











 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO  uBio
uBio 
 Permalink
Permalink
INTRODUCCIÓN
El cacao (Theobroma cacao L.) es un producto importante a nivel mundial que requiere una atención adecuada que conduzca a que los productos derivados de él sean de buena calidad. Para ello, la fermentación es un paso crítico ya que permite el desarrollo del sabor de sus granos [1], involucrando a componentes como aminoácidos libres, azúcares y péptidos bajo proteólisis [2]. De hecho, los precursores del sabor del cacao se crean durante el procesamiento primario de los granos, lo que incluye la fermentación y el secado [3]. Esto significa que los procesadores requieren de una fermentación completa de los granos de cacao porque aseguran el desarrollo de los precursores del aroma y del sabor [4]. Por lo tanto, la fermentación de los granos de cacao mejora la calidad final del producto, de lo cual depende su valor en los mercados.
Las técnicas de fermentación van desde almacenar el grano de cacao en sacos y que el proceso de fermentación se cumpla, hasta realizar el proceso completo con maquinaria especializada. Cada una de las técnicas da como resultado un grano con diversa calidad de fermentación, razón por la cual, reconocer de manera adecuada la calidad de fermentación es importante para la comercialización de los granos de cacao [4]. Una de las técnicas tradicionales que se usa para reconocer la calidad de fermentación es la “Prueba de corte”, que se la realiza de forma manual y una persona determina la calidad de fermentación. El método es simple. Consiste en cortar una selección de granos de cacao longitudinalmente por el centro para controlar y evaluar su calidad [5], pero requiere de mucho tiempo y se considera subjetivo [6]. Por esta razón, es útil disponer de herramientas que permitan determinar la calidad de fermentación de los granos de cacao de manera económica y ampliamente estandarizada, pudiendo encontrar alguna opción en las Ciencias de la Computación y, en particular, en la Inteligencia Artificial (IA).
En general, las investigaciones relacionadas con la IA en el ámbito de la agricultura se han popularizado en años recientes. Para que ello sea posible, ha sido necesario recurrir a técnicas como el aprendizaje automático (ML, Machine Learning) y el Aprendizaje profundo (DL, Deep Learning). El ML es capaz de producir un comportamiento utilizando algoritmos que a su vez son alimentados por una gran cantidad de datos [7]. Por su parte, el DL es un subconjunto de ML que se utiliza para comprender conceptos de mayor precisión, como la creación de clasificadores robustos y la elección de técnicas de extracción de características que debe medirse cuidadosamente para proporcionar información representativa al clasificador [8]. A esto se le puede agregar las redes neuronales convolucionales (CNN, Convolutional Neural Network) que han demostrado ser útiles para la detección de objetos y la clasificación de imágenes [9, 10, 11, 12]. Estas pueden ser aplicadas en la clasificación de imágenes de manera más eficiente [13], logrando además aprovecharlas en otras tareas que requieren menos datos de entrenamiento [14].
A partir de este tipo de técnicas de IA se han llevado a cabo varios trabajos para analizar imágenes en el ámbito agrícola [15][16], llegando incluso a la posibilidad de suplantar a los métodos tradicionales como la “Prueba de corte” [17]. Una primera opción es emplear CNN para extraer características de los granos de cacao. Para ello, Adhitya et al. [8] utilizaron imágenes de granos de cacao de diferentes niveles de calidad, logrando, con cinco capas de CNN, clasificar siete tipos de imágenes con una tasa de precisión del 82 %. Otra opción es usar la visión por computadora como un método rápido y preciso para clasificar los granos de cacao fermentados. En este caso, se dividieron los granos seleccionados en cuatro etapas de fermentación empleando bosques aleatorios y alcanzando una precisión superior al 80 % [1]. Otros trabajos más recientes se han limitado a clasificar los granos de cacao como saludables o enfermos [18]. En definitiva, estos trabajos son una muestra de la utilidad de la IA aplicada al cacao, pero es necesario también analizar su idoneidad con muestras e imágenes de cacao de otras regiones, como en el caso del cacao ecuatoriano.
Teniendo en cuenta este contexto y centrándose en la agricultura ecuatoriana, surge la pregunta: ¿Cómo identificar la calidad de fermentación en los granos de cacao ecuatoriano? Para responderla, este trabajo se basa en el uso de IA, y en particular de CNN; es decir, se tiene como objetivo diseñar un modelo de clasificación de imágenes empleando una técnica de DL para medir la calidad de fermentación de los granos de cacao ecuatoriano y seleccionar la mejor opción para reconocer patrones a partir de la información digital. Con esto se busca llegar a una identificación de la calidad de la fermentación de los granos de cacao más precisa, en comparación con las técnicas tradicionales. Así, se aspira a aportar en la selección de la técnica que permita mejorar los tiempos al momento de reconocer la calidad de fermentación y para que este no vea afectado su precio en los mercados.
MATERIALES Y MÉTODOS
En términos generales, el estudio se basó en el uso del algoritmo CNN de Deep Learning dedicado al reconocimiento de imágenes, enfocado a la calidad de fermentación de los granos de cacao. CNN es una red neuronal artificial que imita el funcionamiento del ojo humano para identificar objetos o características, fragmenta las imágenes y se entrena usando capas especializadas [19, 20]. El algoritmo obtiene las características sobre la calidad de fermentación desde una base de conocimiento con imágenes clasificadas en los cuatro tipos de calidad de fermentación. Además, se empleó el análisis de texturas GLCM (Gray Level Co-Occurrence Matrix) como método estadístico que permite caracterizar la textura de una imagen calculando la frecuencia con la que se producen pares de pixeles con valores específicos en un espacio de la imagen [21]. A continuación, se describen más detalles del estudio.
Conjunto de datos
Las imágenes utilizadas en el estudio fueron obtenidas a partir de granos de cacao recolectados en Quevedo, Ecuador. Los granos de la muestra estaban secos para una obtención adecuada de las imágenes. Estos granos fermentados fueron clasificados manualmente por docentes de Ingeniería Agrícola/Agronómica, expertos en el tema, y pertenecientes a la misma institución de los autores, utilizando la prueba de corte. Para ello, se aplicó la norma ecuatoriana INEM 176:2006 [22] a todos los granos de la muestra; es decir, se clasificaron en buena fermentación, mediana fermentación, grano violeta, grano pizarroso y grano mohoso. Sin embargo, el conjunto de datos no dispuso de imágenes para el tipo de fermentación pizarroso. Así, el conjunto de datos resultante tuvo 212 imágenes, teniendo en cuenta lo realizado en otro trabajo [23].
Procesamiento de datos
Previo al análisis necesario, se efectuó un preprocesamiento de datos. Se leyeron las imágenes de entrada, seguidas de un proceso de reescalado aplicado a todas las imágenes del conjunto de datos [24]. Las imágenes, categorizadas en los cuatro tipos de calidad de fermentación citadas, se organizaron en carpetas de archivos para facilitar su lectura y procesamiento desde el software usado.
Preparación del conjunto de datos
Las imágenes recolectadas se usaron para entrenar la red neuronal convolucional, empleando las categorías como los objetos de experimentación. Para ello fue necesaria una preparación preliminar debido a que las imágenes a ingresar al modelo formulado deben ser del mismo tamaño, y generalmente no se ingresan imágenes de alta resolución, sino de dimensiones reducidas, puesto que mientras mayor sea el tamaño de la imagen, mayor será el poder computacional requerido y el tiempo de entrenamiento del modelo. Además, para el tipo de imagen de este trabajo en el que los patrones a detectar son detalles muy pequeños en la imagen, es necesario que la imagen tenga un tamaño considerable. Así, para mantener un equilibrio, una vez que la imagen tuvo la forma deseada se empleó el método resize para redimensionar la imagen a un tamaño de 156 x 256 pixeles, como se observa en la Fig. 1.

Construcción del modelo CNN
Aunque existen varios lenguajes de programación para entrenar modelos de clasificación DL, como R, DeepCC desarrollado en R y C [25], Matlab [26], o Python [27, 28, 29], en este trabajo se eligió Python. El motivo radica en que este lenguaje se destaca como uno de los principales lenguajes de programación en la comunidad para implementar marcos de DL [30] y a que cuenta con librerías de código abierto como Keras, TensorFlow, openCV [27, 29], que facilitan el reconocimiento de imágenes sin necesidad de consumir excesivamente recursos computacionales [31, 32]. Así, y con base en la experiencia previa de los autores y recomendaciones de expertos en el tema, se tomó la decisión de usar Python con las librerías Keras y TensorFlow.
Arquitectura del modelo CNN
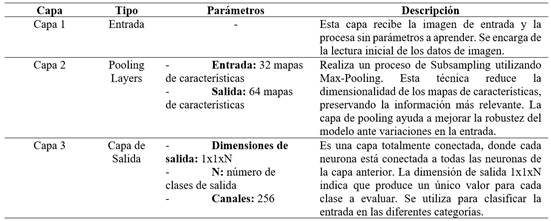
El modelo de CNN construido está compuesto de tres capas principales: una de entrada, una oculta y una de salida. En la Tabla 1 se pueden visualizar los parámetros de cada capa. Ellos fueron fijados tomando en cuenta las características de las imágenes, lo que hizo necesario recortarlas apuntando a conseguir un mejor resultado en el entrenamiento. El primer parámetro es un conjunto de kernels (llamado filtros); por cada filtro se obtiene una matriz de salida. La primera capa (Entrada) solo lee la imagen de entrada por lo que no hay parámetros por aprender aquí. La segunda capa, Pooling layers, toma los mapas de características en la entrada y tiene k mapas de características de salida; son 32 mapas de características como entrada y 64 mapas de características de salida. Los parámetros de las capas Pooling layers son utilizados para realizar un Subsampling con Max-Pooling (como se explica a detalle más adelante). Por último, la capa de salida es una capa normalmente conectada, las dimensiones del volumen de salida son 1x1xN, donde N es el número de clases de salida que se están evaluando, teniendo en cuenta que se tiene 256 canales de dimensión. En esta capa hay una conexión entre todas sus neuronas y con cada neurona de la capa anterior. Además, la planificación de la representación gráfica del modelo, con cada uno de sus parámetros se puede visualizar en la Fig. 2, donde se aprecia la entrada y salida de las neuronas utilizadas en las capas de entrada, ocultas y de salida de los canales de convolución de la red neuronal convolucional.
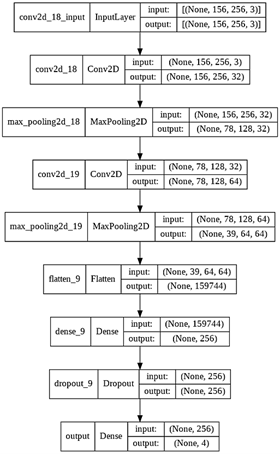
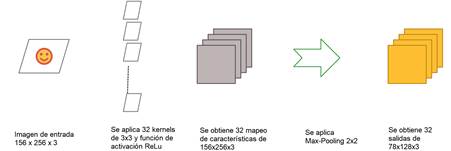
Las imágenes utilizadas como entrada del modelo tienen una dimensión de 156 x 256 pixeles (ancho y alto) con dos canales. Así también, la función de activación utilizada para este modelo es ReLu, la cual se usa tanto en el primero como en el segundo filtro convolucional. Las capas están compuestas por neuronas y estas se conectan a una pequeña región de la capa anterior, lo que quiere decir que no están completamente conectadas [33]. El primer canal utiliza 32 filtros convolucionales de tamaño 3x3, con una resolución del tamaño de un factor 2 y esa capa es llamada MaxPool2D (ver Fig. 3).
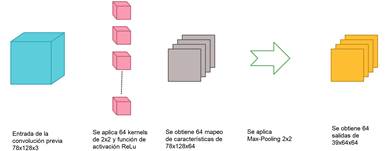
En el segundo canal se utilizaron 64 filtros convolucionales de tamaño 2x2 (ver Fig. 4), con una resolución del tamaño de un factor 2 igual al primer filtro, puesto que dieron los mejores resultados en el entrenamiento. Fue necesario además añadir una nueva capa, llamada “Flatten”. Esta capa permite unir la zona de la capa convolucional con la capa fully connected; todas las neuronas de una capa oculta están conectadas a todas las neuronas de la capa que les precede y sigue [34]. Así, una imagen muy profunda/pequeña pasará a ser plana con la ayuda de esta capa, pasando la información de la red neuronal a estar en una sola dimensión.
En la capa fully connected (Fig. 5) se encuentran las capas densas. Después de aplanar la información, es recibida por una capa normal; es decir, ahora se añade una capa donde todas las neuronas estarán conectadas con las neuronas de la capa pasada. En esta capa serán 256 neuronas. Para evitar el overfitting (que no estén conectadas al 100 % de las neuronas de una capa con respecto a la otra), es necesario utilizar la capa Dropout. En otras palabras, se apagará el 50 % de las neuronas cada paso para evitar llegar a sobre ajustar.
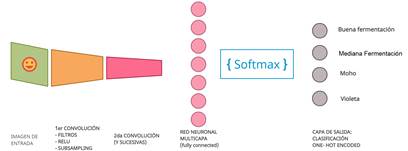
Por último, en la capa de salida es necesario tener la función de activación en “softmax” para que genere el resultado como si fueran probabilidades. Para ello se cuenta con cuatro clases o categorías diferentes y es necesario que la capa de salida tenga el tamaño de ellas. Así, la Fig. 6 muestra el modelo de la red neuronal convolucional.
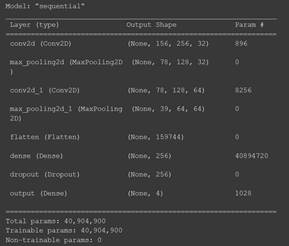
Descripción del modelo CNN
Se usaron métricas para monitorear el proceso de aprendizaje (y prueba) de la red neuronal. En este modelo, solo se consideró la accuracy (fracción de imágenes que son correctamente clasificadas). La función de Ioos especificada fue categorical_crossentropy. La función de Ioos es uno de los parámetros necesarios para cuantificar qué tan cerca está una determinada red neuronal de su estado ideal durante el proceso de entrenamiento. El optimizador utilizado fue el Adaptive moment estimation (Adam) que es una combinación de las bondades de otros dos algoritmos que son AdaGrad y RMSProp [35]. La métrica fue accuracy; con ella se evalúa el porcentaje de aciertos averiguando dónde el modelo predice la etiqueta correcta.
Estructura del entrenamiento del modelo CNN
Para esta parte se utilizó la función modelcnn.fit_generator() que recibe como argumentos las variables train_generator() y validation_generator() asignadas a las funciones training_datagen.flow_from_directory() y test_datagen.flow_from_directory() utilizadas en la creación del modelo. De igual forma, se requiere especificar la cantidad de épocas o veces que se va a repetir el entrenamiento y esa cantidad se encuentra almacenada en la variable “epochs”, que en este caso fue 80 épocas. Los datos de la validación también son necesarios para el entrenamiento del modelo y estos se encuentran en la variable “val_generator”.
A partir del modelo CNN entrenado en el entorno gratuito de Jupyter Notebook, que no requiere configuración y que se ejecuta completamente en la nube (Google Colab) [36], se realizaron varias pruebas para comprobar que este funciona apropiadamente. Con el modelo ya entrenado se realizó la predicción en Google Colab utilizando imágenes de prueba. También, hay que tener presente que el modelo se entrenó con el algoritmo de Descenso de gradientes estocástico (Stochastic Gradient Descent - SGD) [37], aplicando cuatro ensayos de entrenamiento seguidos de 50, 60, 70 y 80 épocas, con una tasa de aprendizaje de 0,0001 del algoritmo de optimización Adam [24] y un minilote [38] de 32. Así, la Tabla 2 detalla las especificaciones de Google Colab usadas.

RESULTADOS
Clasificación
Las tasas de clasificación obtenidas para diferentes números de épocas se presentan en la Tabla 3. Se puede observar que se mantiene el valor de la tasa de clasificación al incrementar el número de épocas, lo cual podría deberse a la cantidad de datos utilizados para el entrenamiento de los modelos CNN. De esta manera, se obtuvo una precisión máxima de 1,0000 para 80 épocas de entrenamiento.

Predicción
Los resultados de la predicción, con base en la calidad de la fermentación, pueden dividirse en dos partes: (1) una evaluación de la robustez y la viabilidad del modelo, y (2) una evaluación de la precisión de la clasificación de granos de cacao [39]. En cuanto a lo primero, la Fig. 7 muestra las variaciones en la precisión y pérdida del entrenamiento durante la época de prueba basada en CNN. Se puede ver que después de 80 épocas, las precisiones de CNN son efectivas. Además, la curva de precisión es efectiva en comparación con la de pérdida [39]. Adicionalmente, la Figura 8 muestra las variaciones en la precisión y pérdida de los datos de validación. Las precisiones después del entrenamiento con 80 épocas son efectivas. Además, la curva de precisión es efectiva en comparación con la pérdida [39, 40].
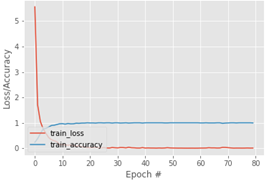
Fig. 7 Pérdida de entrenamiento y precisión en el conjunto de datos con 80 épocas - En relación con los datos de entrenamiento
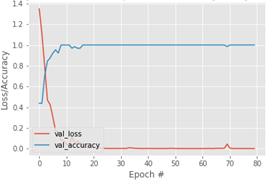
Fig. 8 Pérdida de entrenamiento y precisión en el conjunto de datos con 80 épocas - En relación con los datos de validación
Por otra parte, la Fig. 9 muestra las variaciones en la precisión y pérdida tanto de los datos de entrenamiento como de los de validación. Las precisiones después del entrenamiento con 80 épocas son efectivas para los datos de entrenamiento y validación. Las curvas de precisiones son efectivas comparadas con las curvas de pérdidas [39, 40].
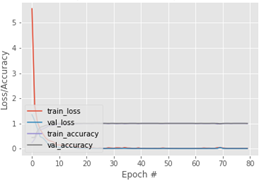
Fig. 9 Pérdida de entrenamiento y precisión en el conjunto de datos con 80 épocas - En relación con los datos de validación y entrenamiento.
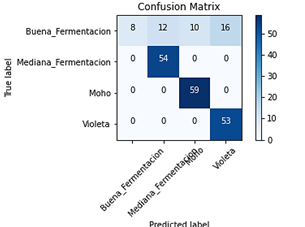
Los resultados de la evaluación de la precisión de la clasificación también pueden dividirse en dos partes. La primera se resume en una matriz de confusión de la muestra, donde se refleja el número de muestras en cada combinación de clase de referencia y clase predicha [41]. La segunda corresponde a las métricas de clasificación del modelo CNN.
La matriz de confusión basada en CNN se muestra en la Fig. 10. Cuanto mayor sea el número de elementos diagonales, mejor será la clasificación [39], mientras los otros muestran el número de clasificaciones inexactas [42]. Haciendo uso de las mismas imágenes de entrenamiento, cada una de las imágenes del conjunto de datos es utilizado como datos de prueba para verificar qué tan efectivo es el entrenamiento. De esta misma figura se desprende que las muestras de buena fermentación se dividen a menudo en las otras clases por error. Esto puede estar relacionado a la cantidad de imágenes del entrenamiento y a que los datos de buena fermentación son muy parecidos a los datos de las otras clases, similar a lo ocurrido en trabajo relacionado [43].
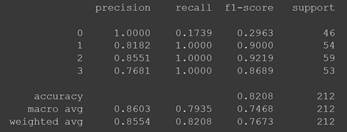
Por otro lado, (Fig. 11) se muestra el detalle de las diferentes métricas de clasificación que se usaron para determinar la exactitud del modelo CNN. Se emplearon las métricas de precision, recall y F1 para cada uno de los tipos de calidad de fermentación. La exactitud para este modelo se ve reflejada en el Accuracy, con un porcentaje de 82 % de exactitud del modelo CNN [44]. Debe notarse también que este valor es comparable con los obtenidos en otros estudios relacionados a cacao como los [8] y [1]. En el primer caso, los autores también reportaron un Accuracy de 82 % utilizando cinco capas, mientras en este trabajo se emplearon solo dos. En el segundo, el valor de Accuracy fue mayor al aquí obtenido gracias al mayor conjunto de imágenes, pero con valores aproximadamente iguales para precision y recall.
DISCUSIÓN
En este trabajo se presentan resultados prometedores para la clasificación automática de granos de cacao, pero hay algunos aspectos sobre los cuales se puede reflexionar. En primer lugar, durante el entrenamiento del modelo CNN se presentaron ciertos errores en la clasificación de las muestras. Esto puede atribuirse al tamaño del conjunto de datos utilizado. La precisión de la visión por ordenador fue excelente a pesar de haber tenido que recortar las imágenes. Después de 80 épocas, el modelo alcanzó una precisión del 82 %, lo cual es aceptable para un conjunto de datos dividido en 4 categorías diferentes. Es de esperar que si se incrementa la cantidad de imágenes (por ejemplo, a mil por categoría), el modelo aprenda las características distintivas de cada categoría, resultando en una clasificación más precisa y una menor confusión entre categorías similares.
En segundo lugar, se podría considerar un incremento en el tamaño del conjunto de datos. Se pueden considerar dos estrategias para abordar en un futuro estudio. La primera opción es incrementar el tamaño del conjunto de datos mediante técnicas de aumento de datos, como rotación, recorte, cambio de iluminación, o adición de ruido [45], lo que permitiría crear variaciones adicionales a partir de las imágenes existentes. Aunque esto podría incrementar el volumen del conjunto de datos derivando en que el modelo generalice mejor las variaciones en las imágenes reales, debe ser verificado con más detenimiento. Esto conduce a pensar en la segunda opción, la captura de imágenes en un entorno controlado. Esta captura puede contribuir a que las características relevantes del grano de cacao sean consistentes entre las diferentes categorías. En definitiva, disponer de más imágenes por categoría, idealmente mil o más, permitirá que el modelo aprenda de manera más efectiva logrando una clasificación más precisa.
En tercer lugar, y a pesar de la limitación antes mencionada, los resultados obtenidos son comparables con otros trabajos. De partida, la precisión aquí reportada es aproximada a la alcanzada por otros autores que emplearon imágenes de cacao de otros países (80 % [1] y 82 % [8]), pero usando conjuntos de datos con mayor cantidad de imágenes. También se puede comparar el rendimiento de CNN, pero con estudios que clasifican otros tipos de granos. Por ejemplo, un estudio centrado en clasificar granos de trigo alcanzó una precisión del 94.88 % en el entrenamiento y un 97.53 % en la prueba, logrando reducir las pérdidas al 15% en el entrenamiento y al 8% en la prueba, pero gracias a un conjunto de 15000 imágenes [46]. Otro trabajo, pero dedicado a la clasificación de granos de café [47], preparó 72 000 imágenes mediante calibración de datos, con 36 000 de granos buenos y 36 000 de granos malos. Seleccionando al azar 7000 imágenes, los autores reportaron una precisión del 94.63 %. Aunque estos valores son superiores a los reportados en este trabajo, hay que rescatar que la precisión lograda es prometedora en comparación con los otros tamaños de los conjuntos de datos.
Finalmente, el modelo puede evolucionar hasta llegar a ser incorporado en una aplicación móvil que facilite el proceso de clasificación. La viabilidad práctica de esta idea está siendo explorada por los autores. Para el efecto, se ha considerado la capacidad de TensorFlow para convertir el modelo a TensorFlow Lite. Esta conversión permite integrarlo sin problemas en una aplicación desarrollada en Android Studio, lo cual es especialmente beneficioso, ya que el modelo entrenado puede funcionar sin necesidad de conexión a Internet. Esto significa que los usuarios pueden acceder a las funcionalidades de la aplicación incluso en áreas remotas donde la señal telefónica es escasa o inexistente. Al eliminar la dependencia de la conectividad, se amplía el rango de aplicaciones posibles, permitiendo que la aplicación se utilice en contextos diversos y reales, como en zonas rurales o durante actividades al aire libre, lo que maximiza su utilidad y accesibilidad.
CONCLUSIONES
Partiendo de la importancia de la clasificación de granos de cacao basada en su calidad de fermentación, en este trabajo se ha abordado la construcción y uso de un modelo CNN de aprendizaje profundo. El aprendizaje profundo, a través del análisis de imágenes, ofrece una opción viable para este tipo de clasificación. Esto se ha evidenciado a partir del desarrollo de un modelo cuyo rendimiento es comparable al de estudios similares, pero con datos de una zona diferente. La exactitud positiva alcanzada por el modelo fue del 82 % empleando un entrenamiento de 80 épocas.
Además, la matriz de confusión reveló que las muestras de mediana fermentación, moho y violeta mantienen una buena clasificación con el número máximo de muestras en los elementos diagonales. Sin embargo, varias de las muestras se dividen a menudo por error en otras clases, lo que podría deberse a que tales muestras son muy similares, teniendo en cuenta la cantidad de datos usada para el entrenamiento. Este aspecto, o en general la precisión del modelo, podría mejorarse al efectuar el entrenamiento con un conjunto de datos mucho más amplio. Independiente de ello, el modelo obtenido podría ser empleado para la construcción de una herramienta de software destinada a profesionales o agricultores interesados en clasificar granos de cacao por su fermentación utilizando, por ejemplo, un teléfono inteligente.
En el futuro se espera abordar estas ideas como una manera de aportar a la sostenibilidad de la industria del grano del cacao, a los agricultores, a los procesadores y en general a quienes dependen de esta fuente de ingresos.
FinanciamientoConflicto de InteresesContribución de Autorías
