9 ilustra el gráfico de los valores de precisión frente al número de épocas, utilizando líneas para visualizar la relación entre estas dos variables.
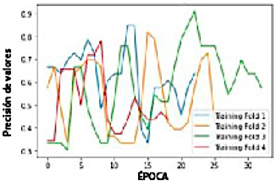
Al entrenar el modelo, se obtiene la precisión para cada pliegue.
En el primer entrenamiento, con el pliegue 1, se logra una "precisión de valor" de 0,84848.
En el segundo entrenamiento, con el pliegue 2, se logra una "precisión de valor" de 0,81818.
En el tercer entrenamiento, con el pliegue 3, se logra una "precisión de valor" de 0,90909.
En el cuarto entrenamiento, con el pliegue 4, se logra una "precisión de valor" de 0,78125.
Se observa que el pliegue 1 alcanza una buena "precisión de valor"; el pliegue 2 disminuye la "precisión de valor"; el pliegue 3 alcanza la mayor "precisión de valor" con un valor de 0,90909, y el pliegue 4 disminuye la "precisión de valor".
Durante la validación del modelo, se obtienen las siguientes métricas para el modelo guardado como “best mobilenet fold 0.h5,” como se ilustra en la Tabla 2.
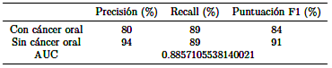
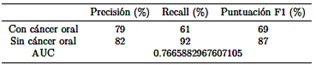
El archivo “best mobilenet fold 1.h5” alcanza las siguientes clasificaciones, como se muestra en la Tabla 3.
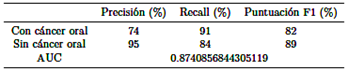
El archivo “best mobilenet fold 2.h5” alcanza las siguientes clasificaciones, como se muestra en la Tabla 4.
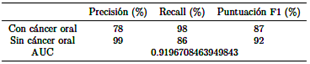
El archivo “best mobilenet fold 3.h5” alcanza las siguientes clasificaciones, como se muestra en la Tabla 5.
Se concluye que el modelo “best mobilenet fold 2.h5” se destaca como la opción óptima, exhibiendo la mayor precisión (78 % y 99 %), sensibilidad (98 % y 86 %), puntuación F1 (87 % y 92 %) y AUC (0,9196708463949843) tanto para casos no cancerosos como cancerosos, superando el rendimiento de otros modelos.
Comparativamente, entre las arquitecturas "ResNet152V2", "DenseNet121" y "MobileNet", se demuestra que la arquitectura "MobileNet" es óptima en términos de optimización de recursos, utilizando veinte millones de hiperparámetros, mientras que las arquitecturas "ResNet152V2" y "DenseNet121" utilizan un número significativamente mayor de hiperparámetros.
Además de las métricas de rendimiento de las arquitecturas “ResNet152V2”, “DenseNet121” y “EfficientNetB6” evaluadas, el modelo presentado en [7] demostró una precisión de 84,3 %, una sensibilidad de 83,0 %, una puntuación F1 de 83,6 % y un AUC de 0,8974. En contraste, el modelo propuesto en este estudio mostró mejoras, logrando una precisión de 88,5 %, una sensibilidad de 92,0 %, una puntuación F1 de 89,5 % y un AUC de 0,9196708463949843. Por lo tanto, se observa una mejora notable en el rendimiento general, que oscila entre el 2 % y el 9 %.
Conclusiones
Este estudio resalta el potencial de la IA para abordar problemas de salud oral, particularmente el cáncer oral, que afecta a una parte significativa de la población. La investigación enfatiza la efectividad del aprendizaje profundo (AP) y concluye que las redes neuronales convolucionales (RNC) son un algoritmo adecuado de AP para procesar imágenes de la mucosa y la cavidad oral. Las RNC toman estas imágenes como entrada y asignan pesos a elementos específicos para distinguir entre ellos. La elección de la RNC MobileNet se justifica por su capacidad para reducir el tamaño del modelo y la computación al reemplazar los filtros de convolución estándar con convoluciones profundas y puntuales.
El estudio utiliza la plataforma de código abierto Kaggle e implementa el modelo utilizando el lenguaje de programación Python. La evaluación de varias métricas de rendimiento arroja una precisión de 0,90909, confirmando que el modelo de RNC propuesto demuestra un alto rendimiento diagnóstico para el cáncer oral. En cuanto a la cantidad de imágenes, el estudio especifica que el uso de más imágenes mejora los resultados del modelo de AP propuesto. Además, la evaluación de diferentes arquitecturas de RNC ayuda a comprender su rendimiento, facilitando la determinación del modelo más óptimo.
En última instancia, esta investigación afirma que el modelo desarrollado está listo para su aplicación práctica, ofreciendo un valioso apoyo para la toma de decisiones dentales en escenarios de diagnóstico en tiempo real.
Trabajo futuro
Los esfuerzos continuados en la recolección de más imágenes de labios, mucosa y cavidad oral que representen diversas condiciones orales, incluido el cáncer oral, serán un punto focal para estudios futuros. Se cree que aumentar el conjunto de datos de imágenes y colaborar con instituciones clínicas públicas y privadas para su evaluación mejorará significativamente los resultados y facilitará la aplicación práctica del modelo. Reconociendo el papel crucial de los grandes conjuntos de datos en la optimización de los algoritmos de aprendizaje profundo (AP), los resultados actuales son prometedores y sirven como un primer paso para avanzar en esta línea de investigación. Además, los próximos esfuerzos de investigación se centrarán en evaluar el rendimiento del método de RNC propuesto en el diagnóstico de un espectro más amplio de enfermedades orales.

