











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
1. INTRODUCCIÓN
La salud mental se ha convertido en una temática de interés general a nivel global, dado el impacto que su afectación en la población puede tener en las esferas económicas, políticas sociales y sanitarias. Sin embargo, la salud mental continúa siendo una de las áreas menos atendidas en salud pública, en donde cerca de 1000 millones de personas viven con un trastorno mental, 3 millones de personas mueren cada año por el consumo nocivo de alcohol, y una persona se suicida cada 40 segundos (Organización Mundial de la Salud, 2020).
Adicionalmente, se sabe que una gran parte de los trastornos que padecen las personas son altamente estigmatizados, lo que contribuye significativamente al sufrimiento de los individuos, desincentivando la búsqueda de ayuda profesional y promoviendo el ocultamiento de los síntomas. Ante esta situación, y como alternativa para compartir sus pensamientos y sentimientos relacionados con la alteración en salud mental, las redes sociales se han convertido en un medio para la búsqueda de orientación y ayuda por parte de la comunidad que allí interactúa (Chiong, et al., 2021).
Las redes sociales han tenido un marcado éxito y penetración en la población en general, las cuales son muy populares en adolescentes (Ophir et al., 2019) y frecuentemente usadas por adultos (Mendu et al., 2020). Así mismo, la pandemia del Covid-19 y el aislamiento social trajo consigo que, plataformas como Facebook, Instagram, Twitter y Reddit, fueran mucho más utilizadas, ya que se convirtieron en los canales que permitían mantener la interacción social segura, en medio de la crisis sanitaria (Garg, 2021; Koh & Liew, 2020).
Entre las características de las redes sociales, se identifica que el 80% de los datos en estas plataformas es textual, y crecen diariamente a razón de 1.3 millones de nuevas entradas de contenido (Fernández, 2020). Ante esta gigantesca cantidad de información, surge una serie de estrategias de análisis de datos que hace uso de distintas metodologías (Moessner et al., 2018), algunas básicas como el análisis y frecuencia de palabras clave publicadas por un usuario, y otras más complejas como la interpretación del lenguaje natural (NLP) por medio de la inteligencia artificial (Mori & Haruno, 2021) y el aprendizaje profundo (Wongkoblap et al., 2021; Yao et al., 2020) a través de distintos modelos de redes neuronales (Babvey et al., 2021; Melvin et al., 2019), lo que permite el monitoreo y la perfilación de usuarios, esto resulta muy útil en mercadotecnia, pero también, ventajoso para instituciones educativas, gobiernos y la salud pública en general (Nandhini & Sheeba, 2015).
Estas novedosas posibilidades de análisis de datos han despertado el interés de diversos autores y estudios respecto a la identificación de factores, patrones y modelos que puedan predecir los comportamientos de usuarios (Centola, 2010; Zhang et al., 2013), relacionados con temas de salud pública y salud mental (Camacho et al., 2013; Dos Santos et al., 2019; Mori, & Haruno, 2021;Tan, et al., 2021). Por ejemplo, el estudio realizado por Bae et al. (2021) cuya investigación buscó determinar si el aprendizaje automático podía utilizarse eficazmente para detectar signos de esquizofrenia en usuarios de la red social Reddit, a través de la recopilación de publicaciones y el análisis de textos; o la investigación realizada por Chiong et al. (2021) cuyo objetivo fue determinar si el aprendizaje automático podría usarse de manera efectiva para detectar signos de depresión en usuarios de las redes sociales, a través del análisis de sus publicaciones.
De esta manera, se observa un panorama coherente al formulado por la Organización mundial de la salud (2017), el cual refiere que, las alteraciones en salud mental en los últimos años van aumentando, señalando que 1 de cada 4 personas, a nivel global, sufrirá alguna enfermedad mental durante el trascurso de su vida (Confederación Salud mental de España, 2019) para lo cual resulta interesante tener formas alternativas para su prevención, detección y estudios, que funcionen paralelamente al ejercicio de la psicología clínica y la psiquiatría tradicional.
Es por ello que, a través del presente estudio de revisión sistemática, se buscó examinar documentos científicos que implementaran modelos de análisis del lenguaje natural de textos publicados en redes sociales, para detectar cuáles de ellos han sido más utilizados, qué fenómenos de salud mental fueron los más abordados y las redes sociales más comúnmente usadas como fuente de información, permitiendo conocer el estado actual del problema en cuestión, identificar nuevas tendencias, y promover en los investigadores interesados, la formulación de estudios con impacto disciplinar y social.
2. METODOLOGÍA
En este trabajo, se realizó un análisis de la literatura (Palmatier et al., 2018), basado en la Declaración PRISMA (Moher et al., 2009; Perestelo-Pérez, 2013), el cual inició con la revisión de documentos, y continuó con el uso de un enfoque analítico para la identificación, principalmente, de modelos computacionales del lenguaje natural más utilizados para la identificación de alteraciones en salud mental a través de redes sociales. Se siguieron unas pautas metodológicas formuladas por expertos en este tipo de investigación (Cobo et al., 2011), que permitieron el análisis de resultados basado en un modelo aceptado por la comunidad científica (López-Belmonte et al., 2020).
2.1 Diseño de la investigación
Partiendo de la revisión sistemática como metodología principal del estudio, se llevó a cabo un diseño de investigación para la búsqueda, registro y análisis de la literatura científica (Martínez et al., 2015), el cual fue acompañado de un análisis de co-palabras (Soler-Costa et al, 2021). Los distintos procesos llevados a cabo en este diseño permitieron obtener los subdominios conceptuales que posibilitaron orientar el proceso de interpretación de resultados.
2.2 Procedimiento
El proceso de búsqueda y selección se compuso de cuatro pasos principales: (1) identificación, (2) cribado, (3) elegibilidad (4) inclusión, con el fin de disminuir sesgos en la selección de documentos, tal y como se requiere en este tipo de estudios. Los pasos seguidos fueron los siguientes:
En primer lugar, se seleccionaron las bases de datos para el proceso de búsqueda, entre ellas, Ebsco, Academic Search, APA PsyArticles, APA Psyinfo, ERIC, Fuente Académica, MEDLINE, Engineering Index, Software Reviews on File, Psychology and Behavioral Science Collection, SocINDEX With Full Text, Master File Premier, Medline with Full Text y PsicoDoc, así como también las plataformas Web of Science y Scopus, ya que están consideradas como bases de datos mundiales y contienen un amplio número de estudios de impacto indexados.
En segundo lugar, fueron definidas las palabras a utilizar en la ecuación de búsqueda, en donde inicialmente se revisaron estudios de impacto (Al Asad et al., 2019; Gaur et al., 2019; Katchapakirin et al., 2018), con el propósito de generar una lista de palabras clave para hacerlas parte del proceso de consulta, entre las que se encontraron, en español: procesamiento del lenguaje natural, salud mental y redes sociales; y en inglés: natural language processing, mental health and social network. Lo anterior permitió detectar los documentos científicos que tenían esos términos en el título, el resumen, y palabras clave de las publicaciones indexadas.
En tercer lugar, se estableció la siguiente ecuación de búsqueda en español: “procesamiento del lenguaje natural” AND “salud mental” AND “redes sociales” y para el inglés, “natural language processing” AND “mental health” AND “social network”. Esta ecuación se utilizó para la búsqueda de los títulos de las publicaciones de las bases de datos anteriormente mencionadas. Además, para la selección de categorías de búsqueda en las bases de datos, se escogieron todas aquellas relacionadas con el ámbito de la medicina, ciencias computacionales y psicología.
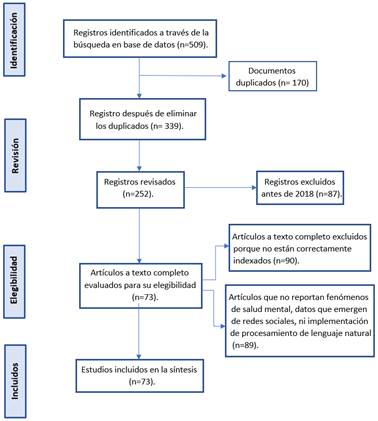
El proceso de búsqueda y reporte se llevó a cabo entre octubre de 2021 a junio de 2023. En el informe se decidió elegir todo tipo de artículos científicos en idiomas inglés y español, y se intentó abarcar una buena parte de la literatura sobre el estado del problema. Estas acciones dieron como resultado un total de 509 publicaciones, de las cuales 170 correspondieron a documentos duplicados. A continuación, para refinar la búsqueda se establecieron varios criterios; como criterio de inclusión se tomaron los años de publicación de los artículos en el periodo 2018 a 2022, y como criterios de exclusión, se separaron aquellos documentos anteriores a 2018 (n=87), documentos mal indexados en las bases de datos (n=90) y estudios que no reportaran fenómenos de salud mental, datos analizados no provenientes de redes sociales, y que no expresaran uso del procesamiento de lenguaje natural (n=89). La aplicación de estos criterios produjo una unidad de análisis de 73 documentos científicos. Las acciones seguidas se muestran en el diagrama de flujo según la declaración PRISMA (Figura 1), en donde se establece el informe de documentos sobre los constructos analizados y las reducciones sufridas por el volumen inicial, tras la aplicación de los criterios establecidos, hasta llegar a la unidad de análisis final establecida en este estudio.
2.3 Análisis de los datos
Todos los artículos finalmente seleccionados (73 en total) fueron analizados y procesados por los investigadores. Se hizo uso de una matriz de sistematización que contempló información referida a: datos de identificación del artículo, estructura teórica y metodológica, y, principales hallazgos. De esta manera, el proceso de análisis permitió la detección de información relacionada con las categorías deductivas definidas: a) redes sociales analizadas, idiomas de publicación y campos de estudio de las publicaciones académicas, b) fenómenos de salud mental más abordados en los estudios y c) modelos de procesamiento del lenguaje natural de textos publicados en redes sociales para la identificación de alteraciones en salud mental; dicha información se obtuvo producto de la concatenación de expresiones comunes, palabras clave, redes de co-palabras (Marín-Marín et al., 2021), extraída de los textos de análisis seleccionados, en las que tres investigadores del presente estudio coincidieron, y cuyos resultados son expresados en las secciones Resultados y Discusión, de este manuscrito.
3. RESULTADOS
Este apartado informa acerca de los resultados obtenidos y relacionados con las categorías deductivas establecidas, que se vinculan a los objetivos definidos para este estudio, otorgando valor en la investigación sobre la detección de enfermedades mentales a través de NLP, cuyo interés, de acuerdo con lo expresado en las investigaciones consultadas, ha ido en crecimiento en los últimos años.
Se iniciará con la presentación de resultados relacionados con metadatos de interés para esta investigación como, año de publicacion de artículos, localización e idioma en el que se desarrolló el estudio, áreas del conocimiento de las revistas en donde fueron publicados las investigaciones, y las redes sociales utilizadas para la extracción de información en dichos estudios; posteriormente, se presentarán los algoritmos usados para el NLP y los fenómenos psicológicos más abordados.
3.1 Años de publicación de los artículos, país de origen e idiomas de publicación de los estudios
En la búsqueda inicial de documentos de investigación publicados entre los años 2018 y 2022, se observa una tendencia dentro del número de estudios publicados sobre el tema por año (Figura 2), y se identifica un aumento sustancial en el número de publicaciones entre el 2021 y el 2022, siendo este último el año en el que se publicó el 46.5% del total de los documentos seleccionados.
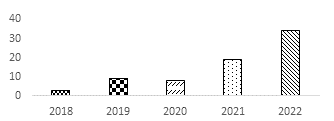
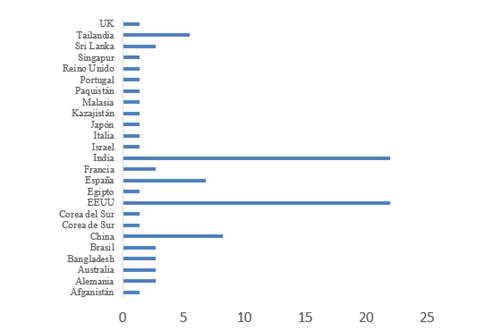
De otro lado, varios países han demostrado su interés en estudiar las alteraciones en salud mental en sus territorios. De los datos extraídos en la presente revisión, se identifica un predominio en el número de publicaciones por parte de EE. UU. (21,9 %), India (21,9 %) y China (8,2 %) (Figura 3); así mismo España destaca como el único país hispano hablante que reporta publicaciones.

El 100% de los documentos incluidos en este estudio se encuentra publicado en inglés. Por su parte, para el análisis de datos, algunas investigaciones utilizaron textos en su lengua materna (Katchapakirin et al., 2018, Eldin et al., 2019; Priya Sri et al., 2021), otros usan textos en su lengua materna traducidos al inglés (López Úbeda et al., 2019; Mehedy et al., 2021; Chatrinan et al., 2021), y en otros, este dato no se indicaban específicamente en los estudios (Wang et al., 2020; Ricard & Hassanpour, 2021; Sabina et al., 2021; Ragheb et al., 2021) (Figura 4).
3.2 Áreas del conocimiento de las publicaciones y redes sociales utilizadas en los estudios
Referente a las áreas del conocimiento y/o temáticas de las publicaciones, se identifica el predominio de revistas relacionadas con Ciencias aplicadas, ingeniería y tecnología, seguida por Psicología, comportamiento humano y salud mental (Figura 5).
3.3 Red social, tipo de dato, alteración de salud mental y algoritmos

En lo que tiene que ver con las redes sociales más utilizadas en los estudios, y que permitieron la recopilación de datos para su posterior análisis, en su orden correspondieron a, Twitter (48,4 %), Reddit (25,8 %) y Facebook (12,9%) (Figura 6).
El tipo de dato analizado en el 100% de los estudios corresponde a textos, sin embargo, el 6,3% de los estudios revisados incluyó, de forma adicional, análisis de imágenes como fotografías, emoticones o ilustraciones.
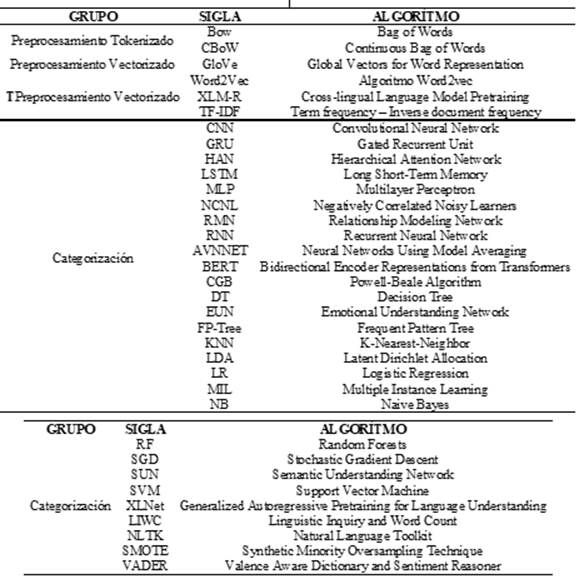
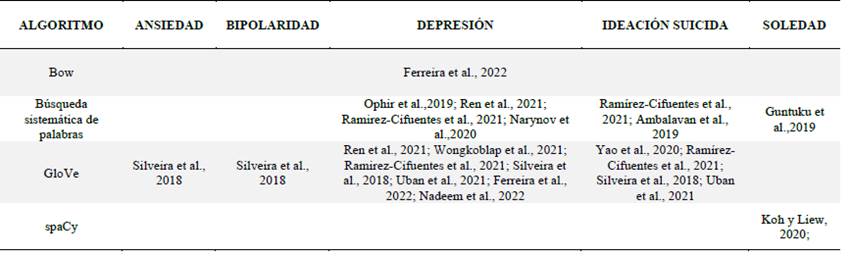
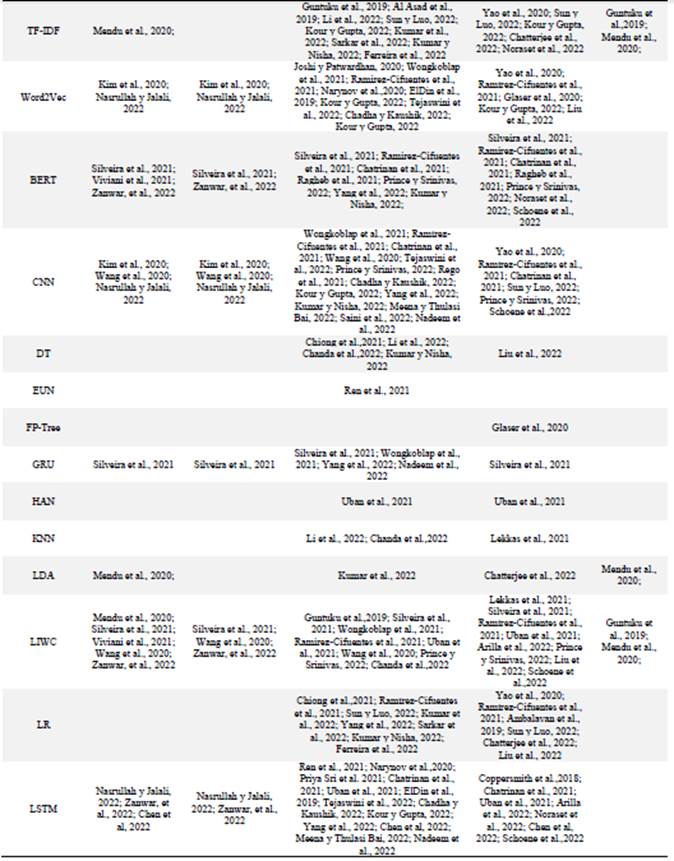
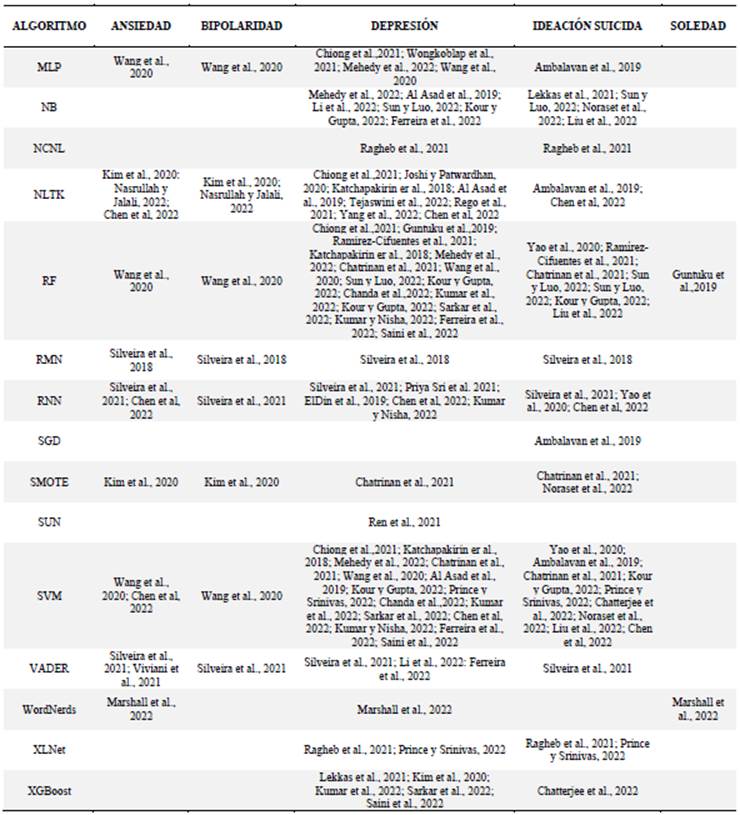
Respecto a las tecnologías implementadas para el NLP, se observó un uso frecuente de algoritmos de machine learning, deep learning y softwares o librerías diseñadas para el análisis del lenguaje natural; entre los más frecuentemente implementados destacan para la etapa de preprocesamiento el Word2Vec con el 25% de los estudios, TF-IDF (25%) y el GloVe (18%), para la etapa de clasificación el LIWC (39%), CNN (32%), LSTM (33%), RF (32%), SVM (31%). Es conveniente señalar que muchos estudios planteaban su modelo con más de un algoritmo en sus metodologías de análisis (Figura 6).
El uso de distintos algoritmos para el NLP configura el modelo implementado en los análisis de las alteraciones de salud mental, en donde a su vez, destacan las unidades de análisis, comprendidas por las redes sociales contempladas en el estudio como fuente de información, la forma de extracción de la data (Figura 6), siendo en muchos casos grupales (71,6%) a través de un foro temático, corpus preexistentes o un hashtag y/o individuales (28,4%), de lo cual se consiguió la información publicada por usuarios específicos (Tabla 2).
3.4 Fenómenos de Salud mental estudiados en las investigaciones
Finalmente, en lo que corresponde a los fenómenos psicológicos, se identificó un notable interés, por parte de los estudios, en las alteraciones de salud mental relacionadas con factores emocionales (Figura 6), siendo la Depresión (33,9%), la Ideación Suicida (16,1%) y la Ansiedad (9,8%), las temáticas que con mayor frecuencia son reportadas como objeto de análisis en los estudios seleccionadas. Cabe mencionar que, fenómenos como Estrés (4,5%), la Bipolaridad (3,6%), la Soledad (3,6%) los Desórdenes Alimenticios (3,6%) y el Cyberbullying (3,6%), son temáticas que han venido posicionándose como fenómenos de interés y pueden resultar mucho más interesantes en el desarrollo de estudios posteriores (Figura 6).
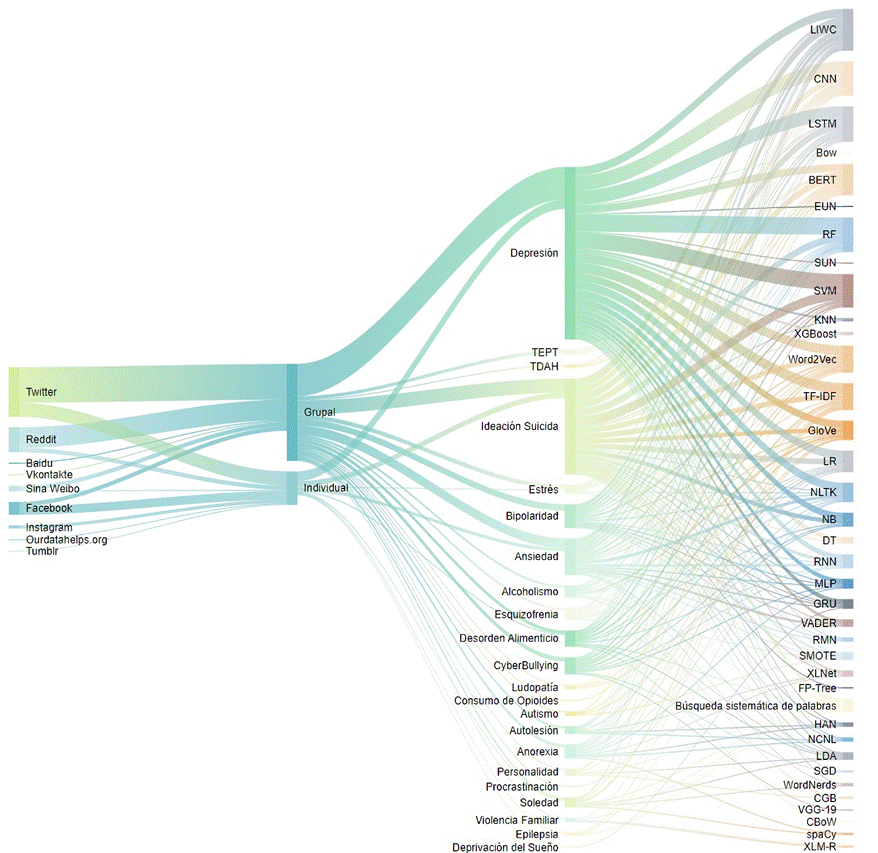
Figura 6 Frecuencia en la red social, tipo de dato, alteración de salud mental y algoritmos implementados en los documentos analizados
4. DISCUSIÓN DE RESULTADOS
De acuerdo con los resultados obtenidos en la revisión, en primer lugar, se destaca el número de publicaciones sobre procesamiento del lenguaje natural para el análisis de fenómenos de salud mental a partir de datos en redes sociales
durante de los años de observación, siendo los años 2022 y 2021, los de mayor producción científica sobre el tema. Dicho aumento en los últimos dos años se atribuye como producto de la pandemia de Covid-19 y pos pandemia, no sólo porque algunos estudios indagaban sobre afectaciones emocionales por el Covid a través de redes sociales (Babvey et al. 2021), sino que, ante la dificultad de realizar estudios de forma presencial, se dio prioridad al análisis del comportamiento por medios digitales como redes sociales, ya que esto no implicaba un contacto directo con los participantes (Hlatshwako et al., 2021).
Por su parte, en lo referente al idioma de publicación, todos los documentos consultados fueron publicados originalmente en inglés, a pesar que los orígenes de las investigaciones fueron de países no angloparlantes como Alemania (Fazekas et al., 2021), Francia (Ambalavan et al., 2019), Italia (Viviani et al., 2021) o España (Sabina et al., 2021; Ardila et al., 2022) en Europa; Bangladesh (Mehedy et al., 2021), China (Li et al, 2021; Sun & Luo, 2022), Corea del sur (Kim et al., 2020), India (Joshi & Patwardhan, 2020; Kour & Gupta, 2022; Tejaswini et al., 2022), Israel (Ophir et al., 2019), Japón (Mori & Haruno, 2021), Kazajistán (Narynov et al., 2020), Malasia (Priya et al., 2021), Singapur (Koh & Liew, 2020), Siri Lanka (Perera, & Fernando, 2021) y Tailandia (Katchapakirin et al., 2018) en Asia; Brasil (Silverira et al., 2021) en Latinoamérica o Egipto (ElDin et al., 2019) en África.
De esta manera, la mayoría de los estudios realizaron sus análisis sobre textos en inglés, siendo algunos de ellos extraídos en su idioma original y luego traducidos al inglés para el análisis (Chatrinan et al., 2021; ElDin et al., 2019; Katchapakirin et al., 2018; López et al., 2019; Narynov et al 2020; Priya Sri et al., 2021). Todo ello se debe a que, gran parte de las tecnologías para el análisis del lenguaje natural fue desarrollada para la interpretación de textos en inglés como, por ejemplo, el Word2Vec, BoW o el NLTK, por lo cual muchas de estas herramientas no están adaptadas a las particularidades de otros idiomas (Chatrinan et al, 2021).
En cuanto a las temáticas de las publicaciones, se identificó que, la ciencia aplicada, la ingeniería y la tecnología, son el interés principal de las revistas que publicaron los documentos seleccionados, aunque también, con menor frecuencia, se encontraron las revistas con temática de psicología, comportamiento humano y salud mental, campos que deberían resultar más notables, tomando en cuenta que la salud mental es tópico fundamental en su área de estudio. Este fenómeno puede atribuirse al conocimiento especializado que se requiere para la extracción, la depuración y el procesamiento del lenguaje natural de los datos, tareas mucho más cotidianas en las ciencias informáticas que en las ciencias sociales y de la salud, donde pueden parecer distantes, poco frecuentes o desconocidas (Urban & Gates, 2021).
En lo referente a las fuentes de información en los estudios analizados, se identifica que las redes sociales más usadas fueron Twitter y Reddit, seguida de Facebook, cuyo resultado es similar al obtenido por Zhang et al. (2022), quienes consideran que estas redes sociales, además de ser de las más estudiadas y populares (Harrigian et al., 2020), se caracterizan por la predominancia de textos, organizando la información a través de palabras clave, hashtags, hilos, etc. (Ricard & Hassanpour, 2021). Adicionalmente, Twitter permite la recopilación de información por medio de su API (Interfaz de programación de aplicaciones) y Reddit organiza las temáticas por medio de foros denominados subreddits, lo que facilita la extracción de los datos relevantes para cada investigación, tarea mucho más compleja en redes sociales con predominancia audiovisual como Facebook, Instagram o Tumblr, las cuales son infrautilizadas en investigaciones de salud mental (Harrigian et al., 2020).
Los fenómenos de salud mental abordados en los documentos seleccionados evidencian un especial interés por las alteraciones emocionales, siendo la depresión, la ideación suicida y la ansiedad, las temáticas con mayor frecuencia en las investigaciones, y cuyo resultado es coherente con el estudio realizado por Chancellor & De Choudhury (2020), en donde la depresión y el suicidio también resultan ser los fenómenos más recurrentes en su análisis. Así mismo, las alteraciones emocionales presentan una alta prevalencia en la población mundial, de acuerdo al informe de la OMS (2017) y cuya situación se vio exacerbada en el periodo de confinamiento y distanciamiento social por Covid-19, lapso en el cual se reporta una mayor prevalencia de sintomatología depresiva, ansiedad, comportamiento suicida, entre otras alteraciones de salud mental en la población a nivel global (Huarcaya-Victoria, 2020; Kumar & Nayar, 2021; Mac-Ginty et al., 2021).
Respecto al procesamiento de los datos, se identifican dos grupos de algoritmos fundamentales para el NLP; en primer lugar los de ordenamiento, en donde se limpia la data eliminando la información irrelevante como los emoticones o signos de puntuación, se tokeniza la data, se divide el contenido en palabras individuales y se convierte (“No, es triste”) en un arreglo ["No", ",", "es", "triste"] y se vectoriza, proceso en el que se convierten los tokens en vectores numéricos comprensibles para los algoritmos de aprendizaje automático, modelos que generalmente requieren datos de entrada numérica. Entre los más frecuentemente usados se detectaron el TF-IDF, Word2Vec, GloVe.
En segundo lugar, entre los algoritmos de clasificación usados para la identificación de alteraciones psicológicas, en los documentos revisados, se identifica el SVM, RF, CNN, LIWC y el LSTM, siendo este último el que mayor precisión evidenció en el análisis de las alteraciones emocionales como la depresión y la ideación suicida (Zhang et al., 2017; ElDin et al., 2019; Ren et al., 2021; Chadha & Kaushik, 2022; Kour & Gupta, 2022; Yang et al., 2022). Por su parte Gong et al. (2018), indica que el uso de LIWC puede superar la dificultad de obtener datos a gran escala en el campo de la salud, esto es especialmente relevante en el entrenamiento de modelos de Deep Learning, ya que un diccionario creado por humanos puede proporcionar una alternativa efectiva y concisa al aprendizaje automático para convertir texto en representaciones vectoriales.
A pesar de las grandes ventajas que el análisis de textos de redes sociales para la identificación de alteraciones psicológicas a través de NLP representa, es importante ejercer prudencia en su uso y destacar la necesidad de contar con el acompañamiento de profesionales en salud mental para un diagnóstico adecuado (Calvo et al., 2017). Si bien esta herramienta puede ser útil para la detección temprana de alteraciones psicológicas como lo promueve el proyecto eRisk (Crestani et al., 2022), se debe tener en cuenta que los datos analizados pueden estar sujetos a sesgos, por ejemplo, al considerar variables de personalidad como la "triada oscura", que con frecuencia tiene una presencia más activa en las redes sociales (Preotiuc-Pietro et al., 2016), lo que puede generar una mayor representación en los datos recolectados. Así mismo, el exacerbar el control de la información digital para mantener la privacidad, debe ser un compromiso implícito establecido en los estudios, ya que estos pueden ser utilizados para ser analizados y comercializados en mercados secundarios, generando preocupaciones sobre las implicaciones éticas del uso de datos públicos, la calidad de estos, las consecuencias de una mala interpretación y la vulneración de la privacidad (Bauer et al., 2017).
Particularmente en los aspectos éticos, Wongkoblap et al. (2017) en su estudio, destacan la inexistencia de una ruta clara en el uso de la data pública proveniente de redes sociales, ya que, se evidencian prácticas adoptadas de forma autónoma en cada estudio, que varían de un investigador a otro, lo que resulta similar a lo encontrado en la presente investigación, en donde pocas publicaciones, principalmente aquellas que analizaron los datos de usuarios individuales, contaron algunas con avales éticos (Fazekas et al., 2021; Guntuku et al., 2019; Katchapakirin et al., 2018; Kim et al., 2020; Mori & Haruno, 2021; Ambalavan et al., 2019; Ramírez-Cifuentes et al., 2021; Schoene et al., 2022; Wongkoblap et al., 2021), mientras que la gran mayoría, interesados en el análisis de forma grupal, no detallan ninguna consideración ética en sus estudios.
Lo anterior, conduce a reflexionar acerca de la importancia de tener en cuenta, para este tipo de investigaciones, aspectos como, las fuentes de sesgo, las implicaciones éticas, y el acompañamiento de profesional del área de la salud, en el análisis automatizado, y obtener con ello, una comprensión completa, adecuada y responsable del fenómeno.
5. CONCLUSIONES
El interés de esta investigación se encaminó hacia la detección de modelos de lenguaje natural para la identificación de alteraciones mentales en redes sociales. Dicha detección precoz de síntomas de trastornos mentales es una estrategia importante y eficaz para otorgar datos que aportan al diagnóstico de la salud mental en la población., a partir de los hallazgos se puede concluir que:
Existe un aumento significativo en la cantidad de publicaciones sobre el procesamiento del lenguaje natural para el análisis de fenómenos de salud mental en datos de redes sociales, especialmente en los años 2021 y 2022 durante la pandemia de COVID-19.
La mayoría de los estudios consultados fueron publicados originalmente en inglés, a pesar de que las investigaciones se realizaron en diversos países no angloparlantes de Europa, Asia, Latinoamérica, Oceanía y África.
Las revistas con temáticas de ciencia aplicada, ingeniería y tecnología, son las que predominan en la publicación de los documentos, en comparación con las revistas especializadas en psicología, comportamiento humano y salud mental.
Las redes sociales más utilizadas para la recopilación de datos en los estudios son Twitter y Reddit, debido a su predominancia de texto y facilidad para la extracción de información relevante. En contraste, redes sociales audiovisuales como Facebook, Instagram y Tumblr, son menos utilizadas en investigaciones de salud mental. Así mismo, la extracción de datos de forma grupal es el común denominador de los estudios.
Los trastornos emocionales como la depresión, la ideación suicida y la ansiedad, son los temas más frecuentemente abordados en los estudios consultados, lo cual es coherente con la alta prevalencia de estos trastornos a nivel mundial, especialmente durante la pandemia de COVID-19.
En cuanto al procesamiento de datos, se identifican dos grupos principales de algoritmos utilizados en el procesamiento del lenguaje natural: los algoritmos de ordenamiento para limpiar y preparar los datos, y los algoritmos de clasificación, siendo los algoritmos SVM, RF, CNN, LIWC y LSTM los más usados, para la identificación de alteraciones psicológicas. Cabe mencionar que los modelos propuestos por los estudios contemplan una combinación de ellos y de forma general todos reportaban efectividades elevadas.
En el futuro, el desarrollo de nuevos métodos que incluyan diferentes estrategias de aprendizaje, nuevos paradigmas de procesamiento de lenguaje natural, modelos y métodos multimodales, validados y aplicados en distintos contextos, apoyarán la detección de enfermedades mentales con un énfasis en la interpretabilidad, lo que resulta crucial para la aceptación de las aplicaciones de detección por parte de profesionales de la salud.
Así mismo, es importante destacar algunas preocupaciones sobre el componente ético implementado en estos estudios, dado que no se identificó una regulación clara sobre la recopilación y el manejo de datos, sino más bien, una serie heterogénea de estrategias adelantadas por iniciativa de los mismos autores. Esto genera interrogantes sobre las consecuencias que esta información pueda tener en contextos sanitarios, políticos y sociales, llevando a sugerir, para futuras investigaciones, con similares características, la consulta de publicaciones como la de Arigo et al. (2018) quien propone algunas directrices éticas relevantes para el desarrollo de estos estudios.
Como limitaciones en este estudio, se destaca que la selección de artículos se llevó a cabo a través de unas bases de datos, dejando de lado algunas otras que bien pueden brindar información complementaria. Sólo se seleccionaron los artículos relacionados con los datos extraídos de redes sociales, y aquellos que utilizan NLP para la detección de alteraciones en salud mental.
Los retos que deja esta investigación podrán abordarse en investigaciones futuras sobre la detección de problemas de salud mental. Aspectos como, los modelos, ubicaciones de los estudios, el idioma, la diversidad de fuentes de datos, el tipo de extracción de datos, no sólo de textos, sino también, imágenes, audios y videos, se convertirán en áreas potenciales de exploración, ya que, como bien se ha revelado en este estudio, la utilización de algoritmos o híbridos para la detección de enfermedades mentales o emocionales, se podrán convertir en fuentes de información que aporten a la formulación de alternativas de prevención, promoción y control, en políticas públicas.
Por último, se debe manifestar que la presente investigación ofrece información sobre una serie de herramientas de aprendizaje automático que emplean muchas de las técnicas de NLP, capaces de ofrecer a las instituciones u organizaciones de salud competentes una ayuda sistemática en el rastreo de la actividad de los usuarios en las redes sociales. Se destaca las herramientas acá expuestas, las cuales demuestran la capacidad de generar alertas tempranas ante evidencia de padecimientos asociados a algún tipo de trastorno mental, aspecto que potencia una intervención anticipada y oportuna, además de dar cabida al desarrollo de alternativas en el tratamiento temprano de trastornos psicológicos.
Los resultados son prometedores y arrojan luz sobre muchas aplicaciones en el mundo real para la detección precoz de alteraciones mentales a partir de los datos de las redes sociales.




